Linux多线程:线程池(单例),读写锁
目录
一、线程池(单例模式)
1.1 makefile
thread_pool:main.cc
g++ -o $@ $^ -std=c++11 -lpthread
.PHONY:clean
clean:
rm -f thread_pool
1.2 LockGuard.hpp
#include <pthread.h>
class Mtx
{
public:
Mtx(pthread_mutex_t* mtx)
:_mtx(mtx)
{}
~Mtx()
{}
void Lock()
{
pthread_mutex_lock(_mtx);
}
void Unlock()
{
pthread_mutex_unlock(_mtx);
}
private:
pthread_mutex_t* _mtx;
};
//RAII风格的锁
//创建这个对象就是上锁,析构这个对象就是解锁
class LockGuard
{
public:
LockGuard(pthread_mutex_t* mtx)
:_mtx(mtx)//单参数的构造函数支持隐式类型的转换
{
_mtx.Lock();
}
~LockGuard()
{
_mtx.Unlock();
}
private:
Mtx _mtx;
};
1.3 log.hpp
#pragma once
#include <iostream>
using namespace std;
#include <string>
#include <stdarg.h>
// 日志是有日志级别的
#define DEBUG 0
#define NORMAL 1
#define WARNING 2
#define ERROR 3
#define FATAL 4
#define LOGFILE "./threadpool.log"
const char* logLevel[]={"DEBUG","NORMAL","WARNING","ERROR","FATAL"};
//在写日志的时候需要互斥地写,即一条日志写完,另一条日志再写
pthread_mutex_t lock=PTHREAD_MUTEX_INITIALIZER;
//参数为一个日志等级和一个可变参数列表
void logMessage(int level,const char* format,...)
{
//日志的标准部分
char stdBuff[1024]={0};
//time_t是一个时间戳类型,time_t类型是long int经过typedef得到的
time_t timestamp=time(nullptr);
// struct tm {
// int tm_sec; /* seconds */
// int tm_min; /* minutes */
// int tm_hour; /* hours */
// int tm_mday; /* day of the month */
// int tm_mon; /* month */
// int tm_year; /* year */
// int tm_wday; /* day of the week */
// int tm_yday; /* day in the year */
// int tm_isdst; /* daylight saving time */
// };
//struct tm结构体可以通过man localtime函数查到
struct tm* t=localtime(×tamp);
int year=t->tm_year+1900;
int month=t->tm_mon+1;
int day=t->tm_mday;
int hour=t->tm_hour;
int minute=t->tm_min;
int second=t->tm_sec;
snprintf(stdBuff,sizeof(stdBuff),"[%s] [日志日期:%02d/%02d/%02d 时间:%02d:%02d:%02d]"
,logLevel[level],year,month,day,hour,minute,second);
//日志的自定义部分
char logBuff[1024]={0};
//处理可变参数的变量
va_list args;
//等于初始化可变参数变量,相当于把format指针赋值给args
va_start(args,format);
//把format可变参数列表中的参数一个一个地格式化到logBuff缓冲区中
vsnprintf(logBuff,sizeof(logBuff),format,args);
//置空
va_end(args);
//打印日志的时候需要保证串行打印,互不干扰的,所以需要加锁,
//向文件中打印日志
pthread_mutex_lock(&lock);
FILE* fp=fopen(LOGFILE,"a");
fprintf(fp,"%s%s",stdBuff,logBuff);
fclose(fp);
pthread_mutex_unlock(&lock);
// cout<<stdBuff<<logBuff;
}
1.4 Task.hpp
#pragma once
#include <cstdio>
typedef int(*callback_t)(int,int);
class Task
{
public:
Task()
{}
Task(int x,int y,char op,callback_t cb)
: _x(x)
, _y(y)
,_op(op)
,_cb(cb)
{}
void operator()()
{
printf("%d %c %d = %d\n",_x,_op,_y,_cb(_x,_y));
}
public:
int _x;
int _y;
char _op;
callback_t _cb;
};
1.5 Thread.hpp
#pragma once
#include <iostream>
using namespace std;
#include <pthread.h>
#include <string>
//Thread结构体里面要封装一个线程自己的执行函数,参数为
//void*,返回值也为void*
typedef void *(*func_t)(void *);
//线程结构体的数据,这个数据要作为参数传给线程执行的函数
class ThreadData
{
public:
ThreadData(int num,void* args)
: _num(num)
,_args(args)
{
_name = "thread-" + to_string(num);
}
public:
string _name;
int _num;
void* _args;//这个是线程池对象自己的this指针,在routinue函数中会具体解释
};
class Thread
{
public:
//构造函数,需要把线程的编号,线程的执行函数,以及线程池自己的this指针传过来
Thread(int num, func_t callback, void *args)
: _num(num),_func(callback), _args(args),_tdata(_num,_args)
{
}
//start才是真正地创建线程
void start()
{
pthread_create(&_tid, nullptr, _func, &_tdata);
}
//释放线程
void join()
{
pthread_join(_tid,nullptr);
}
pthread_t Tid()
{
return _tid;
}
private:
pthread_t _tid;//线程tid
int _num;//线程的代号
func_t _func;//线程的执行函数
void *_args;//this指针
ThreadData _tdata;//线程的数据
};
1.6 ThreadPool.hpp
#pragma once
#include <iostream>
using namespace std;
#include <vector>
#include "Thread.hpp"
#include <queue>
#include "LockGuard.hpp"
#include "log.hpp"
/*threadpool.h*/
/* 线程池:
* 一种线程使用模式。线程过多会带来调度开销,进而影响缓存局部性和整体性能。
而线程池维护着多个线程,等待着监督管理者分配可并发执行的任务。这避免了在
处理短时间任务时创建与销毁线程的代价。线程池不仅能够保证内核的充分利用,
还能防止过分调度。可用线程数量应该取决于可用的并发处理器、处理器内核、内存、
网络sockets等的数量。
* 线程池的应用场景:
* 1. 需要大量的线程来完成任务,且完成任务的时间比较短。 WEB服务器完成网页
请求这样的任务,使用线程池技术是非常合适的。因为单个任务小,而任务数量巨大,
你可以想象一个热门网站的点击次数。 但对于长时间的任务,比如一个Telnet连接请
求,线程池的优点就不明显了。因为Telnet会话时间比线程的创建时间大多了。
* 2. 对性能要求苛刻的应用,比如要求服务器迅速响应客户请求。
* 3. 接受突发性的大量请求,但不至于使服务器因此产生大量线程的应用。突发性大
量客户请求,在没有线程池情况下,将产生大量线程,虽然理论上大部分操作系统线程
数目最大值不是问题,短时间内产生大量线程可能使内存到达极限,出现错误.
* 线程池的种类:
* 线程池示例:
* 1. 创建固定数量线程池,循环从任务队列中获取任务对象,
* 2. 获取到任务对象后,执行任务对象中的任务接口
*/
static const int g_default_num = 3;
template <class T>
class ThreadPool
{
private:
// 获取锁
pthread_mutex_t *getMutex()
{
return &_taskQueue_mtx;
}
// 在条件变量下等待
void waitCond()
{
pthread_cond_wait(&_taskQueue_cond, &_taskQueue_mtx);
}
// 获取任务
T getTask()
{
T t = _task_queue.front();
_task_queue.pop();
return t;
}
public:
// 单例模式:懒汉模式
static ThreadPool<T> *getThreadPool(int num = g_default_num)
{
// 双判断加锁,外层判断是让第一次调用该函数的线程进入创建一个单例对象,
// 内层判断是防止第一次调用函数时有多个线程同时进入,从而导致创建多个
// 对象的情况。所以如果第一次调用该函数,就会有其中一个线程进入判断条件,
// 申请锁,然后创建对象,之后的每一次调用该函数都不会满足第一个判断条件,
// 即不会再申请锁
if (_thread_ptr == nullptr)
{
pthread_mutex_lock(&_thread_ptr_mtx);
if (_thread_ptr == nullptr)
{
_thread_ptr = new ThreadPool<T>(num);
}
pthread_mutex_unlock(&_thread_ptr_mtx);
}
return _thread_ptr;
}
// 线程池里面的线程就充当消费者的角色,不断地从任务队列中获取并处理任务。
// 这里必须加上static修饰,因为线程的函数的参数必须是一个void*的,而成员函数
// 内部是有一个this指针的,所以我们需要加上static
static void *routinue(void *args)
{
// 这个args就是线程结构体的数据,即ThreadData,ThreadData里面有一个最重要的参数
// 就是里面的args,而args就是该线程池ThreadPool的this指针,是在ThreadPool构造函数
// 创建一批Thread指针的时候传递过去的。为什么要花费这么大的精力把this指针传递到这个
// 函数中呢?因为该函数是静态的,我们没有办法在该函数中访问ThreadPool的任何成员函数
// 和成员变量,而我们作为消费者要消费数据就必须访问任务队列等成员函数,所以必须要能
// 访问成员变量和成员函数,所以就绕了一大圈把ThreadPool的this指针传过来,有了this指针
// 就能访问成员函数和成员变量了
ThreadData *td = static_cast<ThreadData *>(args);
ThreadPool<T> *tp = static_cast<ThreadPool<T> *>(td->_args);
// 获取并处理任务
T t;
while (true)
{
//获取任务前要先锁住任务队列,避免出现数据不一致问题
LockGuard lock(tp->getMutex());
//任务队列为空就让线程在条件变量下等待,注意这里要用while循环而不是
//if,因为可能存在伪唤醒,所以唤醒后必须再检查一遍,确认任务队列中有数据再取数据
while (_task_queue.empty())
{
tp->waitCond();
}
// 从任务队列中获取任务
t = tp->getTask();
printf("消费者 [%s:0x%x] 消费了一个数据:", td->_name.c_str(), pthread_self());
// logMessage(NORMAL, " 消费者 [%s:0x%x] 消费了一个数据:", td->_name.c_str(), pthread_self());
//调用仿函数处理任务
t();
}
}
//启动线程池才是真正调用iter->start()创建一堆线程
void run()
{
for (auto &iter : _threads)
{
iter->start();
logMessage(NORMAL, " 线程 [0x%x] 启动成功\n", iter->Tid());
}
}
//向任务队列中塞数据
void PushTask(const T &t)
{
//同理需要先加锁,因为任务队列是所有线程共享的
LockGuard lock(&_taskQueue_mtx);
_task_queue.push(t);
//当我们塞了一个数据进任务队列时证明任务队列中
//有数据了,此时可以唤醒一个线程来处理任务
pthread_cond_signal(&_taskQueue_cond);
}
private:
// 构造函数私有
ThreadPool(int num)
: _num(num)
{
for (int i = 0; i < num; i++)
{
_threads.push_back(new Thread(i + 1, routinue, this));
}
pthread_mutex_init(&_taskQueue_mtx, nullptr);
pthread_cond_init(&_taskQueue_cond, nullptr);
}
// 删除拷贝构造和复制重载函数
ThreadPool(const ThreadPool<T> &) = delete;
const ThreadPool<T> &operator=(const ThreadPool<T> &) = delete;
//析构函数
~ThreadPool()
{
for (auto &iter : _threads)
{
iter->join();
delete iter;
}
pthread_mutex_destroy(&_taskQueue_mtx);
pthread_cond_destroy(&_taskQueue_cond);
}
private:
static ThreadPool<T> *_thread_ptr;//线程池的指针
vector<Thread *> _threads; // 线程池
int _num;//线程池中的线程数
static queue<T> _task_queue;//任务队列
pthread_mutex_t _taskQueue_mtx;//任务队列的锁
pthread_cond_t _taskQueue_cond;//任务队列的条件变量
static pthread_mutex_t _thread_ptr_mtx;//获取线程池对象的锁,保证单例
};
//静态成语类外初始化
template <class T>
queue<T> ThreadPool<T>::_task_queue;
template <class T>
ThreadPool<T> *ThreadPool<T>::_thread_ptr = nullptr;
template <class T>
pthread_mutex_t ThreadPool<T>::_thread_ptr_mtx = PTHREAD_MUTEX_INITIALIZER;
1.7 main.cc
#include <iostream>
using namespace std;
#include "ThreadPool.hpp"
#include <unistd.h>
#include <ctime>
#include "Task.hpp"
// int main()
// {
// srand((unsigned int)time(nullptr));
// ThreadPool<int>* tp=new ThreadPool<int>(5);
// tp->run();
// while(true)
// {
// int x=rand()%100+1;
// //int y=rand()%100+1;
// // Task t(x,y,[](int x,int y)
// // {
// // return x+y;
// // });
// tp->PushTask(x);
// printf("生产者 [0x%x] 生产了一个数据:%d\n",pthread_self(),x);
// usleep(100000);
// }
// return 0;
// }
#include "log.hpp"
// 线程池的本质也是生产者消费者模型
char oper[] = "+-*/%";
int main()
{
srand((unsigned int)time(nullptr));
// 创建一个线程池
ThreadPool<Task> *tp = ThreadPool<Task>::getThreadPool();
// 启动线程池
tp->run();
while (true)
{
// 主线程充当一个生产者的角色,不断地生产任务数据
int x = rand() % 100 + 1;
int y = rand() % 100 + 1;
char op = oper[rand() % 5];
Task t;
switch (op)
{
case '+':
{
t = Task(x, y, '+', [](int x, int y)
{ return x + y; });
break;
}
case '-':
{
t = Task(x, y, '-', [](int x, int y)
{ return x - y; });
break;
}
case '*':
{
t = Task(x, y, '*', [](int x, int y)
{ return x * y; });
break;
}
case '/':
{
t = Task(x, y, '/', [](int x, int y)
{ return x / y; });
break;
}
case '%':
{
t = Task(x, y, '%', [](int x, int y)
{ return x % y; });
break;
}
}
// 向任务队列中塞数据
tp->PushTask(t);
// printf("生产者 [0x%x] 生产了一个数据:%d + %d = ?\n",pthread_self(),x,y);
// 打印日志
logMessage(NORMAL, " 生产者 [0x%x] 生产了一个数据:%d %c %d = ?\n", pthread_self(), x, op, y);
sleep(1);
}
return 0;
}
二、STL,智能指针和线程安全
2.1 STL中的容器是否是线程安全的?
不是。
原因是:STL 的设计初衷是将性能挖掘到极致, 而一旦涉及到加锁保证线程安全, 会对性能造成巨大的影响。而且对于不同的容器, 加锁方式的不同, 性能可能也不同(例如hash表的锁表和锁桶)。
因此 STL 默认不是线程安全. 如果需要在多线程环境下使用, 往往需要调用者自己保证线程安全。
2.2 智能指针是否是线程安全的?
对于 unique_ptr, 由于只是在当前代码块范围内生效, 因此不涉及线程安全问题。对于 shared_ptr, 多个对象需要共用一个引用计数变量, 所以会存在线程安全问题. 但是标准库实现的时候考虑到了这个问题, 基于原子操作(CAS)的方式保证 shared_ptr 能够高效, 原子的操作引用计数。
三、其他常见的各种锁
悲观锁:在每次取数据时,总是担心数据会被其他线程修改,所以会在取数据前先加锁(读锁,写锁,行锁等),当其他线程想要访问数据时,被阻塞挂起。
乐观锁:每次取数据时候,总是乐观的认为数据不会被其他线程修改,因此不上锁。但是在更新数据前,会判断其他数据在更新前有没有对数据进行修改。主要采用两种方式:版本号机制和CAS操作。
CAS操作:当需要更新数据时,判断当前内存值和之前取得的值是否相等。如果相等则用新值更新。若不等则失败,失败则重试,一般是一个自旋的过程,即不断重试。
自旋锁,公平锁,非公平锁?

四、读者写者问题
14.1 读写锁
在编写多线程的时候,有一种情况是十分常见的。那就是,有些公共数据修改的机会比较少。相比较改写,它们读的机会反而高的多。通常而言,在读的过程中,往往伴随着查找的操作,中间耗时很长。给这种代码段加锁,会极大地降低我们程序的效率。那么有没有一种方法,可以专门处理这种多读少写的情况呢? 有的,那就是读写锁。
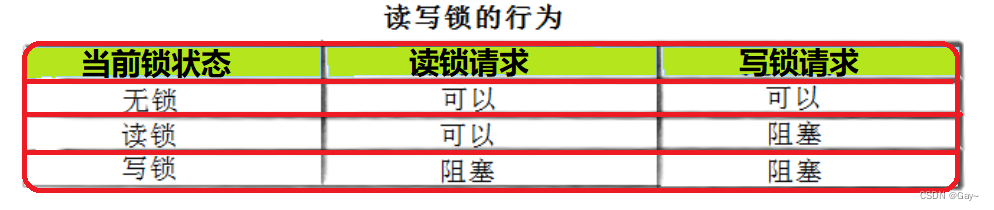
注意:写独占,读共享,读写同时来的时候,读锁优先级高,但是读者后来的话,可以是在他前面的写者优先级高的。
以上就是线程池的模拟实现的所有内容啦,你学会了吗?如果感觉到有所帮助的话,那就点点小心心,点点关注呗,后期还会持续更新Linux系统编程的相关知识哦,我们下期见!!!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!