Redis Streams 实现消息队列
简单介绍
Redis中有三种消息队列模式:
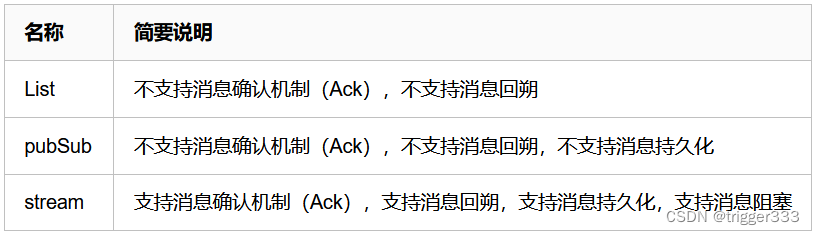
可以看出,作为Redis 5.0 引入的专门为消息队列设计的数据类型,Stream 功能更加健全,更适合做消息队列分发。 Stream 可以包含 0个 到 n个元素的有序队列,并根据ID的大小进行排序。
Stream类型消息队列的具备以下命令特点:
- 可以序列化生成消息ID,方便索引、排序
- 消息可回溯
- 支持Consumer Groups 消费组:多消费者消息争抢,加快消费速度
- 可以阻塞读取消息和非阻塞读取消息
- 没有消息漏读风险
- 有ACK消息确认机制,保证消息至少被消费一次
- 支持多播模式:可以让队列从逻辑上分组进行隔离消费
详细的stream操作见官网文档:https://redis.io/docs/data-types/streams-tutorial/
示例Demo
环境准备
需要下载Redis 5+版本(Redis 5+才支持streams)。
https://github.com/redis-windows/redis-windows/releases/tag/7.0.8
可以在命令行或者客户端进行测试。
客户端下载链接:
https://redis.com/redis-enterprise/redis-insight/
测试步骤
创建一个名为 "stream_demo" 的 Stream
XADD stream_demo* message "Message 1"
创建消息组:
XGROUP CREATE stream_demo mygroup $ MKSTREAM
阻塞式监听 Stream,等待消息到达
将消费者 "consumer1" 加入到消息组 "mygroup" 中,并且阻塞式地监听消息。
一旦消息到达,它会被消费者处理,然后使用 XACK 命令来确认已处理的消息。
XREADGROUP GROUP mygroup consumer1 BLOCK 0 STREAMS stream_demo >
执行添加消息的命令
XADD stream_demo * message "Message 2"
Python实现
import redis
def func(message):
print("Processing message:", message.decode('utf-8'))
def consume_messages():
r = redis.Redis(host='localhost', port=6379, db=0)
# 创建消息组
r.xgroup_create('stream_demo', 'mygroup', id='$', mkstream=True)
while True:
# 阻塞式监听消息
messages = r.xreadgroup('mygroup', 'consumer1', {'stream_demo': '>'}, block=0)
for stream, message_data in messages:
for message_id, message in message_data:
# 执行处理操作
func(message['message'.encode('utf-8')])
# 确认消息已处理
r.xack('stream_demo', 'mygroup', message_id)
# 删除已确认的消息
# r.xdel('stream_demo', message_id)
if __name__ == '__main__':
consume_messages()
消费者组实现
可以给各创建一个消费者组,组内只有一个消费者,可以实现一个消息被多个消费者消费。
参考链接:
https://blog.csdn.net/qq_37967783/article/details/131138580
https://www.cnblogs.com/wzh2010/p/17205395.html
生产者生产消息 放到队列中,消费者监听并获取消息 进行消息的消费
消费成功后会给一个ack,队列中就会将这个消息删除。
如果消费失败,消息重回队列;
消息队列中 未被确认的消息 如何重新消费掉
Redis Streams is a Redis data type that represents a log, so you can add new information and message in an append-only mode (Note: This is not 100% accurate, since you can remove messages from the log, but it’s close enough.) Redis Streams lets you build “Kafka-like” applications, which can:
- Create applications that publish and consume messages. Nothing extraordinary here, you could already do that with Redis Pub/Sub.
- Consume messages that are published even when the client application (consumer) is not running. This is a big difference from Redis Pub/Sub.
- Consume messages starting from a specific point. For example, read the whole history or only new messages.
如果消息进入到队列中 但是还没被消费,或者被消费但是没有被ack,redis就挂掉了,那么重启之后,要确保程序还能读得到未被消费或者被消费但是没有被ack的消息,继续处理。
要解决这个问题,你可以使用Redis的持久化功能来确保即使在Redis重启后,未被消费或未被确认的消息仍然可用。Redis提供两种主要的持久化方式:RDB持久化和AOF持久化。
-
RDB持久化:RDB持久化是将Redis的数据集快照保存到磁盘上的一个二进制文件中。你可以配置Redis以固定的时间间隔自动执行RDB持久化,或者手动执行SAVE命令来创建快照。当Redis重启时,它可以加载最近的RDB文件并恢复之前保存的状态,包括未被消费或未被确认的消息。
-
AOF持久化:AOF持久化是将Redis的写操作追加到一个日志文件(Append-Only File)中。通过将写操作追加到文件末尾,Redis可以在重启时重新执行这些写操作以恢复数据集的状态。你可以配置Redis以不同的方式执行AOF持久化,如每秒同步、每个写操作同步等。当Redis重启时,它会重新执行AOF文件中的写操作,确保未被消费或未被确认的消息不会丢失。
为了确保消息的持久性,你可以在Redis配置文件中启用RDB持久化和/或AOF持久化。以下是一些配置示例:
# 启用RDB持久化
save 60 1000 # 在60秒内,如果至少有1000个键发生变化,则执行RDB持久化
# 启用AOF持久化
appendonly yes
appendfsync everysec # 每秒将写操作同步到磁盘
通过启用持久化功能,即使Redis在重启后,你的程序也能读取到未被消费或未被确认的消息,并继续处理它们。请注意,持久化功能会增加Redis的磁盘IO和内存使用量,因此你需要根据实际情况进行配置和优化。
待续…
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!