基于YOLOv8深度学习的人脸面部表情识别系统【python源码+Pyqt5界面+数据集+训练代码】深度学习实战
《博主简介》
小伙伴们好,我是阿旭。专注于人工智能、AIGC、python、计算机视觉相关分享研究。
?更多学习资源,可关注公-仲-hao:【阿旭算法与机器学习】,共同学习交流~
👍感谢小伙伴们点赞、关注!
《------往期经典推荐------》
二、机器学习实战专栏【链接】,已更新31期,欢迎关注,持续更新中~~
三、深度学习【Pytorch】专栏【链接】
四、【Stable Diffusion绘画系列】专栏【链接】
《------正文------》
基本功能演示

摘要:
人脸面部表情识别在多个领域中都扮演着重要的角色,通过解读人的情绪反应,增强机器与人之间的交互体验。本文基于YOLOv8深度学习框架,通过28079张图片,训练了一个进行人脸面部表情识别的检测模型,可用于检测7种不同的人物表情。并基于此模型开发了一款带UI界面的人脸面部表情识别系统,可用于实时检测场景中的人物面部表情,更方便进行功能的展示。该系统是基于python与PyQT5开发的,支持图片、视频以及摄像头进行目标检测,并保存检测结果。本文提供了完整的Python代码和使用教程,给感兴趣的小伙伴参考学习,完整的代码资源文件获取方式见文末。
文章目录
前言
人脸面部表情识别在多个领域中都扮演着重要的角色,通过解读人的情绪反应,增强机器与人之间的交互体验。
在人机交互中,面部表情系统可以使计算机更加智能化,能够理解和响应用户的情感状态,从而提供更加个性化和富有同理心的服务。例如,在教育领域,该技术能够识别学生的情绪变化,帮助教师调整教学方式以提高学生的学习效率;在心理健康领域,它可以作为情绪监测工具,帮助医生评估患者情绪状态,辅助诊断和治疗;在自动驾驶系统中,通过监测驾驶员的表情和状态,可以有效预防疲劳或注意力不集中驾驶带来的风险。
此外,人脸面部表情识别技术在市场研究和用户体验设计中也极为有用,能够识别消费者在看到某个产品或广告时的真实情绪反应,从而帮助企业更好地了解消费者需求,优化产品设计和营销策略。在智能家居和安全监控系统中,结合情绪识别可以提供更加人性化的服务,如根据用户的情绪状态调整室内的灯光、音乐等环境设置,或是及时警觉异常情绪状态来预防潜在风险。除此之外,面部表情识别技术还广泛应用于娱乐产业,如视频游戏和虚拟现实中,以提供更加沉浸和互动的用户体验。
综上所述,人脸面部表情识别技术开启了新一代人机交互的大门,它的应用场景广泛,从提高商业价值到增进人类福祉,这项技术的发展极具潜力并正在逐渐改变我们的生活与工作方式。
博主通过搜集不同种类的人脸表情的相关数据图片,根据YOLOv8的目标检测技术,基于python与Pyqt5开发了一款界面简洁的人脸面部表情识别系统,可支持图片、视频以及摄像头检测,同时可以将图片或者视频检测结果进行保存。
软件初始界面如下图所示:

检测结果界面如下:

一、软件核心功能介绍及效果演示
软件主要功能
1. 可进行7种不同人物表情识别,表情分别为:['生气','厌恶','害怕','高兴','中立','伤心','惊讶'];
2. 支持图片、视频及摄像头进行人脸表情检测;
3. 界面可实时显示表情结果、置信度、各表情概率值等信息;
(1)图片检测演示
点击打开图片图标,选择需要检测的图片,会显示检测结果,同时会将7种表情的概率值显示在右方。操作演示如下:点击目标下拉框后,可以选定指定目标的结果信息进行显示。
注:1.右侧目标默认显示置信度最大一个目标。
单个图片检测操作如下:

(2)视频检测演示
点击打开视频按钮,打开选择需要检测的视频,就会自动显示检测结果。

(3)摄像头检测演示
点击打开摄像头按钮,可以打开摄像头,可以实时进行检测,再次点击摄像头按钮,可关闭摄像头。

二、模型的训练、评估与推理
1.YOLOv8的基本原理
YOLOv8是一种前沿的目标检测技术,它基于先前YOLO版本在目标检测任务上的成功,进一步提升了性能和灵活性。主要的创新点包括一个新的骨干网络、一个新的 Ancher-Free 检测头和一个新的损失函数,可以在从 CPU 到 GPU 的各种硬件平台上运行。
其主要网络结构如下:

本文的人脸表情识别,主要分为两步。第一步:检测人脸位置;第二步:将人脸位置截取出来,作为输入传入到使用YOLOv8训练的表情分类模型,从而得到表情识别的结果。
第一步:人脸位置检测
关于人脸位置检测的方法有很多,比如:opencv的dilb库,face_recognition,insightface,mediapipe,deepface等都可以进行人脸位置检测。因为本文主要是对人脸面部表情进行识别,重点实现的是第二部分的表情识别部分。因此对于第一步,本文直接使用的是通过yolov8官方训练好的人脸检测模型yolov8n-face.pt,来进行人脸位置检测,该模型是通过人脸目标数据集训练而来,精度较高。
具体使用方法如下:
#coding:utf-8
from ultralytics import YOLO
import cv2
if __name__ == '__main__':
# 所需加载的模型目录
path = 'models/yolov8n-face.pt'
# 需要检测的图片地址
img_path = "TestFiles/test3.jpg"
model = YOLO(path, task='detect')
# 检测图片
results = model(img_path,conf=0.5)
res = results[0].boxes.xyxy.tolist()
print(res)
img = cv2.imread(img_path)
for each in res:
# 开始的y坐标:结束的y坐标,开始x:结束的x
x1,y1,x2,y2 = each[:4]
x1 = int(x1)
y1 = int(y1)
x2 = int(x2)
y2 = int(y2)
cv2.rectangle(img, (x1, y1), (x2, y2), (50, 50, 250), 3)
cv2.imshow('face_detection', img)
cv2.waitKey(0)

以上结果可以发现,该模型能够很好的检测人脸位置。下面我们需要使用yolov8训练一个表情识别的模型,对于检测到的人脸进行表情的识别判断。
第二步:人脸表情识别
1. 数据集准备与训练
本文使用的数据集为人脸面部表情分类数据集,包含7种不同的人脸表情,分别是:['生气','厌恶','害怕','高兴','中立','伤心','惊讶']。一共包含35257张图片,其中训练集包含28079张图片,测试集包含7178张图片。部分数据集及类别信息如下。下面我们将使用该数据集训练一个表情分类模型,用于对截取后的人脸部分进行表情分类,从而达到进行表情识别的目的。


图片数据集的存放格式如下,在项目目录中新建datasets目录,同时将分类的图片分为训练集与验证集放入ExpressionData目录下。

2.模型训练
数据准备完成后,通过调用train.py文件进行模型训练,epochs参数用于调整训练的轮数,batch参数用于调整训练的批次大小【根据内存大小调整,最小为1】,代码如下:
#coding:utf-8
from ultralytics import YOLO
# 加载预训练模型
model = YOLO("yolov8n-cls.pt")
if __name__ == '__main__':
model.train(data='datasets/ExpressionData', epochs=300, batch=4)
# results = model.val()
# # results = model("自己的验证图片")
3. 训练结果评估
在深度学习中,我们通常用损失函数下降的曲线来观察模型训练的情况。YOLOv8在训练结束后,可以在runs/目录下找到训练过程及结果文件,如下所示:

本文训练结果如下:

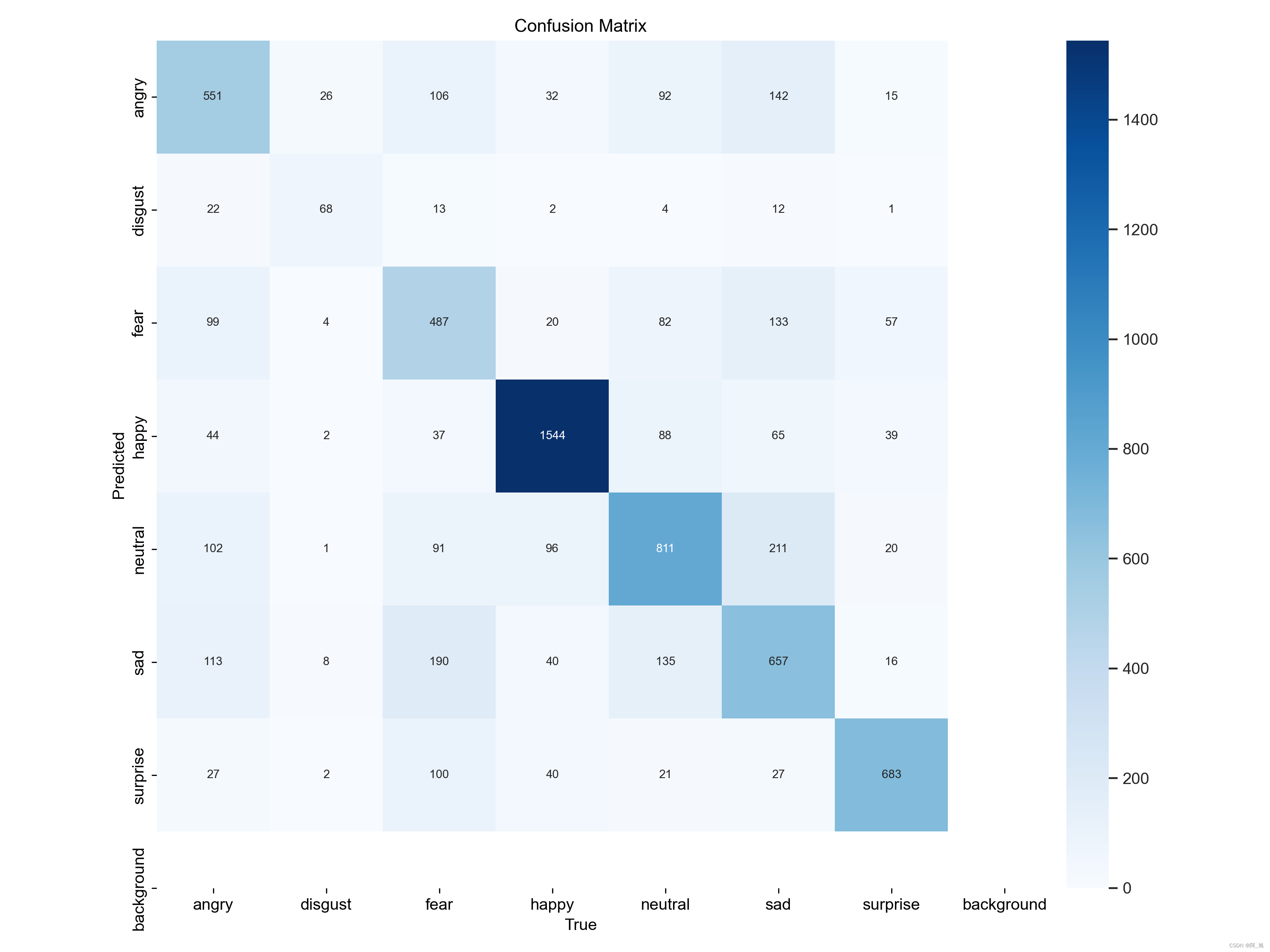
4. 利用模型进行表情识别
模型训练完成后,我们可以得到一个最佳的训练结果模型best.pt文件,在runs/trian/weights目录下。我们可以使用该文件进行后续的推理检测。
图片检测代码如下:
#coding:utf-8
from ultralytics import YOLO
import cv2
import Config
import detect_tools as tools
import numpy as np
if __name__ == '__main__':
img_path = 'TestFiles/12.png'
# 所需加载的模型目录
face_model_path = 'models/yolov8n-face.pt'
expression_model_path = 'models/expression_cls.pt'
# 人脸检测模型
face_model = YOLO(face_model_path, task='detect')
# 表情识别模型
expression_model = YOLO(expression_model_path, task='classify')
cv_img = tools.img_cvread(img_path)
face_cvimg, faces, locations = face_detect(cv_img, face_model)
if faces is not None:
for i in range(len(faces)):
left, top, right, bottom = locations[i]
# 彩色图片变灰度图
img = cv2.cvtColor(faces[i], cv2.COLOR_BGR2GRAY)
# 灰度图变3通道
img = cv2.cvtColor(img, cv2.COLOR_GRAY2RGB)
rec_res = expression_model(img)
probs = rec_res[0].probs.data.tolist()
num = np.argmax(probs)
label = Config.names[num]
face_cvimg = cv2.putText(face_cvimg, label, ((left, top - 10)), cv2.FONT_HERSHEY_SIMPLEX, 0.75, (0, 0, 250),
2, cv2.LINE_AA)
cv2.imshow('yolov8_detections',face_cvimg)
cv2.waitKey(0)
执行上述代码后,会将执行的结果直接标注在图片上,结果如下:

以上便是关于此款人脸面部表情识别系统的原理与代码介绍。基于此模型,博主用python与Pyqt5开发了一个带界面的软件系统,即文中第二部分的演示内容,能够很好的支持图片、视频及摄像头进行检测。
关于该系统涉及到的完整源码、UI界面代码、数据集、训练代码、测试图片视频等相关文件,均已打包上传,感兴趣的小伙伴可以通过下载链接自行获取。
【获取方式】
本文涉及到的完整全部程序文件:包括python源码、数据集、训练代码、UI文件、测试图片视频等(见下图),获取方式见文末:

注意:该代码基于Python3.9开发,运行界面的主程序为
MainProgram.py,其他测试脚本说明见上图。为确保程序顺利运行,请按照程序运行说明文档txt配置软件运行所需环境。
结束语
以上便是博主开发的基于YOLOv8深度学习的人脸面部表情识别系统的全部内容,由于博主能力有限,难免有疏漏之处,希望小伙伴能批评指正。
关于本篇文章大家有任何建议或意见,欢迎在评论区留言交流!
觉得不错的小伙伴,感谢点赞、关注加收藏哦!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!