自动化使用GradCAM处理图片(用于ViT和swin的变体)附链接
2023-12-14 21:56:08
GradCAM_On_ViT
用于可视化模型结果的 GradCAM 自动脚本
如何在 GradCam 中调整 XXXFormer
请确保您的模型格式正确。
如果您应用的变压器是类似 swin(无ClassToken)或类似 ViT (有ClassToken)
张量的形状可能看起来像[Batch,49,768],那么你应该按照以下步骤处理你的模型,以避免一些可怕的运行时错误
Class XXXFormer(nn.Moudle):
def __init(self,...):
super().__init__()
.....
self.avgpool = nn.AdaptiveAvgPool1d(1) #this is essential
def forward(self,x):
x = self.forward_feartrue(x) # Supose that the out put is [Batch,49,768]
x = self.avgpool(x.transpose(1,2)) # [Batch,49,768] --> [Batch,768,49] --> [Batch,768,1]
x = torch.flatten(x,1) # [Batch,768]
获取你的目标层
找到最后一个transformer block并选择 LayerNorm() 属性作为目标层,如果您有多个 LayerNorm() 属性,您可以将它们全部放在列表中或仅选择其中一个
您的目标图层可能如下所示
# choose one LayerNorm() attribute for your target layer
target_Layer1 = [vit.block[-1].norm1]
target_Layer2 = [vit.block[-1].norm2]
# or stack up them all
target_Layer3 = [vit.block[-1].norm1,vit.block.norm2]
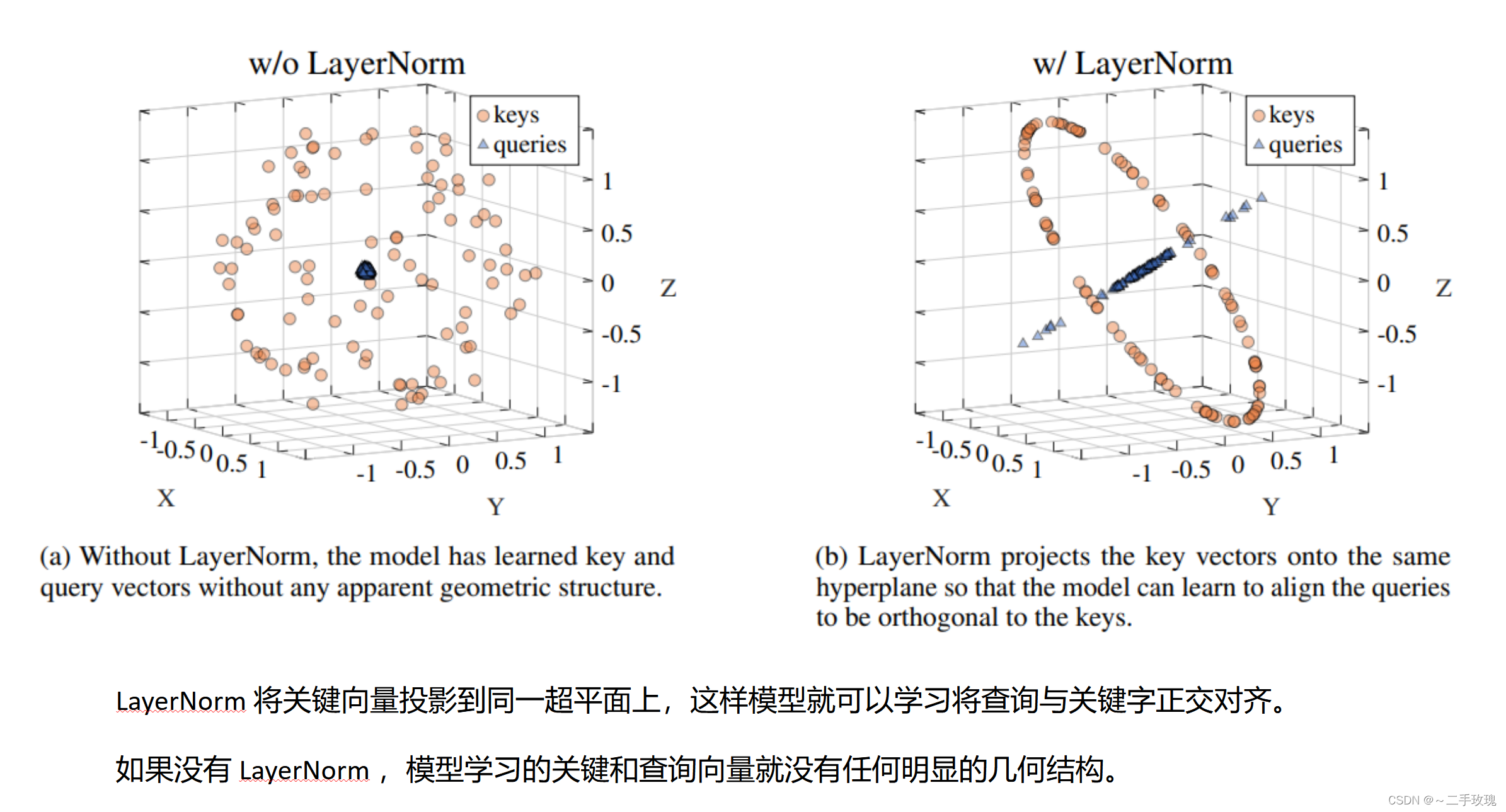
为什么我们选择LayerNorm作为目标层?
Reference: On the Expressivity Role of LayerNorm in Transformer’s Attention (ACL 2023).
The reason may be like this as shown in the picture
- Automatic_Swim_variant_CAM.py
- Automatic_ViT_variant_CAM.py
上面显示的两个 .py 文件是您需要运行的主要 Python 脚本
只需设置图像文件并运行这两个脚本即可!
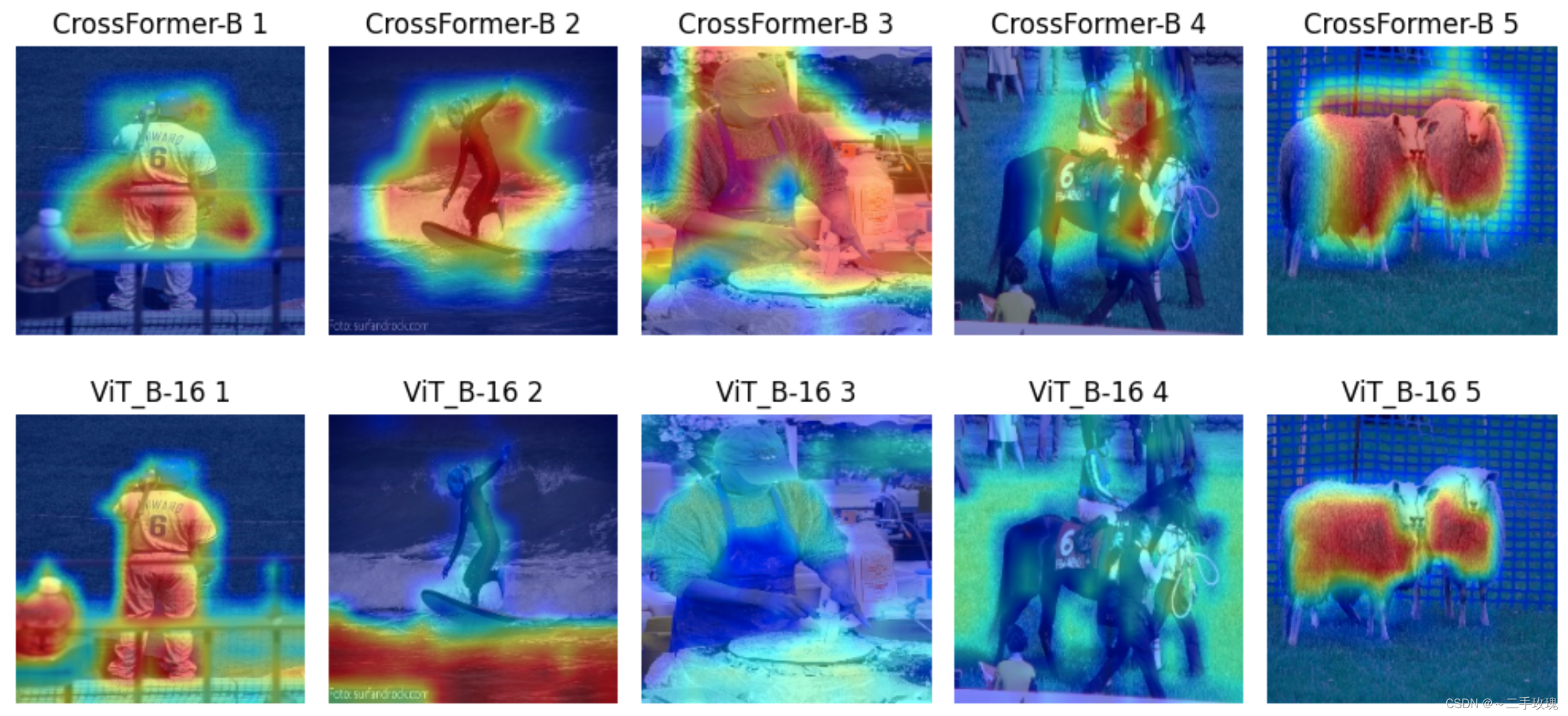
Using EigenCam as an example
Param you need to Pay attention
parser.add_argument('--path', default='./image', help='the path of image')
parser.add_argument('--method', default='all', help='the method of GradCam can be specific ,default all')
parser.add_argument('--aug_smooth', default=True, choices=[True, False],
help='Apply test time augmentation to smooth the CAM')
parser.add_argument('--use_cuda', default=True, choices=[True, False],
help='if use GPU to compute')
parser.add_argument(
'--eigen_smooth',
default=False, choices=[True, False],
help='Reduce noise by taking the first principle componenet'
'of cam_weights*activations')
parser.add_argument('--modelname', default="ViT-B-16", help='Any name you want')
链接:https://github.com/Mahiro2211/GradCAM_Automation
| Method |
|---|
| CrossFormer (ICLR 2022) |
| Vision Transformer (ICLR 2021) |
文章来源:https://blog.csdn.net/douhuanmin123/article/details/134879510
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!