ActionCLIP:A New Paradigm for Video Action Recognition
文章目录
ActionCLIP: A New Paradigm for Video Action Recognition
论文:https://arxiv.org/abs/2109.08472
代码:https://github.com/sallymmx/ActionCLIP
动机
-
单模态的网络以预先定义好的类别进行训练,限制了模型的泛化能力
-
现有的单一模式管道(a)和我们的多模式框架(b)。它们在标签的使用上是不同的。(a)将标签映射到数字或独热向量,而(b)利用标签文本本身的语义信息并试图将对应的视频表示拉到彼此接近
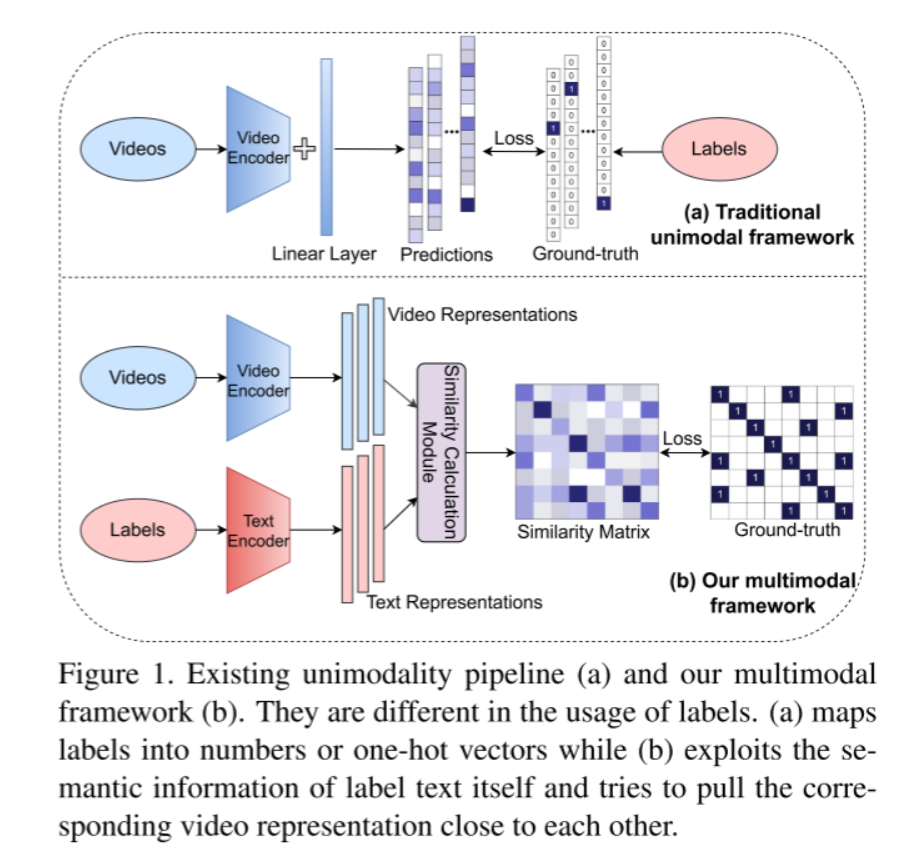
-
使用大量Web数据进行预训练开销过大
创新点
- 建模为多模态学习框架内的视频-文本匹配问题,通过更多的语义语言监督来增强视频表示:实现零样本学习
- 采用“预训练,提示和微调”的范式:解决标签文本的不足和利用大量的网络数据导致资源开销过大的问题
相关工作
- 视频动作识别:只是特征工程或者是网络架构工程,大多数是但模态的,没有考虑语义信息
- 动作识别中的视觉-文本多模态
- 自监督视频表征学习:输出类别固定
- 零样本动作识别:模型不关注上游一般的动作识别任务
方法
多模态框架
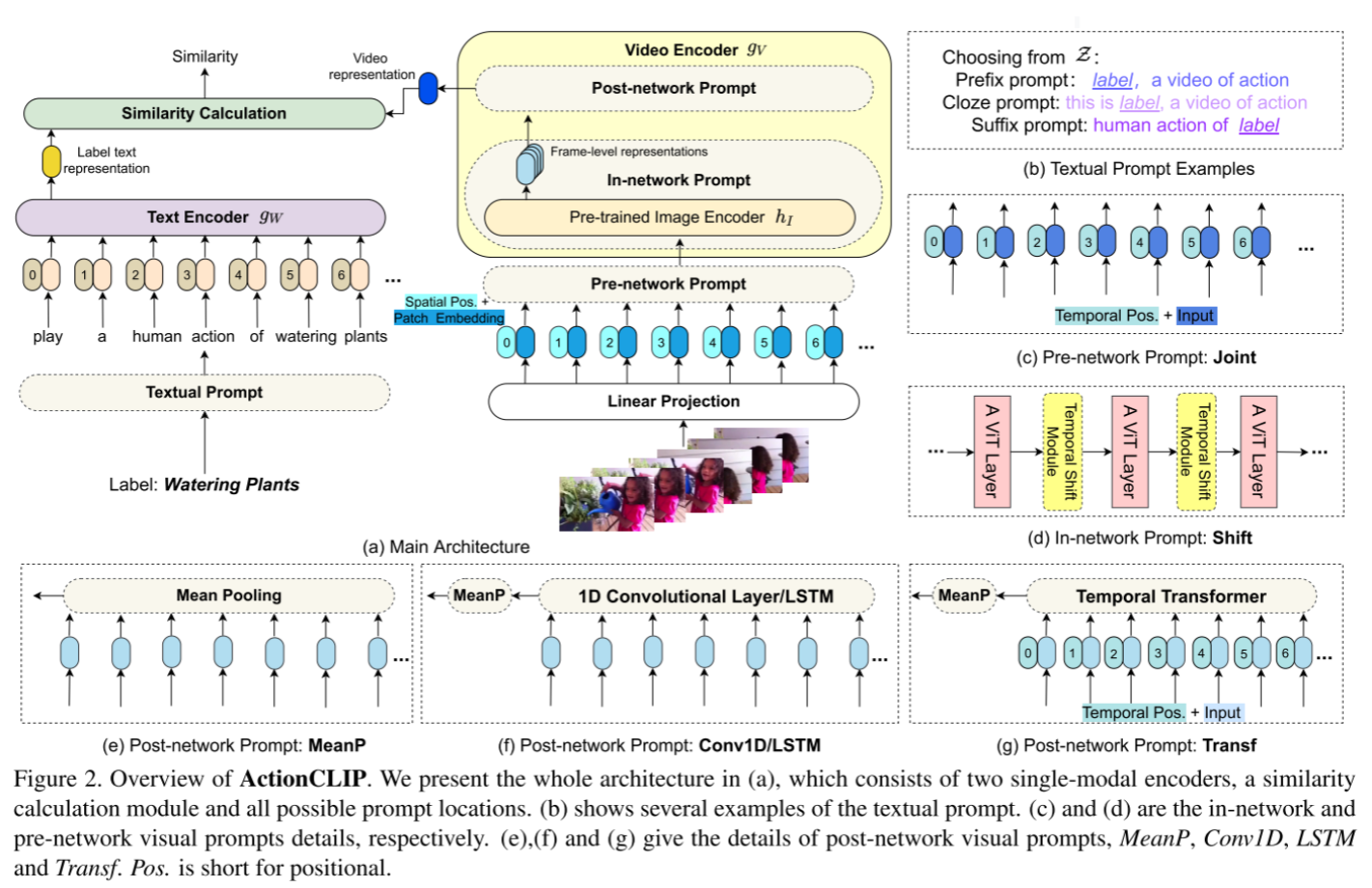
可以参考上图一中的ActionClip的框架。
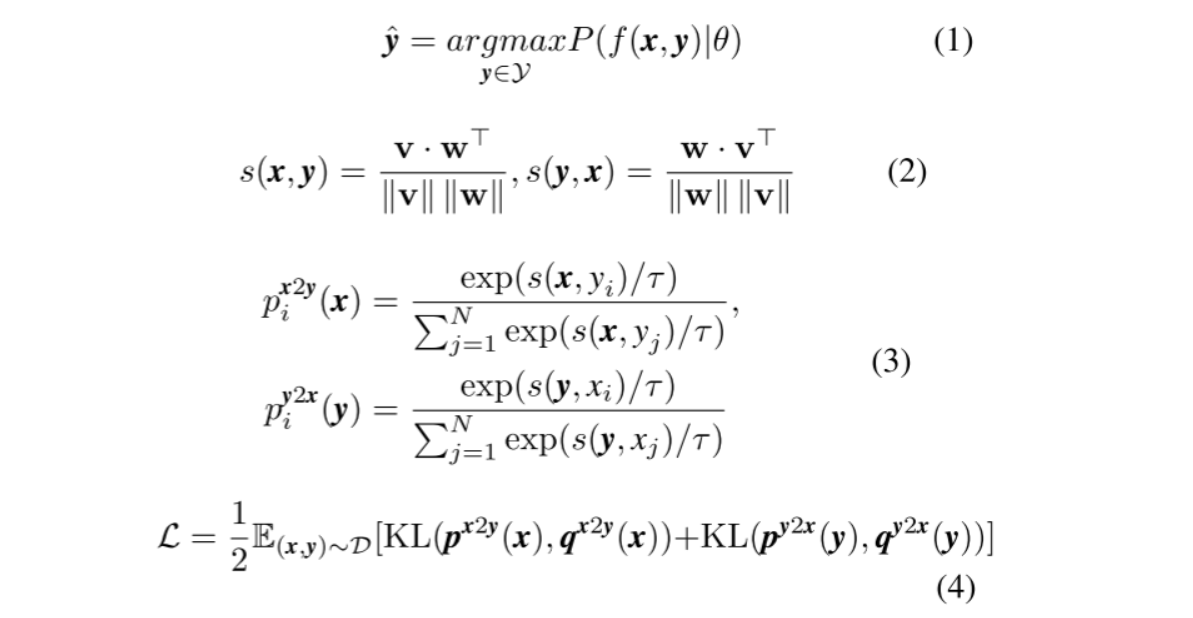
公式的直观理解:
- 公式一:让视频文本的匹配度最高
- 公式二、三:参考CLIP模型,考虑了**“图片->文字”和“文字->图片”的双向关系**,分别计算两者的相似度
- 公式四:KL损失,让计算的相似度的分布和真实标签的分布尽可能接近
新范式
预训练
在预训练过程中主要有三个上游预训练代理任务:多模态匹配( multimodal matching, MM) .多模态对比学习(multimodal contrastive learning, MCL)和掩蔽语言建模(masked language modeling, MLM) 。
-
MM预测- -对模态是否匹配
-
MCL的目的是绘制彼此接近的成对单模态表示
-
MLM利用这两种模态的特征来预测mask的词
然而,由于计算量巨大的限制,本文没有关注这一步骤。 作者直接选择应用预训练的模型,并在以下两个步骤上进行研究。
提示
NLP中的Prompt意味着使用模板将原始输入修改为文本字符串提示,该提示有一些未填充的slot, 以填充预期结果。
在本文中,作者做了两种提示,文本提示(textual prompt )和视觉提示(visual prompt)
- 前者对于标签文本扩展具有重要意义。给定个标签y,首先定义一组允许值,然后通过填充函数获得提示的文本输入,其中。有三种类型:前缀提示(prefix prompt) ,中间提示(cloze prompt)和后缀提示(suffix prompt),它们根据填充位置进行分类。

-
对于视觉提示,其设计主要取决于预训练模型。如果模型在视频文本数据上进行了预训练,则几乎不需要对视觉部分进行额外的重新格式化,
因为模型已经训练为输出视频表示。而如果模型是用图像文本数据预训练的,那么应该让模型学习视频的重要时间关系。
形式上,给定一个视频x,作者引入了提示函数,其中是预训练模型的视觉编码网络。类似地,根据其工作位置分为三种变体:- 网络前提示(pre-network prompt)
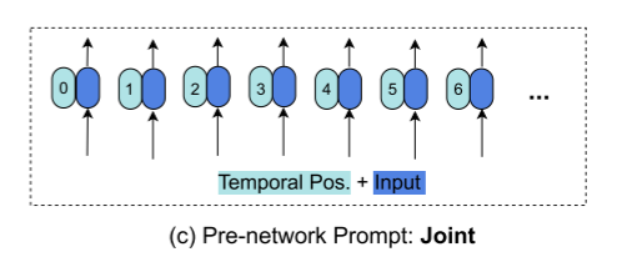
-
网络内提示(in-network prompt)
- Temporal Shift Module:沿着时间维度移动一小部分通道;将TSM插入到残差分支上,保证当前帧的空间特征不会被损害
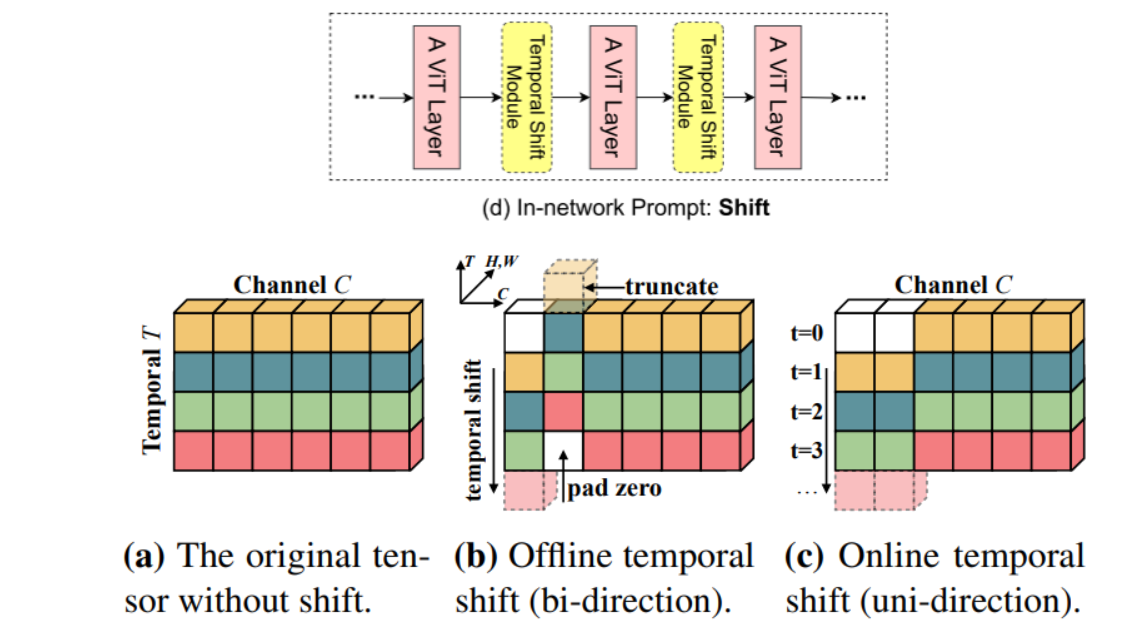
-
网络后提示(post-network prompt)

微调
当有足够的下游训练数据集(如Kinetics)时,毫无疑问,对特定数据集进行微调将大大提高性能。此外,如果提示引入了额外的参数,则有必要训练这些参数并对整个框架进行端到端地学习。
实验
实验细节
我们的文本编码器 g W g_W gW?遵循CLIP的编码器,CLIP是一个12层、512宽的Transformer,具有8个注意力头,并且来自[EOS]处的最高层的激活被视为特征表示 w w w。我们使用CLIP的视觉编码器 h I h_I hI?的ViT-B/32和ViT-B/16。它们都是12层视觉变换器,分别具有32和16的不同输入片段大小。最高层输出的[Class]标记被使用。我们使用 K = 18 K=18 K=18个允许值 Z Z Z进行文本提示。对于视觉提示, C o n v 1 D Conv 1D Conv1D和 L S T M LSTM LSTM的层是1,Transf有 L t L_t Lt?=6层。实现了两个版本的 T r a n s f Transf Transf,它们在不使用或使用[Class] token方面有所不同。我们将它们区分为 T r a n s f Transf Transf和 T r a n s f c l s Transf_{cls} Transfcls?。
训练我们使用AdamW优化器,预训练参数的基本学习率为 5 × 1 0 ? 6 5 × 10^{?6} 5×10?6,具有可学习参数的新模块的基本学习率为 5 × 1 0 ? 5 5 × 10^{?5} 5×10?5。模型使用50个epoch进行训练,权重衰减为0.2。学习率在总训练时期的前10%内预热,并在其余训练期间按照余弦时间表衰减到零。输入帧的空间分辨率为224 × 224。我们使用基于片段的输入帧采样策略,具有8,16或32帧。即使是我们方法中最大的模型ViT-B/16,在输入8帧时,也可以在Kinetics-400上使用4个NVIDIA GeForce RTX 3090 GPU进行训练,训练过程大约需要2.5天。
推理阶段所有实验的输入分辨率均为224×224。我们使用多视图推理,每个视频的3个空间裁剪和10个时间剪辑仅用于最佳性能模型。最终的预测结果来自所有视图的平均相似性得分。
消融实验

结论:多模态框架有助于学习用于动作识别的强大表示。
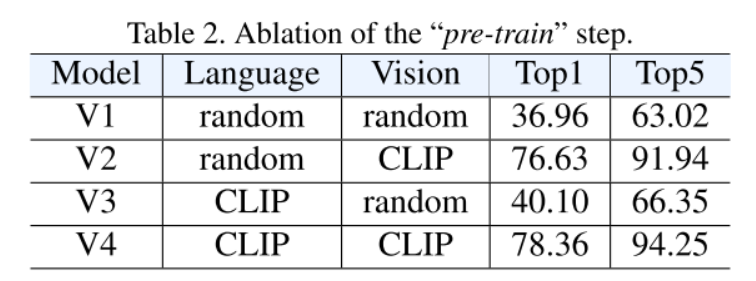
结论:“预训练”步骤是重要的,特别是对于视觉编码器。
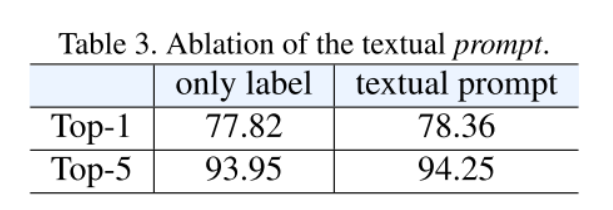
结论:证明了这种简单、离散和人类可理解的文本提示的有效性。
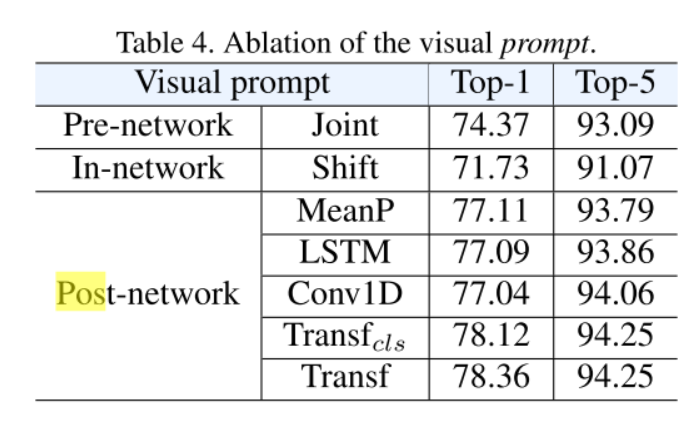
结论:输入模式在 J o i n t Joint Joint中发生了变化,而预先训练的图像编码器 h I h_I hI?的特征在 S h i f t Shift Shift中发生了变化,可能产生灾难性的遗忘现象。提示的指定是重要的,因为适当的提示可以避免灾难性的遗忘并保持现有预训练模型的表示能力,从而为使用大量Web数据提供了捷径。
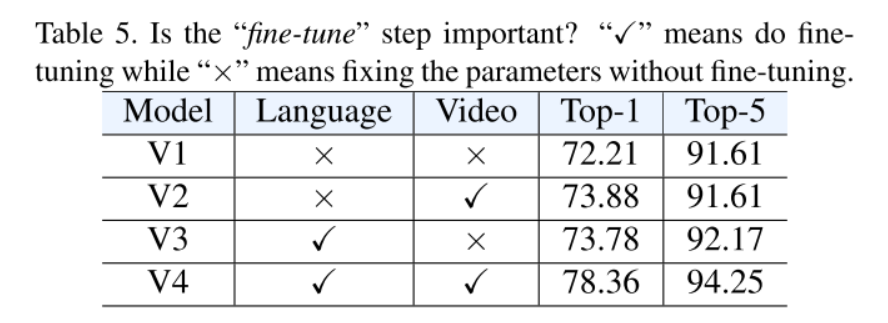
结论:“微调”步骤对于特定的数据集确实至关重要。
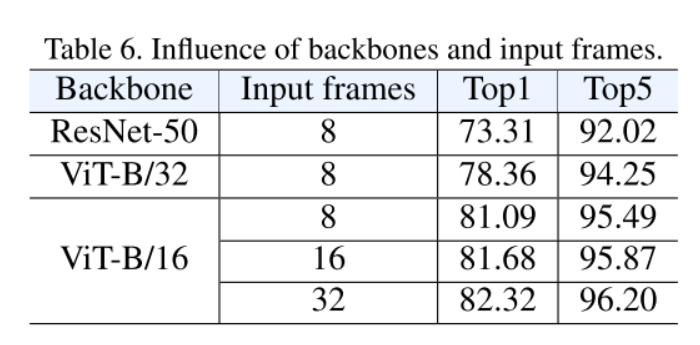
结论:更大的模型和更多的输入帧产生更好的性能。
关键代码
文本提示:
import torch
import clip
def text_prompt(data):
text_aug = [f"a photo of action {{}}", f"a picture of action {{}}", f"Human action of {{}}", f"{{}}, an action",
f"{{}} this is an action", f"{{}}, a video of action", f"Playing action of {{}}", f"{{}}",
f"Playing a kind of action, {{}}", f"Doing a kind of action, {{}}", f"Look, the human is {{}}",
f"Can you recognize the action of {{}}?", f"Video classification of {{}}", f"A video of {{}}",
f"The man is {{}}", f"The woman is {{}}"]
text_dict = {}
num_text_aug = len(text_aug)
for ii, txt in enumerate(text_aug):
text_dict[ii] = torch.cat([clip.tokenize(txt.format(c)) for i, c in data.classes])
classes = torch.cat([v for k, v in text_dict.items()])
return classes, num_text_aug,text_dict
视觉提示:
import torch
from torch import nn
from collections import OrderedDict
from torch.nn.utils.rnn import pad_packed_sequence, pack_padded_sequence
class LayerNorm(nn.Module):
def __init__(self, hidden_size, eps=1e-12):
"""Construct a layernorm module in the TF style (epsilon inside the square root).
"""
super(LayerNorm, self).__init__()
self.weight = nn.Parameter(torch.ones(hidden_size))
self.bias = nn.Parameter(torch.zeros(hidden_size))
self.variance_epsilon = eps
def forward(self, x):
u = x.mean(-1, keepdim=True)
s = (x - u).pow(2).mean(-1, keepdim=True)
x = (x - u) / torch.sqrt(s + self.variance_epsilon)
return self.weight * x + self.bias
class QuickGELU(nn.Module):
def forward(self, x: torch.Tensor):
return x * torch.sigmoid(1.702 * x)
class ResidualAttentionBlock(nn.Module):
def __init__(self, d_model: int, n_head: int, attn_mask: torch.Tensor = None):
super().__init__()
self.attn = nn.MultiheadAttention(d_model, n_head)
self.ln_1 = LayerNorm(d_model)
self.mlp = nn.Sequential(OrderedDict([
("c_fc", nn.Linear(d_model, d_model * 4)),
("gelu", QuickGELU()),
("c_proj", nn.Linear(d_model * 4, d_model))
]))
self.ln_2 = LayerNorm(d_model)
self.attn_mask = attn_mask
def attention(self, x: torch.Tensor):
self.attn_mask = self.attn_mask.to(dtype=x.dtype, device=x.device) if self.attn_mask is not None else None
return self.attn(x, x, x, need_weights=False, attn_mask=self.attn_mask)[0]
def forward(self, x: torch.Tensor):
x = x + self.attention(self.ln_1(x))
x = x + self.mlp(self.ln_2(x))
return x
def trunc_normal_(x, mean=0., std=1.):
# From https://discuss.pytorch.org/t/implementing-truncated-normal-initializer/4778/12
return x.normal_().fmod_(2).mul_(std).add_(mean)
class TAggregate(nn.Module):
def __init__(self, clip_length=None, embed_dim=2048, n_layers=6):
super(TAggregate, self).__init__()
self.clip_length = clip_length
drop_rate = 0.
enc_layer = nn.TransformerEncoderLayer(d_model=embed_dim, nhead=8)
self.transformer_enc = nn.TransformerEncoder(enc_layer, num_layers=n_layers, norm=nn.LayerNorm(
embed_dim))
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
self.pos_embed = nn.Parameter(torch.zeros(1, clip_length + 1, embed_dim))
self.pos_drop = nn.Dropout(p=drop_rate)
with torch.no_grad():
trunc_normal_(self.pos_embed, std=.02)
trunc_normal_(self.cls_token, std=.02)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
with torch.no_grad():
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
def forward(self, x):
nvids = x.shape[0]
cls_tokens = self.cls_token.expand(nvids, -1, -1)
x = torch.cat((cls_tokens, x), dim=1)
x = x + self.pos_embed
x.transpose_(1, 0)
o = self.transformer_enc(x)
return o[0]
class TemporalTransformer(nn.Module):
def __init__(self, width: int, layers: int, heads: int, attn_mask: torch.Tensor = None):
super().__init__()
self.width = width
self.layers = layers
self.resblocks = nn.Sequential(*[ResidualAttentionBlock(width, heads, attn_mask) for _ in range(layers)])
def forward(self, x: torch.Tensor):
return self.resblocks((x))
class visual_prompt(nn.Module):
def __init__(self, sim_head, clip_state_dict, T):
super().__init__()
self.sim_header = sim_head
self.T = T
assert sim_head in ["meanP", "LSTM", "Transf", "Conv_1D", "Transf_cls"]
if self.sim_header == "LSTM" or self.sim_header == "Transf" or self.sim_header == "Transf_cls" or self.sim_header == "Conv_1D" :
embed_dim = clip_state_dict["text_projection"].shape[1]
context_length = clip_state_dict["positional_embedding"].shape[0]
vocab_size = clip_state_dict["token_embedding.weight"].shape[0]
transformer_width = clip_state_dict["ln_final.weight"].shape[0]
transformer_heads = transformer_width // 64
transformer_layers = len(
set(k.split(".")[2] for k in clip_state_dict if k.startswith(f"transformer.resblocks")))
self.frame_position_embeddings = nn.Embedding(context_length, embed_dim)
if self.sim_header == "Transf" :
self.transformer = TemporalTransformer(width=embed_dim, layers=6, heads=transformer_heads)
print('layer=6')
if self.sim_header == "LSTM":
self.lstm_visual = nn.LSTM(input_size=embed_dim, hidden_size=embed_dim,
batch_first=True, bidirectional=False, num_layers=1)
self.apply(self.init_weights)
if self.sim_header == "Transf_cls":
self.transformer = TAggregate(clip_length=self.T, embed_dim=embed_dim, n_layers=6)
if self.sim_header == 'Conv_1D' :
self.shift = nn.Conv1d(embed_dim, embed_dim, 3, padding=1, groups=embed_dim, bias=False)
weight = torch.zeros(embed_dim, 1, 3)
weight[:embed_dim // 4, 0, 0] = 1.0
weight[embed_dim // 4:embed_dim // 4 + embed_dim // 2, 0, 1] = 1.0
weight[-embed_dim // 4:, 0, 2] = 1.0
self.shift.weight = nn.Parameter(weight)
def init_weights(self, module):
""" Initialize the weights.
"""
if isinstance(module, (nn.Linear, nn.Embedding)):
# Slightly different from the TF version which uses truncated_normal for initialization
# cf https://github.com/pytorch/pytorch/pull/5617
module.weight.data.normal_(mean=0.0, std=0.02)
elif isinstance(module, LayerNorm):
if 'beta' in dir(module) and 'gamma' in dir(module):
module.beta.data.zero_()
module.gamma.data.fill_(1.0)
else:
module.bias.data.zero_()
module.weight.data.fill_(1.0)
if isinstance(module, nn.Linear) and module.bias is not None:
module.bias.data.zero_()
def forward(self, x):
b, t, c = x.size()
x = x.contiguous()
if self.sim_header == "meanP":
pass
elif self.sim_header == 'Conv_1D':
x_original = x
x = x.view(-1, c, t)
x = self.shift(x.float())
x = x.permute(0, 2, 1)
x = x.type(x_original.dtype) + x_original
elif self.sim_header == "Transf":
x_original = x
seq_length = t
position_ids = torch.arange(seq_length, dtype=torch.long, device=x.device)
position_ids = position_ids.unsqueeze(0).expand(x.size(0), -1)
frame_position_embeddings = self.frame_position_embeddings(position_ids)
x = x + frame_position_embeddings
x = x.permute(1, 0, 2) # NLD -> LND
x = self.transformer(x)
x = x.permute(1, 0, 2) # LND -> NLD
x = x.type(x_original.dtype) + x_original
elif self.sim_header == "LSTM":
x_original = x
x, _ = self.lstm_visual(x.float())
self.lstm_visual.flatten_parameters()
x = torch.cat((x, x_original[:, x.size(1):, ...].contiguous()), dim=1)
x = x.type(x_original.dtype) + x_original
elif self.sim_header == "Transf_cls":
x_original = x
return self.transformer(x).type(x_original.dtype)
else:
raise ValueError('Unknown optimizer: {}'.format(self.sim_header))
return x.mean(dim=1, keepdim=False)
总结
本文将动作识别看作是一个视频-文本多模态学习问题,为动作识别提供了一个新的视角。与将任务建模为视频单模态分类问题的规范方法不同,我们提出了一个多模态学习框架来利用标签文本的语义信息。然后,我们制定了一个新的范式,即,“预训练、提示、微调”,使我们的框架能够直接重用强大的大规模Web数据预训练模型,大大降低了预训练成本。
相关参考
TSM: Temporal Shift Module for Efficient Video Understanding
CV大模型系列之:多模态经典之作CLIP,探索图文结合的奥秘
STM: SpatioTemporal and Motion Encoding for Action Recognition
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!