python爬虫T1——urllib的基本使用 获取百度网页的源代码
2023-12-13 10:07:04
代码以及解释

import urllib.request #使用urllib来获取百度的源码
url='https://zhuanlan.zhihu.com/p/357258757' #定义一个url 目标访问地址
response=urllib.request=urllib.request.urlopen(url) #模拟浏览器向服务器发送请求 response响应
content=response.read().decode('utf-8') #定义一个变量接受响应内容 并使用utf-8编码所获取的内容
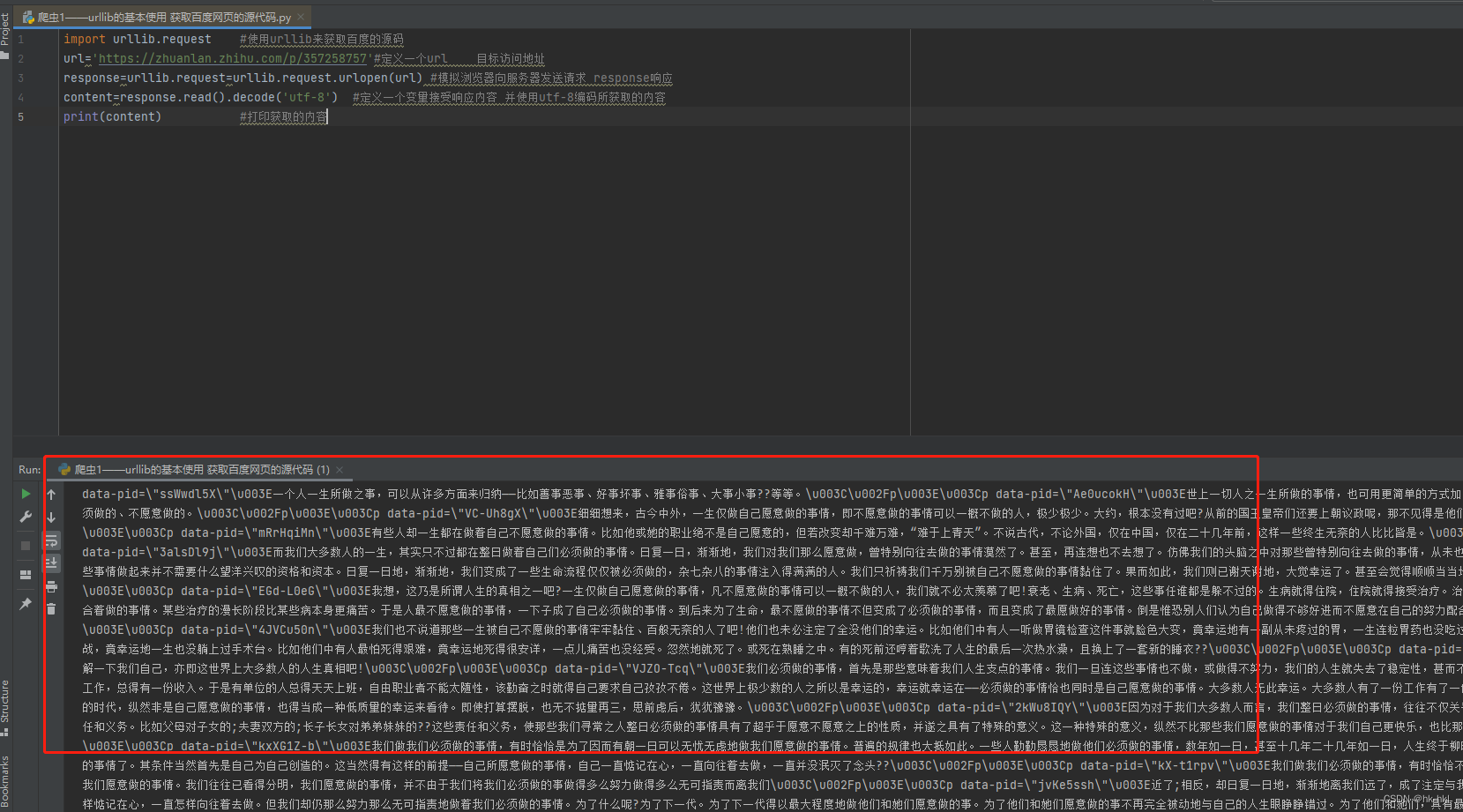
print(content) #打印获取的内容
效果
文章来源:https://blog.csdn.net/hk_hkl/article/details/134892538
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!