机器学习算法新手入门指南
AI算法的种类在人工智能领域中非常丰富,而且多样化,AI算法利用数学、统计学和计算机科学等领域的原理和方法,通过模拟人类智能和学习能力来解决各种复杂的问题。
在监督学习领域,我们有经典的线性回归和逻辑回归算法,可以用于预测和分类任务,还有决策树和随机森林算法可以处理更复杂的决策问题,而支持向量机则适用于高维数据的分类和回归。
在无监督学习领域,聚类算法如K均值聚类和层次聚类可以将数据分组成不同的类别,主成分分析、因子分析等的降维算法可以帮助我们理解数据的结构和关系。
强化学习算法则通过智能体与环境的交互来学习最优策略,Q-learning、深度强化学习等算法在游戏、机器人控制和自动驾驶等领域展现出强大的能力。
除了传统的机器学习算法,深度学习算法也在AI领域引起了巨大的关注,神经网络、卷积神经网络和循环神经网络等深度学习算法在图像识别、语音识别、自然语言处理和推荐系统等任务中取得了重大突破。
此外,还有进化计算算法、自然语言处理算法、图像处理算法、推荐系统算法等等,这些算法都为AI的发展提供了丰富的工具和方法。
我们通过对上面所描述和罗列的算法进行分类,可以总结梳理出AI算法的“脉络”,如图1所示:

?面对如此多的算法,如何选择合适的算法?为此,我们需要先了解各种算法的优劣点,如表1所示:
| 算法种类 | 优势 | 劣势 |
| 监督学习算法 | 监督学习算法在有标签数据的情况下表现良好,能够进行准确的预测和分类,这类算法可以处理各种类型的数据,并且在训练充足的情况下通常具有较高的准确性。 | 监督学习算法对于标签数据的依赖性较高,需要大量的标记数据进行训练,此外,这类算法可能对噪声和异常值敏感,并且在处理高维数据和非线性关系时可能面临挑战。 |
| 无监督学习算法 | 无监督学习算法不需要标签数据,可以自动发现数据中的模式和结构,这类算法可以用于聚类、降维和异常检测等任务,并且在处理大规模数据时具有较好的可扩展性。 | 无监督学习算法通常无法提供明确的预测结果,因为这类算法没有预期输出进行比较,此外,算法的结果可能受到初始参数选择的影响,并且对于复杂的数据集,算法结果在可解释性上可能会有挑战。 |
| 强化学习算法 | 强化学习算法能够通过与环境的交互来学习最优策略,适用于动态和复杂的决策问题,这类算法在处理连续状态和动作空间时具有优势,并且能够在没有标签数据的情况下进行学习。 | 强化学习算法通常需要较长的训练时间和大量的交互次数才能达到良好的性能,此外,算法的稳定性和收敛性可能会受到影响,并且在处理高维状态空间时可能面临困难。 |
| 深度学习算法 | 深度学习算法在处理大规模数据和复杂任务时表现出色,这类算法能够自动学习特征表示,并且在图像识别、语音识别和自然语言处理等领域取得了巨大的成功。 | 深度学习算法通常需要大量的训练数据和计算资源,以及较长的训练时间,这类算法对超参数的选择和调整敏感,并且在解释模型的决策过程方面可能存在困难。 |
表1?各种AI算法的优劣势对比
表1是对每一大类的AI算法的优劣势比较,在细分到具体AI算法时,又有泛化性能、计算效率和复杂度上的差异,可以肯定的是,没有哪一种算法可以占绝对优势,当你选择某一个算法进行解决问题时,又不得不面对和正视所选择算法的劣势,正所谓“没有免费的午餐”,那么我们又该如何做出正确的选择呢?
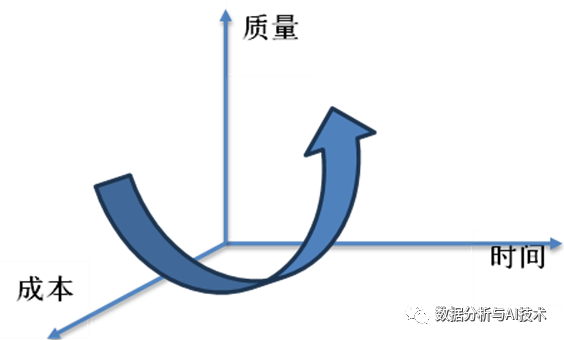
图2?项目管理三维度思维
从项目管理的角度,如图2所示,我们需要分别从项目的质量、成本、时间三个维度上去分析,需要综合考虑这些因素,并权衡它们之间的关系。例如,如果时间紧迫,我们可能需要选择一个相对简单且易于实现的算法。如果质量是关键,我们可能需要选择一个在准确性和泛化能力方面表现良好的算法。如果成本是限制因素,我们可能需要选择一个计算资源和数据收集成本较低的算法:
时间
算法的复杂性:某些算法可能需要更长的时间来实现和调试,而有的算法可能更简单和直接。
数据准备和预处理:不同的算法对数据的要求和预处理步骤可能不同,一些算法可能需要更多的数据准备工作,而有的算法可能对原始数据的要求较低。
训练和调优时间:某些算法可能需要更长的时间来训练和调优模型,而有的算法可能更快。
质量
算法的准确性:不同的算法在不同的问题和数据集上可能会有不同的准确性,我们需要评估算法在特定问题上的性能和预测能力。
过拟合和泛化能力:一些算法可能对训练数据过拟合,而在新数据上表现较差,我们需要考虑算法的泛化能力和对新数据的适应能力。
成本
计算资源:某些算法可能需要更多的计算资源和存储空间来训练和运行,我们需要评估可用的计算资源和成本限制。
数据收集和标注成本:某些算法可能需要更多的数据来训练和调优模型,我们需要考虑数据收集和标注的成本。
从软件工程的角度,我们需要深入了解开发需求,在可行性分析的过程中,对数据需要有充分的理解和分析,可以参考如下几点建议:
-
根据问题的特点:不同的问题可能需要不同的算法来解决。例如,对于分类问题,逻辑回归、决策树和支持向量机等算法可能是合适的选择,而对于图像识别问题,卷积神经网络可能更适合。
-
根据数据的特征:数据的特征对算法的选择也有影响。例如,如果数据具有高维度和复杂的非线性关系,深度学习算法可能更适合,而如果数据具有明显的聚类结构,聚类算法可能更适合。
-
根据数据量和质量:算法的性能通常与训练数据的数量和质量有关,某些算法可能对大规模数据集表现更好,而某些算法可能对噪声和异常值更敏感。
-
根据计算资源和时间:某些算法可能需要更多的计算资源和时间来训练和运行,在实际应用中,我们需要考虑可用的计算资源和时间限制。
从团队管理者的角度,可以尽量采用团队所熟悉的算法或过往项目中已成熟的算法,这样可以降低研发风险,提高研发效率,确保项目的顺利实施。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!