Kubernetes里的DNS;API资源对象ingress;Kubernetes调度;节点选择器NodeSelector;节点亲和性NodeAffinity
Kubernetes里的DNS
K8s集群内有一个DNS服务:
kubectl get svc -n kube-system |grep dns

测试:
在tang3上安装bind-utils,目的是安装dig命令
yum install -y bind-utils
apt install dnsutils #ubuntu上
解析外网域名
dig @10.15.0.10 www.baidu.com
解析内部域名
dig @10.15.0.10 ngx-svc.default.svc.cluster.local
说明: ngx-svc为service name,service完整域名为service.namespace.svc.cluster.local
还可以解析Pod,Pod的域名有点特殊,格式为..pod.,例如10-18-206-93.default.pod.cluster.local
对应的Pod为coredns:
kubectl get po coredns -n kube-system
解释:
- nameserver: 定义DNS服务器的IP,其实就是kube-dns那个service的IP。
- search: 定义域名的查找后缀规则,查找配置越多,说明域名解析查找匹配次数越多。集群匹配有 default.svc.cluster.local、svc.cluster.local、cluster.local 3个后缀,最多进行8次查询 (IPV4和IPV6查询各四次) 才能得到正确解析结果。不同命名空间,这个参数的值也不同。
- option: 定义域名解析配置文件选项,支持多个KV值。例如该参数设置成ndots:5,说明如果访问的域名字符串内的点字符数量超过ndots值,则认为是完整域名,并被直接解析;如果不足ndots值,则追加search段后缀再进行查询。
DNS配置
可以通过查看coredns的configmap来获取DNS的配置信息:
[root@tang3 k8s]# kubectl describe cm coredns -n kube-system
Name: coredns
Namespace: kube-system
Labels: <none>
Annotations: <none>
Data
====
Corefile:
----
.:53 {
errors
health {
lameduck 5s
}
ready
kubernetes cluster.local in-addr.arpa ip6.arpa {
pods insecure
fallthrough in-addr.arpa ip6.arpa
ttl 30
}
prometheus :9153
forward . /etc/resolv.conf {
max_concurrent 1000
}
cache 30
loop
reload
loadbalance
}
说明:
- errors:错误信息到标准输出。
- health:CoreDNS自身健康状态报告,默认监听端口8080,一般用来做健康检查。您可以通过http://10.18.206.207:8080/health获取健康状态。(10.18.206.207为coredns其中一个Pod的IP)
- ready:CoreDNS插件状态报告,默认监听端口8181,一般用来做可读性检查。可以通过http://10.18.206.207:8181/ready获取可读状态。当所有插件都运行后,ready状态为200。
- kubernetes:CoreDNS kubernetes插件,提供集群内服务解析能力。
- prometheus:CoreDNS自身metrics数据接口。可以通过http://10.15.0.10:9153/metrics获取prometheus格式的监控数据。(10.15.0.10为kube-dns service的IP)
- forward(或proxy):将域名查询请求转到预定义的DNS服务器。默认配置中,当域名不在kubernetes域时,将请求转发到预定义的解析器(宿主机的/etc/resolv.conf)中,这是默认配置。
- cache:DNS缓存时长,单位秒。
- loop:环路检测,如果检测到环路,则停止CoreDNS。
- reload:允许自动重新加载已更改的Corefile。编辑ConfigMap配置后,请等待两分钟以使更改生效。
- loadbalance:循环DNS负载均衡器,可以在答案中随机A、AAAA、MX记录的顺序。
API资源对象ingress
有了Service之后,我们可以访问这个Service的IP(clusterIP)来请求对应的Pod,但是这只能是在集群内部访问。
要想让外部用户访问此资源,可以使用NodePort,即在node节点上暴漏一个端口出来,但是这个非常不灵活。为了解决此问题,K8s引入了一个新的API资源对象Ingress,它是一个七层的负载均衡器,类似于Nginx。
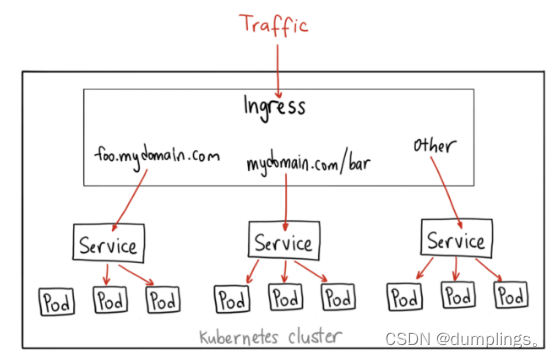
三个概念:Ingress、Ingress Controller、IngressClass
- Ingress用来定义具体的路由规则,要实现什么样的访问效果;
- Ingress Controller是实现Ingress定义具体规则的工具或者叫做服务,在K8s里就是具体的Pod;
- IngressClass是介于Ingress和Ingress Controller之间的一个协调者,它存在的意义在于,当有多个Ingress Controller时,可以让Ingress和Ingress Controller彼此独立,不直接关联,而是通过IngressClass实现关联。
Ingress YAML示例:
vi tang.yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: tang ##ingress名字
spec:
ingressClassName: tang ##定义关联的IngressClass
rules: ##定义具体的规则
- host: tanglinux.com ##访问的目标域名
http:
paths:
- path: /
pathType: Exact
backend: ##定义后端的service对象
service:
name: ngx-svc
port:
number: 80
查看ingress
kubectl get ing
kubectl describe ing tang
IngressClassYAML示例:
vi tangc.yaml
apiVersion: networking.k8s.io/v1
kind: IngressClass
metadata:
name: tang
spec:
controller: nginx.org/ingress-controller ##定义要使用哪个controller
查看ingressClass
kubectl get ingressclass
安装ingress-controller(使用Nginx官方提供的 https://github.com/nginxinc/kubernetes-ingress)
首先做一下前置工作
curl -O 'https://gitee.com/aminglinux/linux_study/raw/master/k8s/ingress.tar.gz'
tar zxf ingress.tar.gz
cd ingress
./setup.sh ##说明,执行这个脚本会部署几个ingress相关资源,包括namespace、configmap、secrect等
vi ingress-controller.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: ngx-ing
namespace: nginx-ingress
spec:
replicas: 1
selector:
matchLabels:
app: ngx-ing
template:
metadata:
labels:
app: ngx-ing
#annotations:
#prometheus.io/scrape: "true"
#prometheus.io/port: "9113"
#prometheus.io/scheme: http
spec:
serviceAccountName: nginx-ingress
containers:
- image: nginx/nginx-ingress:2.2-alpine
imagePullPolicy: IfNotPresent
name: ngx-ing
ports:
- name: http
containerPort: 80
- name: https
containerPort: 443
- name: readiness-port
containerPort: 8081
- name: prometheus
containerPort: 9113
readinessProbe:
httpGet:
path: /nginx-ready
port: readiness-port
periodSeconds: 1
securityContext:
allowPrivilegeEscalation: true
runAsUser: 101 #nginx
capabilities:
drop:
- ALL
add:
- NET_BIND_SERVICE
env:
- name: POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
args:
- -ingress-class=tangc
- -health-status
- -ready-status
- -nginx-status
- -nginx-configmaps=$(POD_NAMESPACE)/nginx-config
- -default-server-tls-secret=$(POD_NAMESPACE)/default-server-secret
应用YAML
kubectl apply -f ingress-controller.yaml
查看pod、deployment
kubectl get po -n nginx-ingress
kubectl get deploy -n nginx-ingress
将ingress对应的pod端口映射到master上临时测试
kubectl port-forward -n nginx-ingress ngx-ing-547d6575c7-fhdtt 8888:80 &
测试前,可以修改ng-deploy对应的两个pod里的/usr/share/nginx/html/index.html文件内容,用于区分两个pod
测试
curl -x127.0.0.1:8888 aminglinux.com
或者:
curl -H 'Host:aminglinux.com' http://127.0.0.1:8888
上面对ingress做端口映射,然后通过其中一个节点的IP来访问ingress只是一种临时方案。那么正常如何做呢?有三种常用的方案:
1)Deployment+LoadBalancer模式的Service
如果要把ingress部署在公有云,那用这种方式比较合适。用Deployment部署ingress-controller,创建一个type为LoadBalancer的service关联这组pod。
大部分公有云,都会为LoadBalancer的service自动创建一个负载均衡器,通常还绑定了公网地址。
只要把域名解析指向该地址,就实现了集群服务的对外暴露。
2)Deployment+NodePort模式的Service
同样用deployment模式部署ingress-controller,并创建对应的服务,但是type为NodePort。这样,ingress就会暴露在集群节点ip的特定端口上。
由于nodeport暴露的端口是随机端口,一般会在前面再搭建一套负载均衡器来转发请求。该方式一般用于宿主机是相对固定的环境ip地址不变的场景。
NodePort方式暴露ingress虽然简单方便,但是NodePort多了一层NAT,在请求量级很大时可能对性能会有一定影响。
3)DaemonSet+HostNetwork+nodeSelector
用DaemonSet结合nodeselector来部署ingress-controller到特定的node上,然后使用HostNetwork直接把该pod与宿主机node的网络打通(如,上面的临时方案kubectl port-forward),直接使用宿主机的80/433端口就能访问服务。
这时,ingress-controller所在的node机器就很类似传统架构的边缘节点,比如机房入口的nginx服务器。该方式整个请求链路最简单,性能相对NodePort模式更好。
缺点是由于直接利用宿主机节点的网络和端口,一个node只能部署一个ingress-controller pod。比较适合大并发的生产环境使用。
搞懂Kubernetes调度
K8S调度器Kube-schduler的主要作用是将新创建的Pod调度到集群中的合适节点上运行。kube-scheduler的调度算法非常灵活,可以根据不同的需求进行自定义配置,比如资源限制、亲和性和反亲和性等。
1)kube-scheduler的工作原理如下:
- 监听API Server: kube-scheduler会监听API Server上的Pod对象,以获取需要被调度的Pod信息。它会通过API Server提供的REST API接口获取Pod的信息,例如Pod的标签、资源需求等信息。
- 筛选可用节点: kube-scheduler会根据Pod的资源需求和约束条件(例如Pod需要的特定节点标签)筛选出可用的Node节点。它会从所有注册到集群中的Node节点中选择符合条件的节点。
- 计算分值: kube-scheduler会为每个可用的节点计算一个分值,以决定哪个节点是最合适的。分值的计算方式可以通过调度算法来指定,例如默认的算法是将节点资源利用率和距离Pod的网络延迟等因素纳入考虑。
- 选择节点: kube-scheduler会选择分值最高的节点作为最终的调度目标,并将Pod绑定到该节点上。如果有多个节点得分相等,kube-scheduler会随机选择一个节点。
- 更新API Server: kube-scheduler会更新API Server上的Pod对象,将选定的Node节点信息写入Pod对象的spec字段中,然后通知Kubelet将Pod绑定到该节点上并启动容器。
2)Kube-scheduler调度器内部流转过程
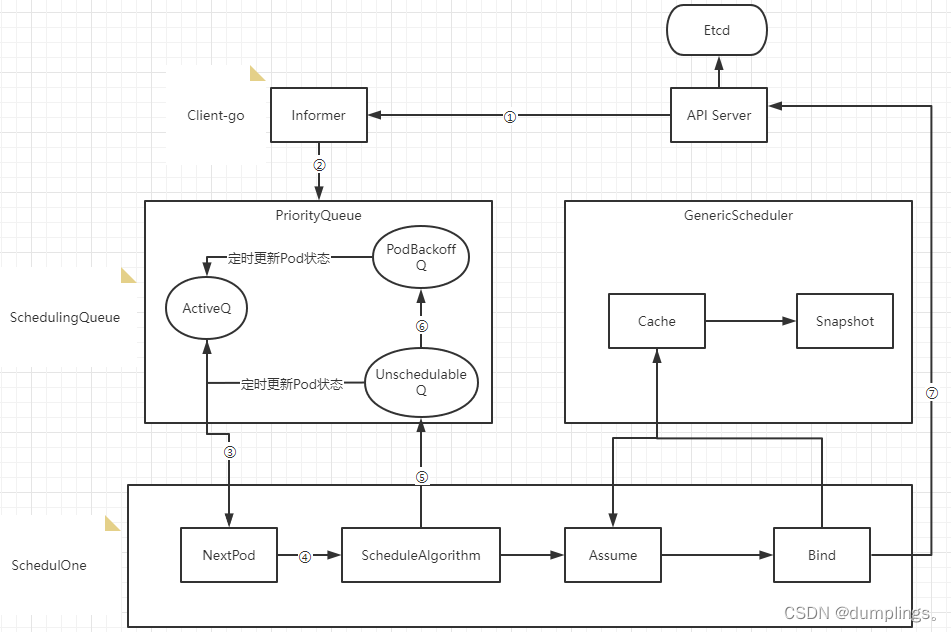
- ① Scheduler通过注册client-go的informer handler方法监听api-server的pod和node变更事件,获取pod和node信息缓存到Informer中
- ② 通过Informer的handler将事件更新到ActiveQ(ActiveQ、UnschedulableQ、PodBackoffQ为三个Scheduling队列,ActiveQ是一个维护着Pod优先级的堆结构,调度器在调度循环中每次从堆中取出优先级最高的Pod进行调度)
- ③ 调度循环通过NextPod方法从ActiveQ中取出待调度队列
- ④ 使用调度算法针对Node和Pod进行匹配和打分确定调度目标节点
- ⑤ 如果调度器出错或失败,会调用shed.Error将Pod写入UnschedulableQ里
- ⑥ 当不可调度时间超过backoff的时间,Pod会由Unschedulable转换到Podbackoff,也就是说Pod信息会写入到PodbackoffQ里
- ⑦ Client-go向Api Server发送一个bind请求,实现异步绑定
调度器在执行绑定操作的时候是一个异步过程,调度器会先在缓存中创建一个和原来Pod一样的Assume Pod对象用模拟完成节点的绑定,如将Assume Pod的Nodename设置成绑定节点名称,同时通过异步执行绑定指令操作。在Pod和Node绑定之前,Scheduler需要确保Volume已经完成绑定操作,确认完所有绑定前准备工作,Scheduler会向Api Server 发送一个Bind 对象,对应节点的Kubelet将待绑定的Pod在节点运行起来。
3)为节点计算分值
节点分值计算是通过调度器算法实现的,而不是固定的。默认情况下,kube-scheduler采用的是DefaultPreemption算法,其计算分值的方式包括以下几个方面:
- 节点的资源利用率 kube-scheduler会考虑每个节点的CPU和内存资源利用率,将其纳入节点分值的计算中。资源利用率越低的节点得分越高。
- 节点上的Pod数目 kube-scheduler会考虑每个节点上已经存在的Pod数目,将其纳入节点分值的计算中。如果节点上已经有大量的Pod,新的Pod可能会导致资源竞争和拥堵,因此节点得分会相应降低。
- Pod与节点的亲和性和互斥性 kube-scheduler会考虑Pod与节点的亲和性和互斥性,将其纳入节点分值的计算中。如果Pod与节点存在亲和性,例如Pod需要特定的节点标签或节点与Pod在同一区域,节点得分会相应提高。如果Pod与节点存在互斥性,例如Pod不能与其他特定的Pod共存于同一节点,节点得分会相应降低。
- 节点之间的网络延迟 kube-scheduler会考虑节点之间的网络延迟,将其纳入节点分值的计算中。如果节点之间的网络延迟较低,节点得分会相应提高。
- Pod的优先级 kube-scheduler会考虑Pod的优先级,将其纳入节点分值的计算中。如果Pod具有高优先级,例如是关键业务的部分,节点得分会相应提高。
这些因素的相对权重可以通过kube-scheduler的命令行参数或者调度器配置文件进行调整。需要注意的是,kube-scheduler的算法是可扩展的,可以根据需要编写自定义的调度算法来计算节点分值。
4)调度策略
- 默认调度策略(DefaultPreemption): 默认调度策略是kube-scheduler的默认策略,其基本原则是为Pod选择一个未满足需求的最小代价节点。如果无法找到这样的节点,就会考虑使用预选,即将一些已经调度的Pod驱逐出去来为新的Pod腾出空间。
- 带优先级的调度策略(Priority): 带优先级的调度策略基于Pod的优先级对节点进行排序,优先选择优先级高的Pod。该策略可以通过设置Pod的PriorityClass来实现。
- 节点亲和性调度策略(NodeAffinity): 节点亲和性调度策略基于节点标签或其他条件,选择与Pod需要的条件相匹配的节点。这可以通过在Pod定义中使用NodeAffinity配置实现。
- Pod 亲和性调度策略(PodAffinity): Pod 亲和性调度策略根据Pod的标签和其他条件,选择与Pod相似的其他Pod所在的节点。这可以通过在Pod定义中使用PodAffinity配置实现。
- Pod 互斥性调度策略(PodAntiAffinity): Pod 互斥性调度策略选择与Pod不相似的其他Pod所在的节点,以避免同一节点上运行相似的Pod。这可以通过在Pod定义中使用PodAntiAffinity配置实现。
- 资源限制调度策略(ResourceLimits): 资源限制调度策略选择可用资源最多的节点,以满足Pod的资源需求。这可以通过在Pod定义中使用ResourceLimits配置实现。
节点选择器NodeSelector
NodeSelector会将Pod根据定义的标签选定到匹配的Node上去。
示例:
cat > nodeselector.yaml <<EOF
apiVersion: v1
kind: Pod
metadata:
name: nginx-ssd
spec:
containers:
- name: nginx-ssd
image: nginx:1.23.2
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
nodeSelector:
disktype: ssd
EOF
应用YAML
kubectl apply -f nodeselector.yaml
查看Pod状态
kubectl describe po nginx-ssd
给Node打标签
kubectl label node k8s02 disktype=ssd
查看Node label
kubectl get node --show-labels
查看Pod信息
kubectl describe po nginx-ssd |grep -i node
节点亲和性NodeAffinity
也是针对Node,目的是把Pod部署到符合要求的Node上。
关键词:
① requiredDuringSchedulingIgnoredDuringExecution:表示强匹配,必须要满足
② preferredDuringSchedulingIgnoredDuringExecution:表示弱匹配,尽可能满足,但不保证
示例:
apiVersion: v1
kind: Pod
metadata:
name: with-node-affinity
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution: ##必须满足下面匹配规则
nodeSelectorTerms:
- matchExpressions:
- key: env
operator: In ##逻辑运算符支持:In,NotIn,Exists,DoesNotExist,Gt,Lt
values:
- test
- dev
preferredDuringSchedulingIgnoredDuringExecution: ##尽可能满足,但不保证
- weight: 1
preference:
matchExpressions:
- key: project
operator: In
values:
- aminglinux
containers:
- name: with-node-affinity
image: redis:6.0.6
说明:
匹配逻辑:
① 同时指定Node Selector和Node Affinity,两者必须同时满足;
② Node Affinity中指定多组nodeSelectorTerms,只需要一组满足就可以;
③ 当在nodeSelectorTerms中包含多组matchExpressions,必须全部满足才可以;
演示示例:
编辑pod的yaml
cat > nodeAffinity.yaml << EOF
apiVersion: v1
kind: Pod
metadata:
name: node-affinity
spec:
containers:
- name: my-container
image: nginx:1.23.2
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: special-node
operator: Exists
EOF
给其中一个节点定义标签
kubectl label nodes aminglinux03 special-node=true
生效Pod yaml
kubectl apply -f nodeAffinity.yaml
检查Pod所在node
kubectl get po -o wide
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!