黑马商城 Elasticsearch从入门到部署 RestClient操作文档
https://blog.csdn.net/m0_67184231/article/details/134925465

5.RestClient操作文档
索引库准备好以后,就可以操作文档了。为了与索引库操作分离,我们再次创建一个测试类,做两件事情:
- 初始化RestHighLevelClient
- 我们的商品数据在数据库,需要利用IHotelService去查询,所以注入这个接口
package com.hmall.item.es;
import com.hmall.item.service.IItemService;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.io.IOException;
@SpringBootTest(properties = "spring.profiles.active=local")
public class DocumentTest {
private RestHighLevelClient client;
@Autowired
private IItemService itemService;
@BeforeEach
void setUp() {
this.client = new RestHighLevelClient(RestClient.builder(
HttpHost.create("http://192.168.150.101:9200")
));
}
@AfterEach
void tearDown() throws IOException {
this.client.close();
}
}5.1.新增文档
我们需要将数据库中的商品信息导入elasticsearch中,而不是造假数据了。
5.1.1.实体类
索引库结构与数据库结构还存在一些差异,因此我们要定义一个索引库结构对应的实体。
在hm-service模块的com.hmall.item.domain.dto包中定义一个新的DTO:
package com.hmall.item.domain.dto;
import io.swagger.annotations.ApiModel;
import io.swagger.annotations.ApiModelProperty;
import lombok.Data;
import java.time.LocalDateTime;
@Data
@ApiModel(description = "索引库实体")
public class ItemDTO{
@ApiModelProperty("商品id")
private String id;
@ApiModelProperty("商品名称")
private String name;
@ApiModelProperty("价格(分)")
private Integer price;
@ApiModelProperty("库存数量")
private Integer stock;
@ApiModelProperty("商品图片")
private String image;
@ApiModelProperty("类目名称")
private String category;
@ApiModelProperty("品牌名称")
private String brand;
@ApiModelProperty("销量")
private Integer sold;
@ApiModelProperty("评论数")
private Integer commentCount;
@ApiModelProperty("是否是推广广告,true/false")
private Boolean isAD;
@ApiModelProperty("更新时间")
private LocalDateTime updateTime;
}5.1.2.API语法
新增文档的请求语法如下:
POST /{索引库名}/_doc/1
{
"name": "Jack",
"age": 21
}对应的JavaAPI如下:

可以看到与索引库操作的API非常类似,同样是三步走:
- 1)创建Request对象,这里是
IndexRequest,因为添加文档就是创建倒排索引的过程 - 2)准备请求参数,本例中就是Json文档
- 3)发送请求
变化的地方在于,这里直接使用client.xxx()的API,不再需要client.indices()了。
5.1.3.完整代码
我们导入商品数据,除了参考API模板“三步走”以外,还需要做几点准备工作:
- 商品数据来自于数据库,我们需要先查询出来,得到
Item对象 Item对象需要转为ItemDTO对象ItemDTO需要序列化为json格式
因此,代码整体步骤如下:
- 1)根据id查询商品数据
Item - 2)将
Item封装为ItemDTO - 3)将
ItemDTO序列化为JSON - 4)创建IndexRequest,指定索引库名和id
- 5)准备请求参数,也就是JSON文档
- 6)发送请求
在item-service的DocumentTest测试类中,编写单元测试:
@Test
void testAddDocument() throws IOException {
// 1.根据id查询商品数据
Item item = itemService.getById(100002644680L);
// 2.转换为文档类型
ItemDTO itemDTO = BeanUtil.copyProperties(item, ItemDTO.class);
// 3.将ItemDTO转json
String doc = JSONUtil.toJsonStr(itemDTO);
// 1.准备Request对象
IndexRequest request = new IndexRequest("items").id(itemDTO.getId());
// 2.准备Json文档
request.source(doc, XContentType.JSON);
// 3.发送请求
client.index(request, RequestOptions.DEFAULT);
}5.2.查询文档
我们以根据id查询文档为例
5.2.1.语法说明
查询的请求语句如下:
GET /{索引库名}/_doc/{id}与之前的流程类似,代码大概分2步:
- 创建Request对象
准备请求参数,这里是无参,直接省略- 发送请求
不过查询的目的是得到结果,解析为ItemDTO,还要再加一步对结果的解析。示例代码如下:
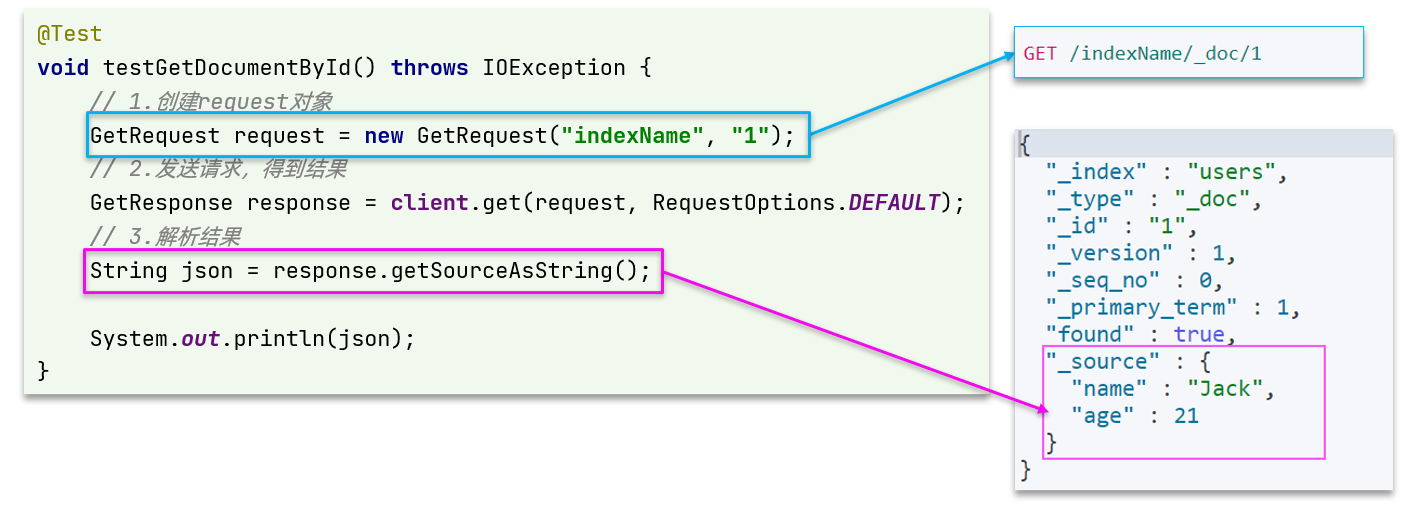
可以看到,响应结果是一个JSON,其中文档放在一个_source属性中,因此解析就是拿到_source,反序列化为Java对象即可。
其它代码与之前类似,流程如下:
- 1)准备Request对象。这次是查询,所以是
GetRequest - 2)发送请求,得到结果。因为是查询,这里调用
client.get()方法 - 3)解析结果,就是对JSON做反序列化
5.2.2.完整代码
在item-service的DocumentTest测试类中,编写单元测试:
@Test
void testGetDocumentById() throws IOException {
// 1.准备Request对象
GetRequest request = new GetRequest("items").id("100002644680");
// 2.发送请求
GetResponse response = client.get(request, RequestOptions.DEFAULT);
// 3.获取响应结果中的source
String json = response.getSourceAsString();
ItemDTO itemDTO = JSONUtil.toBean(json, ItemDTO.class);
System.out.println("itemDTO = " + itemDTO);
}5.3.删除文档
删除的请求语句如下:
DELETE /hotel/_doc/{id}与查询相比,仅仅是请求方式从DELETE变成GET,可以想象Java代码应该依然是2步走:
- 1)准备Request对象,因为是删除,这次是
DeleteRequest对象。要指定索引库名和id - 2)
准备参数,无参,直接省略 - 3)发送请求。因为是删除,所以是
client.delete()方法
在item-service的DocumentTest测试类中,编写单元测试:
@Test
void testDeleteDocument() throws IOException {
// 1.准备Request,两个参数,第一个是索引库名,第二个是文档id
DeleteRequest request = new DeleteRequest("item", "100002644680");
// 2.发送请求
client.delete(request, RequestOptions.DEFAULT);
}5.4.修改文档
修改我们讲过两种方式:
- 全量修改:本质是先根据id删除,再新增
- 局部修改:修改文档中的指定字段值
在RestClient的API中,全量修改与新增的API完全一致,判断依据是ID:
- 如果新增时,ID已经存在,则修改
- 如果新增时,ID不存在,则新增
这里不再赘述,我们主要关注局部修改的API即可。
5.4.1.语法说明
局部修改的请求语法如下:
POST /{索引库名}/_update/{id}
{
"doc": {
"字段名": "字段值",
"字段名": "字段值"
}
}代码示例如图:

与之前类似,也是三步走:
- 1)准备
Request对象。这次是修改,所以是UpdateRequest - 2)准备参数。也就是JSON文档,里面包含要修改的字段
- 3)更新文档。这里调用
client.update()方法
5.4.2.完整代码
在item-service的DocumentTest测试类中,编写单元测试:
@Test
void testUpdateDocument() throws IOException {
// 1.准备Request
UpdateRequest request = new UpdateRequest("items", "100002644680");
// 2.准备请求参数
request.doc(
"price", 58800,
"commentCount", 1
);
// 3.发送请求
client.update(request, RequestOptions.DEFAULT);
}5.5.批量导入文档
在之前的案例中,我们都是操作单个文档。而数据库中的商品数据实际会达到数十万条,某些项目中可能达到数百万条。
我们如果要将这些数据导入索引库,肯定不能逐条导入,而是采用批处理方案。常见的方案有:
- 利用Logstash批量导入
- 需要安装Logstash
- 对数据的再加工能力较弱
- 无需编码,但要学习编写Logstash导入配置
- 利用JavaAPI批量导入
- 需要编码,但基于JavaAPI,学习成本低
- 更加灵活,可以任意对数据做再加工处理后写入索引库
接下来,我们就学习下如何利用JavaAPI实现批量文档导入。
5.5.1.语法说明
批处理与前面讲的文档的CRUD步骤基本一致:
- 创建Request,但这次用的是
BulkRequest - 准备请求参数
- 发送请求,这次要用到
client.bulk()方法
BulkRequest本身其实并没有请求参数,其本质就是将多个普通的CRUD请求组合在一起发送。例如:
- 批量新增文档,就是给每个文档创建一个
IndexRequest请求,然后封装到BulkRequest中,一起发出。 - 批量删除,就是创建N个
DeleteRequest请求,然后封装到BulkRequest,一起发出
因此BulkRequest中提供了add方法,用以添加其它CRUD的请求:

可以看到,能添加的请求有:
IndexRequest,也就是新增UpdateRequest,也就是修改DeleteRequest,也就是删除
因此Bulk中添加了多个IndexRequest,就是批量新增功能了。示例:
@Test
void testBulk() throws IOException {
// 1.创建Request
BulkRequest request = new BulkRequest();
// 2.准备请求参数
request.add(new IndexRequest("items").id("1").source("json doc1", XContentType.JSON));
request.add(new IndexRequest("items").id("2").source("json doc2", XContentType.JSON));
// 3.发送请求
client.bulk(request, RequestOptions.DEFAULT);
}5.5.2.完整代码
当我们要导入商品数据时,由于商品数量达到数十万,因此不可能一次性全部导入。建议采用循环遍历方式,每次导入1000条左右的数据。
item-service的DocumentTest测试类中,编写单元测试:
@Test
void testLoadItemDocs() throws IOException {
// 分页查询商品数据
int pageNo = 1;
int size = 1000;
while (true) {
Page<Item> page = itemService.lambdaQuery().eq(Item::getStatus, 1).page(new Page<Item>(pageNo, size));
// 非空校验
List<Item> items = page.getRecords();
if (CollUtils.isEmpty(items)) {
return;
}
log.info("加载第{}页数据,共{}条", pageNo, items.size());
// 1.创建Request
BulkRequest request = new BulkRequest("items");
// 2.准备参数,添加多个新增的Request
for (Item item : items) {
// 2.1.转换为文档类型ItemDTO
ItemDTO itemDTO = BeanUtil.copyProperties(item, ItemDTO.class);
// 2.2.创建新增文档的Request对象
request.add(new IndexRequest()
.id(itemDTO.getId())
.source(JSONUtil.toJsonStr(itemDTO), XContentType.JSON));
}
// 3.发送请求
client.bulk(request, RequestOptions.DEFAULT);
// 翻页
pageNo++;
}
}5.6.小结
文档操作的基本步骤:
- 初始化
RestHighLevelClient - 创建XxxRequest。
- XXX是
Index、Get、Update、Delete、Bulk
- XXX是
- 准备参数(
Index、Update、Bulk时需要) - 发送请求。
- 调用
RestHighLevelClient#.xxx()方法,xxx是index、get、update、delete、bulk
- 调用
- 解析结果(
Get时需要)
6.作业
6.1.服务拆分
搜索业务并发压力可能会比较高,目前与商品服务在一起,不方便后期优化。
需求:创建一个新的微服务,命名为search-service,将搜索相关功能抽取到这个微服务中
6.2.商品查询接口
在item-service服务中提供一个根据id查询商品的功能,并编写对应的FeignClient
6.3.数据同步
每当商品服务对商品实现增删改时,索引库的数据也需要同步更新。
提示:可以考虑采用MQ异步通知实现。
?非常感谢您阅读到这里,创作不易!如果这篇文章对您有帮助,希望能留下您的点赞👍 关注💖 收藏 💕评论💬感谢支持!!!
听说 三连能够给人 带来好运!更有可能年入百w,进入大厂,上岸

[ 本文作者 ] 软工菜鸡
[ 博客链接 ] https://blog.csdn.net/m0_67184231
[ 版权声明 ] 如果您在非 CSDN 网站内看到这一行,
说明该死的侵权网络爬虫可能在本人还没有完整发布的时候就抓走了我的文章,
可能导致内容不完整,请去上述的原文链接查看原文。本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!