线性回归中的似然函数、最大似然估计、最小二乘法怎么来的(让你彻底懂原理)收官之篇
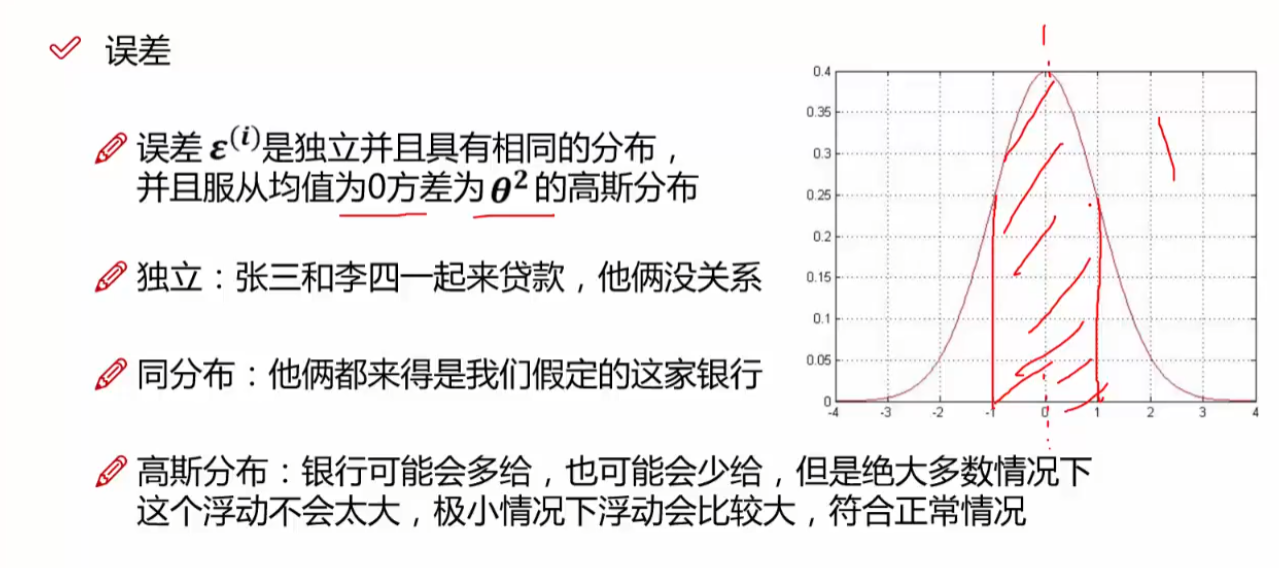
图1

图2

图3

图4
问1:为什么要引入似然函数?
在线性回归中引入似然函数是为了通过概率统计的方法对模型参数进行估计。简单来说,我们希望找到一组参数,使得我们观测到的数据在给定这组参数的情况下最有可能发生。
问:1:似然函数为什么要进行累乘?
参数要和所有的数据进行组合,不能仅满足一些样本,要满足所有的样本,要进行整体的一个考虑,要看所有的样本能不能进行一个满足。
问题2:为什么要引入对数似然?即为什么要引入log变换?
当我们进行求解的时候,对于机器来说,加法比较容易求解,对于乘法求解比较复杂,所以引入对数似然。对数可以把乘法转化为加法,从而简化操作。
问题3:线性回归中最小二乘法是怎么来的?为什么要引入这个?
如图4,最小二乘法是我们通过误差表达式化简得到的,化简后的表达式一共分为两部分,一个是常数,另一个就是去掉系数后的最小二乘法表达式,规定这个表达式即为最小二乘法。
问题5:为什么要让似然函数(对数变换后一样)越大越好?
似然函数是关于模型参数的函数,是描述观察到的真实数据在不同参数下发生的概率。最大似然估计要寻找最优参数,让似然函数最大化。或者说,使用最优参数时观测数据发生的概率最大。(让预测值成为真实值的可能性越大越好)
笔者查阅了多个资料来尝试理解这个问题,个人觉的如上理解比较好
问题6:什么样的θ(参数)能够使得最小二乘法表达式的值越小越好?
我们对表达式求导,即可得到这个参数
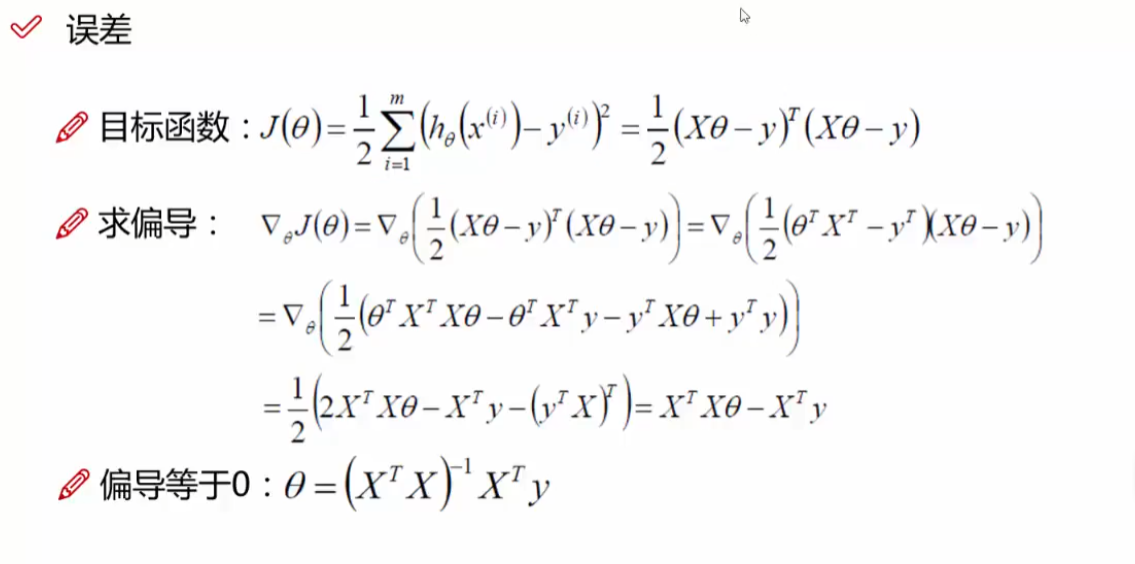
这里关于求导有问题的可以查看博文可能是全网最详细的线性回归原理讲解!!!-CSDN博客

残差:预测值减去真实值




α:学习率
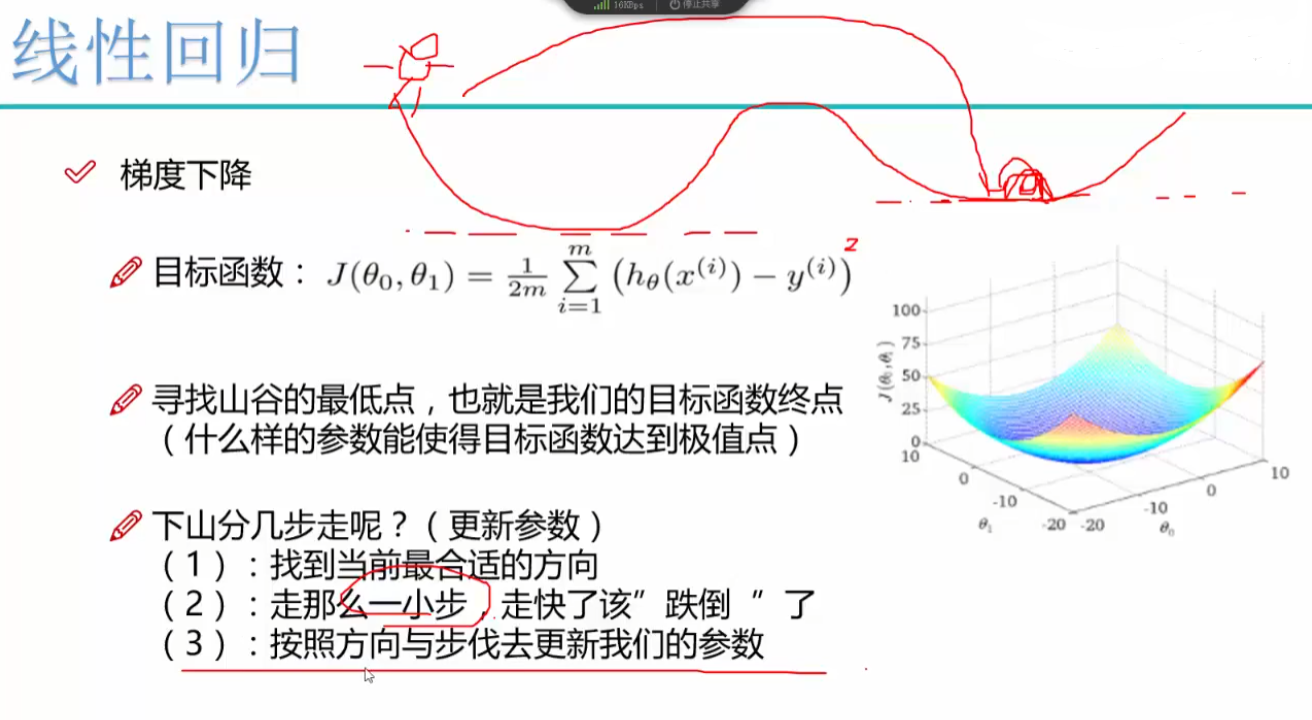
梯度下降:
总体来说,梯度下降是一种通用的、强大的优化算法,它提供了一种有效的方法来寻找目标函数的最小值,使得机器学习模型能够更好地拟合数据。
为什么需要梯度下降?
有些复杂的损失函数,我们很难用数学的方法,求出损失函数的全局最小值以及对应的参数值,这就是为什么需要梯度下降算法的原因。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!