Mysql索引底层数据结构
欢迎大家关注我的微信公众号:
索引是帮助MySQL高效获取数据的排好序的数据结构
mysql的底层数据结构是B+Tree,是在B-Tree的基础上进行了优化,我们可以对比来看。
B-Tree

B+Tree
通过两者的数据结构对比,我们可以得知:
1、无论是B-Tree还是B+Tree,所有索引元素不重复
2、节点中的数据索引从左到右递增排列
3、B+Tree非叶子节点不存储data,只存储索引(冗余),可以放更多的索引
4、B+Tree叶子节点包含所有索引字段
5、B-Tree中叶节点具有相同的深度,且叶节点的指针为空;而B+Tree中叶子节点用指针连接,提高区间访问的性能
MyISAM和InnoDB的区别:
MyISAM存储引擎索引实现:
MyISAM索引文件和数据文件是分离的(非聚集索引)
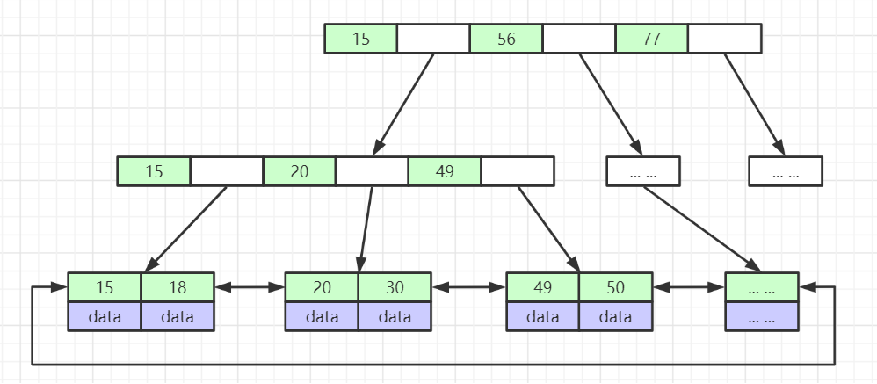
MyISAM的索引结构存储在.MYI文件中,而数据存储在.MYD文件中,当在.MYI文件中通过主键索引查询到叶子节点时,会获取到磁盘地址(如0x07),然后再通过该地址去.MYD文件中获取对应的完整数据。
InnoDB存储引擎索引实现:
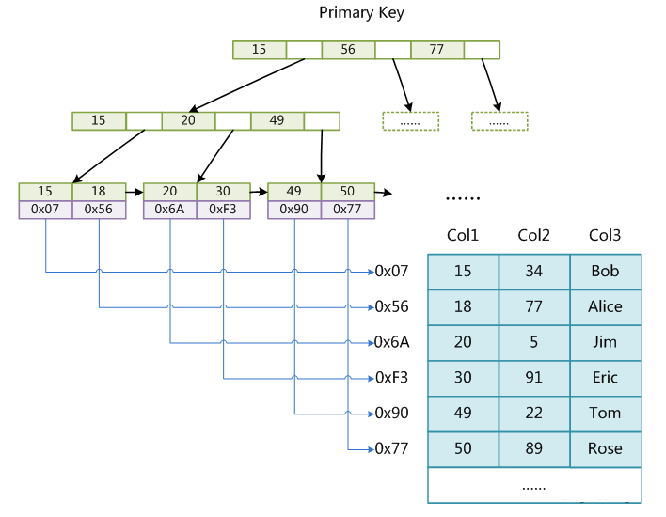
InnoDB主键索引实现为聚集索引(即叶子结点存储完整数据)
InnoDB表数据文件本身就是按B+Tree组织的一个索引结构文件,叶节点包含了完整的数据记录,存在.IBD文件中。当通过主键索引获取到叶子节点时,可以直接获取要查询的所有数据。
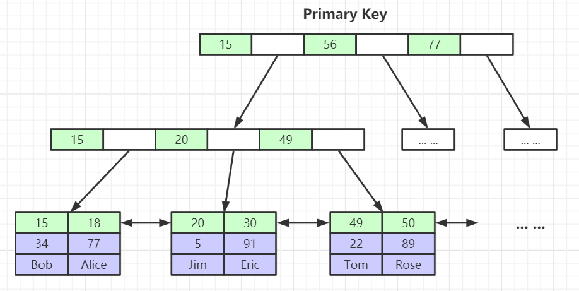
InnoDB主键索引与二级索引的区别:
除了主键索引,如果我们建了其它索引,结构如下:
在其它索引下,叶子节点并没有存放完整数据,而是存了主键。这个就涉及到了回表查询。当在.ibd文件中通过二级索引查询到叶子节点时,会获取到该表的主键,然后通过主键再次在.ibd文件中通过主键索引查询到叶子节点,获取完整数据。

通过上述对B+Tree及InnoDB的描述,我们可以解决如下问题:
为什么建议InnoDB表必须建主键?
-
存在主键,则mysql会直接用主键索引来构建数据结构
-
如果没有主键,mysql会选择一列所有数据都不相等的列作为索引构建数据结构
-
如果所有列都没有不相等的数据,mysql会建一个隐藏列(就像oracle的rowid)来维护唯一id
因此我们不要把建主键的行为交给mysql,导致不必要的性能消耗。
为什么推荐使用整型的自增主键?
-
索引是排好序的数据结构,每次查询都需要比大小,整型比大小效率要比字符串ASCII码值比大小高
-
整型相比字符串,占用磁盘空间会小很多
-
如果不是自增主键,当不断添加新数据时,mysql也会不断的修改已存在的索引结构来达到平衡
为什么非主键索引结构叶子节点存储的是主键值?
-
节省存储空间,如果非主键索引叶子节点也存储完整数据,必定会耗费更多的磁盘空间
-
保持数据的一致性。当有数据变更时,需要同时维护主键索引与非主键索引的完整数据,如果有一方失败,就会导致数据的差异性。而存储主键值,mysql只需要维护主键就可以了
?
另附:
查看mysql文件页大小(16K):SHOW GLOBAL STATUS like 'Innodb_page_size’;
为什么mysql页文件默认16K?
假设我们一行数据大小为1K,那么一页就能存16条数据,也就是一个叶子节点能存16条数据;再看非叶子节点,假设主键ID为bigint类型,那么长度为8B,指针大小在Innodb源码中为6B,一共就是14B,那么一页里就可以存储16K/14=1170个(主键+指针)
那么一颗高度为2的B+树能存储的数据为:1170*16=18720条,一颗高度为3的B+树能存储的数据为:1170*1170*16=21902400(千万级条)
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!