云计算任务调度仿真02
2024-01-10 15:19:45
前面已经分享过一个仿真项目,但是基于policy gradient方法实现的,考虑到许多人从零到一实现DQN方法有点难度,所以这次分享一个基于DQN实现的仿真项目,非常简单。
这里之所以简单主要得益于它是用pytorch实现的,而pytorch各个版本之间差异不是非常大,可以互用。
这里没有之前那么复杂的建模,首先是任务类
class Task(object):
# 任务类
def __init__(self, jobID, index, CPU, RAM, disk, runtime, status):
import time
self.parent = []
self.child = []
self.jobID = jobID
self.index = index
self.CPU = CPU
self.RAM = RAM
self.disk = disk
self.status = status # -1: rejected, 0: finished, 1: ready, 2: running
self.runtime = runtime
self.ddl = time.time() + self.runtime * 5
self.endtime = 0
然后构建DAG,因为云计算中的任务大多是具有关联性的,是有向无环图
class DAG(object):
def __init__(self, fname, num_task):
self.fname = fname
# 任务数量
self.num_task = num_task
self.job = []
self.task = []
def readfile(self):
# 读取任务数据
num_task = 0
with open(self.fname, 'r') as f:
task = []
for line in f:
if line[0] == 'J':
if len(task) != 0:
self.job.append(task)
task = []
else:
info = list(line.split(','))
# 任务的信息,jobid,index就是任务的标识,cpu,内存,硬盘,
# 外加一个状态jobID, index, CPU, RAM, disk, runtime, status)
task.append \
(Task(info[5], info[6], float(info[3]), float(info[4]), float(info[8]), float(info[2]), 1))
num_task += 1
if num_task == self.num_task:
break
if len(task) != 0:
self.job.append(task)
def checkRing(self, parent, child):
# 检查无环
if parent.index == child.index:
return True
if len(child.child) == 0:
return False
for c in child.child:
if self.checkRing(parent, c):
return True
return False
def buildDAG(self):
# 构建有向无环图
import random
for job in self.job:
for task in job:
i = random.randint(-len(job), len(job) - 1)
if i < 0:
continue
parent = job[i]
if self.checkRing(parent, task) == False:
task.parent.append(parent)
parent.child.append(task)
……
……
环境类,定义云计算资源,以及调度过程中状态的转移,训练过程等等
class environment(object):
def __init__(self, scale, fname, num_task, num_server):
self.scale = scale
self.fname = fname
self.task = []
self.dag = DAG(self.fname, num_task) # 根据task数量构建dag
# 设置每个服务器上虚拟机的数量
self.VMNum = 5
self.rej = 0
# 任务数量和服务器数量是通过参数传递的
self.num_task = num_task
self.severNum = num_server
# 而集群数量是通过计算出来的
if num_server <= 50:
self.farmNum = 1
else:
if int(self.severNum / 50) * 50 < num_server:
self.farmNum = int(self.severNum / 50) + 1
else:
self.farmNum = int(self.severNum / 50)
self.remainFarm = []
self.FarmResources = []
self.severs = [[1, 1] for _ in range(self.severNum)]
self.VMtask = []
self.totalcost = 0
#self.init_severs(num_server)
self.losses_stage1 = []
self.losses_stage2 = []
print("Total Number of tasks: {0}".format(num_task))
def init_severs(self, severNum):
# 服务器,host,每个host上又可以虚拟出一定的虚拟机,然后虚拟机处理任务
VM = [[[1.0 / self.VMNum, 1.0 / self.VMNum] for _ in range(self.VMNum)] for _ in range(severNum)]
self.VMtask.append([[[] for _ in range(self.VMNum)] for _ in range(severNum)])
return VM
……
……
构建DQN的智能体,有Q值的计算和更新,才是基于值的强化学习方法
class Agent():
def __init__(self, input_dims, n_actions, lr, gamma=0.99,
epsilon=1.0, eps_dec=1e-5, eps_min=0.01):
self.lr = lr
self.input_dims = input_dims
self.n_actions = n_actions
self.gamma = gamma
self.epsilon = epsilon
self.eps_dec = eps_dec
self.eps_min = eps_min
self.action_space = [i for i in range(self.n_actions)]
self.Q = LinearDeepQNetwork(self.lr, self.n_actions, self.input_dims)
self.losses = []
def choose_action(self, state):
if np.random.random() > self.epsilon:
state1 = T.tensor(state, dtype=T.float).to(self.Q.device)
actions = self.Q.forward(state1)
#选最大的动作执行
action = T.argmax(actions).item()
else:
action = np.random.choice(self.action_space)
return action
def decrement_epsilon(self):
#贪心的变化
self.epsilon = self.epsilon - self.eps_dec \
if self.epsilon > self.eps_min else self.eps_min
def learn(self, state, action, reward, state_):
self.Q.optimizer.zero_grad()
states = T.tensor(state, dtype=T.float).to(self.Q.device)
actions = T.tensor(action).to(self.Q.device)
rewards = T.tensor(reward).to(self.Q.device)
states_ = T.tensor(state_, dtype=T.float).to(self.Q.device)
q_pred = self.Q.forward(states)[actions]
q_next = self.Q.forward(states_).max()
q_target = reward + self.gamma*q_next
loss = self.Q.loss(q_target, q_pred).to(self.Q.device)
loss.backward()
self.Q.optimizer.step()
self.decrement_epsilon()
self.losses.append(loss.item())
在此基础上,可以继续实现fixed-q-target和experience replay以及double QDN等优化
我添加了打印损失函数值的代码
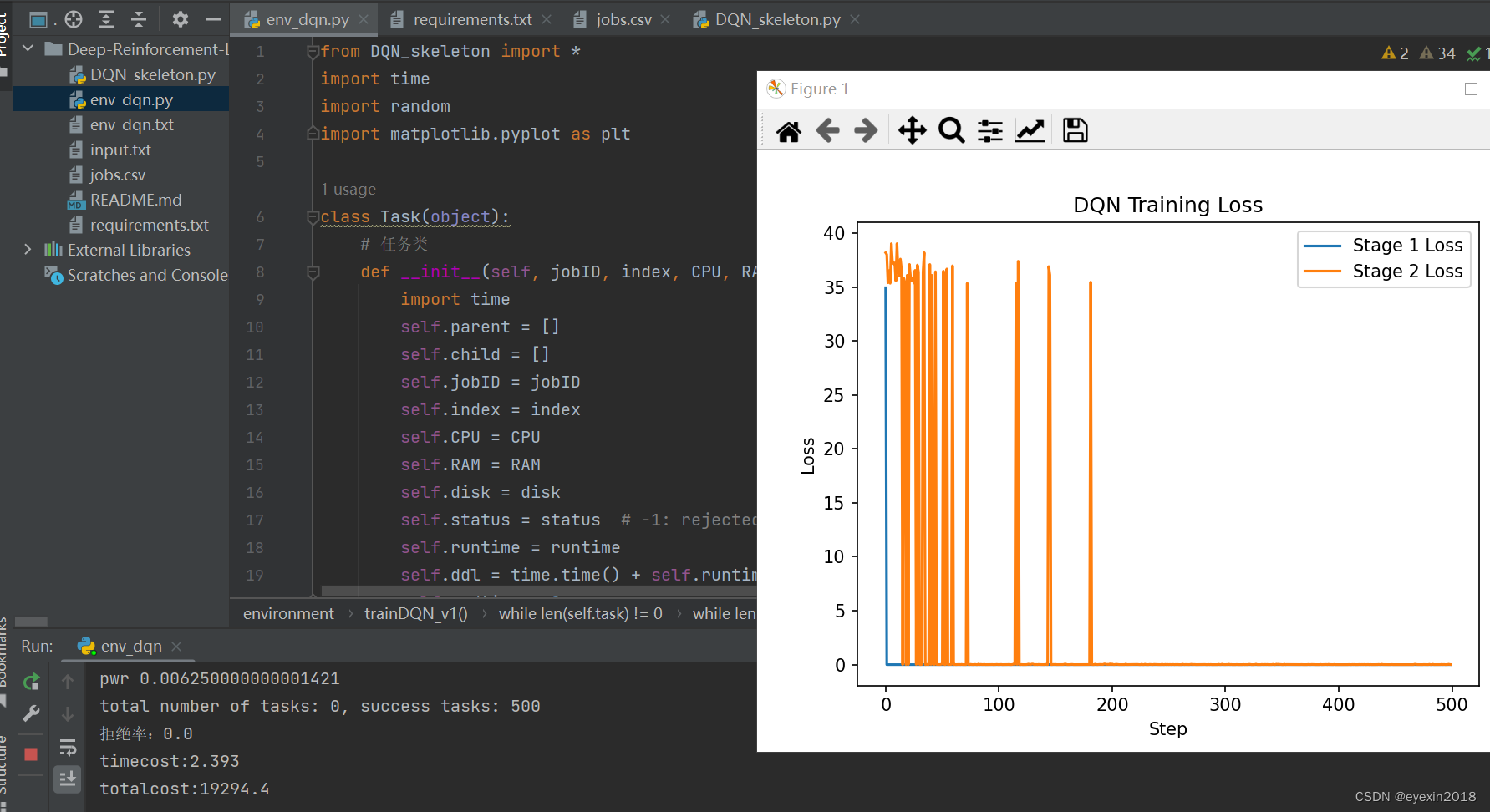
所以为了方便程序的运行和跨时间段使用,修改等,建议用pytorch进行实现
文章来源:https://blog.csdn.net/eyexin2018/article/details/135494577
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!