Airbert: In-domain Pretraining for Vision-and-Language Navigation
题目:Airbert:视觉和语言导航的域内预训练
摘要
为了解决VLN数据集稀缺的问题,本文创建了一个数据集BNB。我们首先从在线租赁市场的数十万个列表中收集图像标题 (IC) 对。接下来,我们使用 IC 对提出自动策略来生成数百万个 VLN 路径-指令 (PI) 对。我们进一步提出了一种shuffling loss,可以改善路径-指令对内时间顺序的学习。
我们使用 BnB 来预训练我们的 Airbert模型,该模型可以适应判别性和生成性设置,并表明它在房间到房间 (R2R) 导航和远程引用表达 (REVERIE) 基准测试方面优于最先进的技术。此外,我们的域内预训练显着提高了具有挑战性的几次 VLN 评估的性能,其中我们仅根据来自几个房子的 VLN 指令训练模型。
介绍
跨环境的 VLN 数据的高度多样性以及大规模手动收集和注释 VLN 训练数据难度很高。同时,有限的预训练环境无法让智能体具备视觉理解能力,无法泛化到未见过的房屋。如图1所示。

为了解决这个问题,VLN-BERT [28]建议在丰富且涵盖多种视觉语言知识的通用图像字幕数据集上对代理进行预训练。然而,这些图像标题对与 VLN 代理观察到的动态视觉流(路径)和可导航指令有很大不同。这种域外预训练虽然很有前景,但对导航性能的提升有限。除了上述限制之外,现有的预训练方法在代理任务中并不太重视时间推理能力,例如单步动作预测[13]和路径指令配对[28],而这种推理对于顺序决策任务(例如VLN。因此,即使下游任务的性能得到改善,预训练的模型仍然可能很脆弱。例如,通过交换指令中的名词短语或用其他名词替换它们来简单地破坏指令,会导致严重的混乱,因为模型无法选择正确的原始对。
在本文中,我们探索了不同的数据源和代理任务,以解决预训练通用 VLN 代理时的上述限制。尽管在互联网上很少找到导航指令,但在线市场(例如 Airbnb)中来自家庭环境的图像标题对非常丰富,其中包括租赁列表的图像和描述。
我们收集了 BnB,这是一个新的大型数据集,包含 140 万张室内图像和 70 万条字幕。首先,我们表明,当与通用 Web 数据一起应用时,域内图像标题对为下游 VLN 任务带来了额外的好处 [28]。为了进一步缩小 BnB 预训练和 VLN 任务之间的领域差距,我们提出了一种将静态图像标题对转换为视觉路径和类似导航指令的方法(图 1 底部),从而带来巨大的额外性能提升。我们还提出了一种shuffling loss,通过学习路径和相应指令之间的时间对齐来提高模型的时间推理能力。
我们的预训练模型 Airbert 是一个通用的transformer主干,可以轻松集成到判别性 VLN 任务中,例如 R2R 导航 [5] 中的路径指令兼容性预测 [28] 和生成 VLN 任务 [15] 和 REVERIE 远程引用表达式 [ 34]。我们通过预训练模型在这些 VLN 任务上实现了最先进的性能。除了标准评估之外,我们的域内预训练开辟了一次/几次 VLN 的令人兴奋的新方向,其中代理仅根据来自一个/几个环境的示例进行训练,并有望推广到其他未见过的环境。
总之,这项工作的贡献有三个方面:
(1) 我们收集了一个新的大规模域内数据集 BnB,以促进视觉和语言导航任务的预训练。
(2) 我们以不同的方式管理数据集,以减少预训练和 VLN 之间的分布偏移,并提出shuffling loss以提高时间推理能力。
?(3) 我们经过预训练的 Airbert 可以插入生成式或判别式架构中,并在 R2R 和 REVERIE 数据集上实现最先进的性能。此外,我们的模型在具有挑战性的one/few -shot?VLN 评估下具有良好的泛化能力,真正突出了我们学习范式的能力。
BnB数据集
在在线市场上出租房屋的房东通常会上传有吸引力且独特的照片以及描述。 Airbnb 就是这样的市场之一,拥有来自全球 10 万多个城市的 560 万个房源 [1]。我们建议使用这些丰富且精心策划的数据进行大规模域内 VLN 预训练。在本节中,我们首先描述如何从 Airbnb 收集图像标题对。然后,我们提出了将图像和标题转换为类似 VLN 的路径指令对的方法,以减少网络爬取的图像标题对和 VLN 任务之间的域差距(如图2所示)。

收集BnB图像-标题对
采集过程
数据来源:AirBnB的10%的数据
数据收集过程如下:(1)从维基百科获取位置列表; (2) 通过查询 Airbnb 搜索引擎查找这些地点的房源; (3) 下载列表及其元数据; (4) 删除由在 Places365 上预训练的 ResNet 模型分类的户外图像[50]; (5) 删除无效的图像标题,例如电子邮件、URL 和重复项。
统计
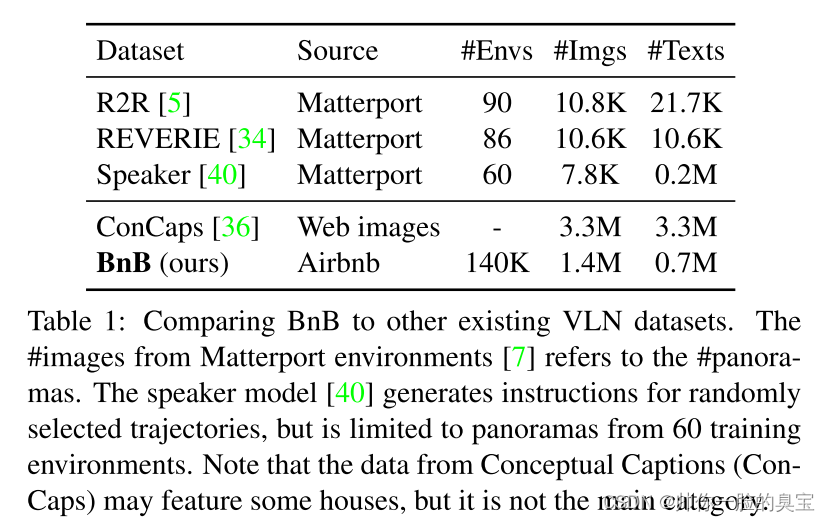
我们在第 3 步中下载了近 15 万个列表及其元数据(美国列表的 1/4),导致超过 300 万张图像和 100 万张标题。经过步骤 4 和 5 的数据清理后,我们获得了 713K 图像标题对和 676K 没有标题的图像。表 1 将我们的 BnB 数据集与之前用于 VLN(预)训练的其他数据集进行了比较。它比 R2R [5]、REVERIE [34] 更大,并且包含大量不同的房间和物体,而Concaps [36] 则不然。我们认为,此类域内数据对于应对 VLN 环境中的数据稀缺挑战至关重要,如图 1 所示。我们使用 95% 的 BnB 数据集进行训练,其余 5% 进行验证。
创建bnb路径-指令对
BnB 图像字幕 (IC) 对与概念字幕 (ConCaps) 互补,因为它们捕捉不同的 VLN 环境。然而,它们与 VLN 任务中的路径指令(PI)对仍然存在很大差异。例如,在导航过程中,代理观察一系列全景视图而不是单个图像,并且指令可能包含多个句子。为了缩小这一领域差距,我们提出了从 BnB-IC 对开始自动制作路径指令对的策略。
拼接在BNB列表中的图像和文本
BnB 列表中的图像通常描绘房屋中的不同位置,模仿代理在房屋中导航时进行的连续视觉观察。为了创建类似 VLN 的路径指令对,我们从列表中随机选择并连接 K个(R2R数据集是4-7个)?图像标题对。在每个标题之间,我们随机添加一个单词“and”、“then”、“.”。或者没有任何东西可以使串联指令更加流畅和多样化。(对应图2的Concatenating captions)
用视觉上下文增强路径
在上述串联路径中,每个位置仅包含一张 BnB 图像,并且可能具有有限的视角,因为主人可能会关注他们希望突出显示的对象或便利设施。因此,它缺乏代理在真实导航路径中接收到的每个位置的全景视觉上下文。此外,级联指令中的每个位置都由唯一的句子描述,而在 VLN 指令中,相邻位置通常在一个句子中一起表达[14]。为了解决上述连接问题,我们提出了两种方法来组合具有更多视觉上下文的路径,并且还可以利用丰富的没有标题的图像(表示为无标题图像)。
1、图像合并
图像合并通过对相似房间类别的图像进行分组来扩展某个位置的全景背景(见图 2)。
例如,如果图像描绘了厨房水槽,那么很自然地会预期附近有其他物体(例如叉子和刀子)的图像。具体来说,我们首先使用预训练的 Places365 模型 [50] 预测的房间标签对相似类别(例如厨房)的图像进行聚类。然后,我们从这组合并的图像中提取多个区域,并将它们用作全景视觉表示的近似值。
2、无标题图像插入
表 1 显示一半的 BnB 图像没有字幕。使用它们可以增加数据集的大小。当通过串联方法创建路径指令对时,会插入无标题图像,就好像其标题是空字符串一样。因此,BnB PI 对更好地近似了 R2R 路径指令的分布:(1)路径中的一些图像没有被描述,(2)指令具有相似数量的名词短语。
具有流畅过度的指令生成
连接的标题主要描述不同位置的房间或物体,但不包含导航指令中的任何可操作动词,例如“在门口左转”或“沿着走廊直走”。我们建议两种策略来创建在句子之间具有流畅转换的虚假指令。
1、指令改写
我们使用填空方法将人工注释的导航指令 [5] 中的名词短语替换为 BnB 标题中的名词短语(见图 2)。我们使用填空方法将人工注释的导航指令 [5] 中的名词短语替换为 BnB 标题中的名词短语(见图 2)。具体来说,我们创建了超过 10K 个包含 2-7 个空格的指令模板,并用从 BnB 标题中提取的名词短语填充空格。在选择过程中,首选与视觉基因组 [20] 数据集中的对象类别匹配的名词短语。这使我们能够创建类似 VLN 的指令,其中包含可操作的动词,其中散布着房间和对象引用,以作为 BnB 路径一部分的视觉提示。
2、指令生成
指令生成是一种类似视频字幕的模型,它接收一系列图像并生成与代理在环境中的路径相对应的指令。为了训练这个模型,我们采用 ViLBERT 并训练它为单个 BnB 图像标题对生成标题。此外,该模型根据 R2R 数据集的轨迹进行微调以生成指令。最后,我们使用该模型通过从 BnB(路径)生成连接图像序列的指令来生成 BnB PI 对。
AirBert:预训练的VLN模型
Airbert,是我们在 BnB 数据集上预训练的多模态transformer,具有mask和shuffling loss。我们首先介绍Airbert的架构,然后描述预训练中的数据集和pretext任务。最后,我们展示了 Airbert 如何适应下游 VLN 任务。
类似 ViLBERT 的架构
给定图像-标题对 (V, C),模型将图像编码为区域特征 [v1, ... 。 。 , vV] 通过预训练的 Faster R-CNN [4],并将文本嵌入为一系列标记:[[CLS], w1, . 。 。 , wT, [SEP]],其中 [CLS] 和 [SEP] 是添加到文本中的特殊标记。 ViLBERT 包含两个独立的transformer,对 V 和 C 进行编码,并通过共同注意力学习跨模式交互 [24]。
我们遵循类似的策略来编码包含多个图像和标题 {(Vk, Ck)}K k=1 的路径指令对(在第 3.2 节中创建)。
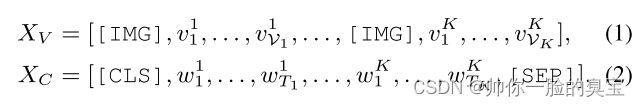
预训练的数据集和pretext任务
我们在后续的预训练步骤中使用概念标题(ConCaps)[36] 和 BnBPI(见图 3)来减少下游 VLN 任务的域间隙。

以前的多模态预训练工作[24,28,16]通常使用两种给定图像标题(IC)对或路径指令(PI)对的自监督损失:(1)掩蔽损失:输入图像区域或单词是随机替换为 [MASK] 令牌。该掩码标记的输出特征经过训练,可以在给定多模态上下文的情况下预测区域标签或单词。(2)配对损失:给定[IMG]和[CLS]标记的输出特征,训练二元分类器来预测图像(路径)和标题(指令)是否配对。
上述两个pretext任务主要关注学习对象-词关联,而不是推理路径和指令的时间顺序。例如,如果图像 Vi 出现在 Vj 之前,则其标题 Ci 中的单词应该出现在 Cj 之前。为了提高这种时间推理能力,我们提出了额外的shuffling损失来强制 PI 对之间的对齐。

针对下游任务的调整
我们考虑两个 VLN 任务:面向目标的导航(R2R [5])和面向对象的导航(REVERIE [34])。 Airbert 可以轻松集成到上述 VLN 任务的判别模型和生成模型中。
判别模型:导航作为路径选择
R2R 数据集上的导航问题在[28]中被表述为路径选择任务。通过导航代理(例如[40])的波束搜索生成多个候选路径,并训练判别模型以在其中选择最佳路径。我们在 R2R 数据集上微调 Airbert 以进行路径选择。采用两阶段微调过程:在第一阶段,我们以类似于BnB PI对的方式对目标VLN数据集的PI对使用掩蔽和洗牌损失;在第二阶段,我们选择一条到达目标 3m 以内的正候选路径,并将其与 3 条负候选路径进行对比。我们还比较了多种策略来挖掘额外的负对(除了 3 个负候选),事实上,经验表明使用洗牌创建的负数比其他选项表现更好。
生成模型:循环 VLN-BERT
循环 VLN-BERT 模型将循环添加到transformer中的状态中,以顺序预测动作,从而在 R2R 和 REVERIE 任务上实现最先进的性能。我们使用 Airbert 架构作为其骨干,并将其应用于以下两个任务。首先,语言transformer通过自注意力对指令进行编码。然后,指令中嵌入的 [CLS] 标记用于跟踪历史记录,并在每个操作步骤中与视觉标记(可观察的可导航视图或对象)连接。嵌入式指令上的自注意力和交叉注意力用于更新状态和视觉标记,并且从状态标记到视觉标记的注意力分数用于决定每一步的动作。我们以与[15]相同的方式微调以Airbert为骨干的Recurrent VLN-BERT模型。
限制
1、生成的指令不包含与路径中的图像相关的名词短语。
2、在路径生成的增强中,我们可以看到图像合并有助于将相关视觉上下文从单个图像扩展到半全景视图。无字幕图像插入还通过模仿指令中未提及的视点(由带有虚线边框的图像表示)来提高路径多样性。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!