Python笔记04-数据容器列表、元组、字符串、集合、字典
Python中的数据容器:
一种可以容纳多份数据的数据类型,容纳的每一份数据称之为1个元素
每一个元素,可以是任意类型的数据,如字符串、数字、布尔等
数据容器根据特点的不同,如:
是否支持重复元素、是否可以修改、是否有序等
分为5类,分别是:
列表(list)、元组(tuple)、字符串(str)、集合(set)、字典(dict)
list
以 [] 作为标识 列表内每一个元素之间用, 逗号隔开
列表有如下特点:
可以容纳多个元素(上限为2**63-1、9223372036854775807个)
可以容纳不同类型的元素(混装)
数据是有序存储的(有下标序号)
允许重复数据存在
可以修改(增加或删除元素等)
定义方式
print("===========list==============")
[1,2,3,4]
numlist=[1,2]
list=[]
list=list()
列表中的每一个元素,都有其位置下标索引,从前向后的方向,从0开始,依次递增
或者,可以反向索引,也就是从后向前:从-1开始,依次递减(-1、-2、-3…)
list2=[1,2,3,4]
print(list2[0])
print(list2[-1])
===========list==============
1
4
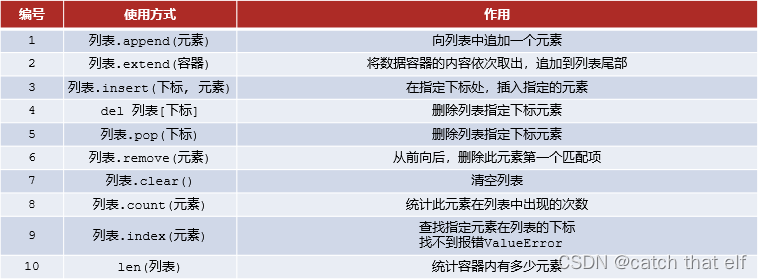
基本操作
列表除了可以使用下标索引获取值以外,也提供了一系列功能:插入元素、删除元素、清空列表、修改元素、统计元素个数等等功能,
list2=[1,2,3,4]
# 查找元素 返回数据的索引
print("索引位置",list2.index(3))
#print("索引位置",list2.index(10)) # index 不存在的元素程序会终止
#为特定位置赋值
list3=[1,2,3,4]
list3[-1]=10
print("为特定位置赋值",list3)
list3.insert(1,5)
print("插入数据后",list3)
list3.append(8)
list3.append([9,7])# 将list作为一个元素添加到 list3中
print("追加数据1",list3)
list3.extend([9,7])# 将list中的元素添加到 list3中
print("追加数据2",list3)
list4=[1,2,3,4]
del list4[0]
print("根据下标删除元素",list4)
list4.pop(0)
print("根据下标删除元素2",list4)
#删除某元素在列表中的第一个匹配项
list4.remove(3)
print("删除某元素在列表中的第一个匹配项",list4)
#清空
list4.clear()
print("清空",list4)
list5=[1,2,2,2,1,1,0,2,3,34,6]
print("统计元素数量",list5.count(1))
print("统计元素数量",list5.count(2))
print("统计元素数量",list5.count(10))
print("元素长度",len(list5))
输出结果
索引位置 2
为特定位置赋值 [1, 2, 3, 10]
插入数据后 [1, 5, 2, 3, 10]
追加数据1 [1, 5, 2, 3, 10, 8, [9, 7]]
追加数据2 [1, 5, 2, 3, 10, 8, [9, 7], 9, 7]
根据下标删除元素 [2, 3, 4]
根据下标删除元素2 [3, 4]
删除某元素在列表中的第一个匹配项 [4]
清空 []
统计元素数量 3
统计元素数量 4
统计元素数量 0
元素长度 11
Process finished with exit code 0
遍历
while i<len(list6):
print(list6[i])
i+=1
print("list遍历-for=======")
for el in list6:
print(el)
在使用场景上:
while循环适用于任何想要循环的场景
for循环适用于,遍历数据容器的场景或简单的固定次数循环场景
tuple 元组
列表是可以修改的。如果想要传递的信息,不被篡改,列表就不合适了。
元组同列表一样,都是可以封装多个、不同类型的元素在内。
但最大的不同点在于:元组一旦定义完成,就不可修改
所以,当我们需要在程序内封装数据,又不希望封装的数据被篡改,那么元组就非常合适了
元组不可以修改元组的内容,否则会直接报错;但是可以修改元组内的list的内容(修改元素、增加、删除、反转等)
元组有如下特点:
可以容纳多个数据
可以容纳不同类型的数据(混装)
数据是有序存储的(下标索引)
允许重复数据存在
不可以修改(增加或删除元素等)
支持for循环
多数特性和list一致,不同点在于不可修改的特性。
定义方式
print((1,2,3,4))
tp1=(1,2,3,4)
print(tp1)
tp2=()
tp3=tuple()
print(tp2)
print(tp3)
基本操作

tp4=(1,2,'lisa','zhang',2,2,2,1)
print("根据下标取值",tp4[2])
print("查找元素",tp4.index("lisa"))
print("统计次数",tp4.count(1))
print("元素总数",len(tp4))
根据下标取值 lisa
查找元素 2
统计次数 2
元素总数 8
遍历
同列表list
str
尽管字符串看起来并不像:列表、元组那样,一看就是存放了许多数据的容器。
但不可否认的是,字符串同样也是数据容器的一员。
字符串是字符的容器,一个字符串可以存放任意数量的字符。
和其它容器如:列表、元组一样,字符串也可以通过下标进行访问
从前向后,下标从0开始
从后向前,下标从-1开始
同元组一样,字符串是一个:无法修改的数据容器。
所以:
修改指定下标的字符 (如:字符串[0] = “a”)
移除特定下标的字符 (如:del 字符串[0]、字符串.remove()、字符串.pop()等)
追加字符等 (如:字符串.append())
均无法完成。如果必须要做,只能得到一个新的字符串,旧的字符串是无法修改
字符串有如下特点:
只可以存储字符串
长度任意(取决于内存大小)
支持下标索引
允许重复字符串存在
不可以修改(增加或删除元素等)
支持for循环
字符串操作
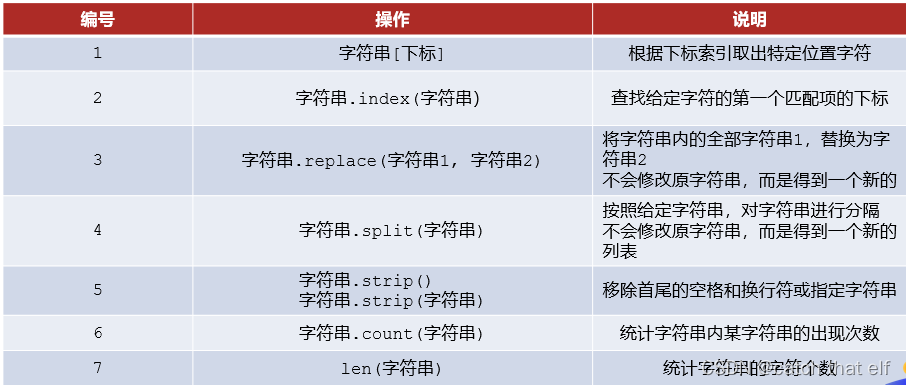
查找字符串
str ="我是中国人"
print(str.find("中国"))
替换字符串
语法:字符串.replace(字符串1,字符串2)
功能:将字符串内的全部:字符串1,替换为字符串2
注意:不是修改字符串本身,而是得到了一个新字符串哦
可以看到,字符串name本身并没有发生变化
而是得到了一个新字符串对象
str ="我是中国人"
str2=str.replace("我","我们")
print(str,str2) #我是中国人 我们是中国人
字符串分割
语法:字符串.split(分隔符字符串)
功能:按照指定的分隔符字符串,将字符串划分为多个字符串,并存入列表对象中
注意:字符串本身不变,而是得到了一个列表对象
可以看到,字符串按照给定的 <空格>进行了分割,变成多个子字符串,并存入一个列表对象中
str =“我是中国人”
print(str.split(“中”)) #[‘我是’, ‘国人’]
其他操作
print(" 111 v123 ".strip())#111 v123
print("qqq11112312hahqqq".strip("q"))#11112312hah
print("qqq11112312hahqqq".count("1"))#5
print(len("qqq11112312hahqqq"))#17
遍历
同list
序列(切片)
序列是指:内容连续、有序,可使用下标索引的一类数据容器
列表、元组、字符串,均可以可以视为序列。
序列支持切片,即:列表、元组、字符串,均支持进行切片操作
切片:从一个序列中,取出一个子序列
语法:序列[起始下标:结束下标:步长]
表示从序列中,从指定位置开始,依次取出元素,到指定位置结束,得到一个新序列:
起始下标表示从何处开始,可以留空,留空视作从头开始
结束下标(不含)表示何处结束,可以留空,留空视作截取到结尾
步长表示,依次取元素的间隔
步长1表示,一个个取元素
步长2表示,每次跳过1个元素取
步长N表示,每次跳过N-1个元素取
步长为负数表示,反向取(注意,起始下标和结束下标也要反向标记)
不会影响序列本身,而是会得到一个新的序列(列表、元组、字符串)
my_list = [1, 2, 3, 4, 5]
new_list = my_list[1:4] # 下标1开始,下标4(不含)结束,步长1
print(new_list) # 结果:[2, 3, 4]
my_tuple = (1, 2, 3, 4, 5)
new_tuple = my_tuple[:] # 从头开始,到最后结束,步长1
print(new_tuple) # 结果:(1, 2, 3, 4, 5)
my_list = [1, 2, 3, 4, 5]
new_list = my_list[::2] # 从头开始,到最后结束,步长2
print(new_list) # 结果:[1, 3, 5]
my_str = "12345"
new_str = my_str[:4:2] # 从头开始,到下标4(不含)结束,步长2
print(new_str) # 结果:"13"
set
我们目前接触到了列表、元组、字符串三个数据容器了。基本满足大多数的使用场景。
局限就在于:它们都支持重复元素。
如果场景需要对内容做去重处理,列表、元组、字符串就不方便了。
而集合,最主要的特点就是:不支持元素的重复(自带去重功能)、并且内容无序
特点
可以容纳多个数据
可以容纳不同类型的数据(混装)
数据是无序存储的(不支持下标索引)
不允许重复数据存在
可以修改(增加或删除元素等)
支持for循环
定义
print({1,1,1,1}) #输出 {1} 自动去重
sets={1}
sets=set()
常用功能
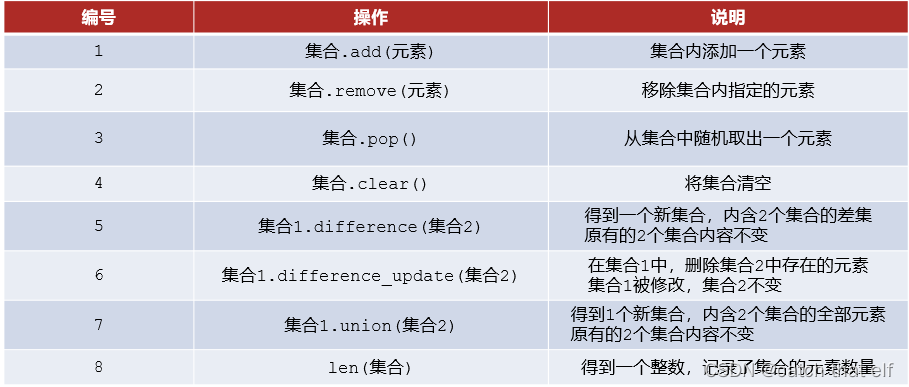
# 语法:集合.add(元素)。将指定元素,添加到集合内
# 结果:集合本身被修改,添加了新元素
my_set={"zhangsan","lisi"}
my_set.add("wangwu")
print(my_set)#{'zhangsan', 'wangwu', 'lisi'}
#语法:集合.remove(元素),将指定元素,从集合内移除
#结果:集合本身被修改,移除了元素
my_set.remove("lisi")
print(my_set)#{'wangwu', 'zhangsan'}
# 语法:集合.pop(),功能,从集合中随机取出一个元素
# 结果:会得到一个元素的结果。同时集合本身被修改,元素被移除
my_set.pop()
print(my_set)#{'wangwu'}
#语法:集合.clear(),功能,清空集合
#结果:集合本身被清空
print(my_set.clear())#None
#取出2个集合的差集
# 语法:集合1.difference(集合2),功能:取出集合1和集合2的差集(集合1有而集合2没有的)
# 结果:得到一个新集合,集合1和集合2不变
set1={1,2,3,4}
set2={1,3,5,6}
set3=set1.difference(set2)
print(set1)#{1, 2, 3, 4}
print(set2)#{1, 3, 5, 6}
print(set3)#{2, 4}
#消除2个集合的差集
# 语法:集合1.difference_update(集合2)
# 功能:对比集合1和集合2,在集合1内,删除和集合2相同的元素。
# 结果:集合1被修改,集合2不变
set1={1,2,3,4}
set2={1,3,5,6}
set3=set1.difference_update(set2)
print(set1)#{2, 4}
print(set2)#{1, 3, 5, 6}
print(set3)#None
#2个集合合并
# 语法:集合1.union(集合2)
# 功能:将集合1和集合2组合成新集合
# 结果:得到新集合,集合1和集合2不变
set1={1,2,3,4}
set2={1,3,5,6}
set3=set1.union(set2)
print(set1)#{1, 2, 3, 4}
print(set2)#{1, 3, 5, 6}
print(set3)#{1, 2, 3, 4, 5, 6}
print(len(set3))#6
遍历
集合不支持下标索引,所以也就不支持使用while循环,只能使用for
dict
字典的定义,同样使用{},不过存储的元素是一个个的键值对
每一个键值对包含Key和Value(用冒号分隔)
键值对之间使用逗号分隔
Key和Value可以是任意类型的数据(key不可为字典)
字典有如下特点:
可以容纳多个数据
可以容纳不同类型的数据
每一份数据是KeyValue键值对
可以通过Key获取到Value,Key不可重复(重复会覆盖)
不支持下标索引
可以修改(增加或删除更新元素等)
支持for循环,不支持while循环
定义
stu_score={"张三":99,"周五:100}
stu_score={"王":99,"赵":80,"李":97}
print(stu_score)#{'王': 99, '赵': 80, '李': 97}
print(stu_score["王"])#99
print(stu_score["李"])#97
常用操作

stu_score={"王":99,"赵":80,"李":97}
print(stu_score)#{'王': 99, '赵': 80, '李': 97}
print(stu_score["王"])#99
print(stu_score["李"])#97
#新增元素
# 语法:字典[Key] = Value,结果:字典被修改,新增了元素
stu_score["张"]=88
print(stu_score)#
#更新元素
# 语法:字典[Key] = Value,结果:字典被修改,元素被更新
# 注意:字典Key不可以重复,所以对已存在的Key执行上述操作,就是更新Value值
stu_score["张"]=99
print(stu_score)#{'王': 99, '赵': 80, '李': 97, '张': 99}
#删除元素
# 语法:字典.pop(Key),结果:获得指定Key的Value,同时字典被修改,指定Key的数据被删除
print(stu_score.pop("张"))#99
print(stu_score)#{'王': 99, '赵': 80, '李': 97}
#清空字典
# 语法:字典.clear(),结果:字典被修改,元素被清空
print(stu_score.clear())#None
print(stu_score)#{}
#获取全部的key
# 语法:字典.keys(),结果:得到字典中的全部Key
stu_score={"王":99,"赵":80,"李":97}
keys=stu_score.keys()
#遍历字典
# 语法:for key in 字典.keys()
for key in keys:
print(stu_score[key])
#计算字典内的全部元素(键值对)数量
# 语法:len(字典)
# 结果:得到一个整数,表示字典内元素(键值对)的数量
stu_score={"王":99,"赵":80,"李":97}
print(len(stu_score)) # 3
集合通用功能

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!