【LeetCode刷题笔记(9-1)】【Python】【无重复字符的最长子串】【滑动窗口】【中等】
无重复字符的最长子串
引言
编写通过所有测试案例的代码并不简单,通常需要深思熟虑和理性分析。虽然这些代码能够通过所有的测试案例,但如果不了解代码背后的思考过程,那么这些代码可能并不容易被理解和接受。我编写刷题笔记的初衷,是希望能够与读者们分享一个完整的代码是如何在逐步的理性思考下形成的。我非常欢迎读者的批评和指正,因为我知道我的观点可能并不完全正确,您的反馈将帮助我不断进步。如果我的笔记能给您带来哪怕是一点点的启示,我也会感到非常荣幸。同时,我也希望我的分享能够激发您的灵感和思考,让我们一起在编程的道路上不断前行~
无重复字符的最长子串
题目描述
给定一个字符串 s ,请你找出其中不含有重复字符的 最长子串 的长度。
示例 1:
- 输入: s = “abcabcbb”
- 输出: 3
- 解释: 因为无重复字符的最长子串是 “abc”,所以其长度为 3。
示例 2:
- 输入: s = “bbbbb”
- 输出: 1
- 解释: 因为无重复字符的最长子串是 “b”,所以其长度为 1。
示例 3:
- 输入: s = “pwwkew”
- 输出: 3
- 解释: 因为无重复字符的最长子串是 “wke”,所以其长度为 3。
提示
- 答案必须是 子串 的长度,“pwke” 是一个子序列,不是子串。
- n == height.length
- 1 <= n <= 2 * 104
- 0 <= height[i] <= 105
解决方案1:【滑动窗口】
根据题意,解决问题的关键是如何在字符串 s 中找到其中不含有重复字符的 最长子串 的长度。且根据提示,【子串】必须是索引连续的字符串。当脑海中没有明确idea时,分析示例可能会带来灵感~
- 在示例3,字符串
s="pwwkew",当我们从左往右遍历字符串时,遇到的第一个不含有重复字符的子串是"pw",此时最长子串长度max_len=2;随后,当遍历到第三个字符"w"时,出现了重复,此时应该舍弃"pw",从第三个字符"w"为起点,重新寻找第二个不含有重复字符的子串"wke", 此时最长子串长度max_len=3;最后,当遍历到最后一个字符"w"时,此时应该舍弃子串"wke"中的"w",让"ke"和最后一个字符"w"组成最后一个不含有重复字符的子串是"kew", 此时最长子串长度max_len=3。
从示例3中,我们可以总结出以下规律:
- 首先,我们需要选择一种能够方便获取元素长度的数据结构存储当前“子串”,以便获取其长度来及时更新
max_len。 - 其次,这种数据结构应具备查找元素的功能,以便判断新元素是否存在于当前子串中。
- 若新元素存在当前子串 ? 即将出现重复元素,如示例三的新元素
"w"和当前子串"wke"? 需要先舍弃子串"wke"中的第一个元素"w",而这个被舍弃的"w"也是首先进入这种数据结构的字符 ? 需要一种能够实现“先进先出”的数据结构 ? 利用【队列】存储子串,当舍弃掉队列头部的"w"后,再把新的"w"添加到队列的尾部,组成新的子串"kew"; - 若新元素不存在当前子串 ? 直接把新元素添加到队列尾部即可。
- 若新元素存在当前子串 ? 即将出现重复元素,如示例三的新元素
问题1:在python中,什么数据对象可以实现【队列】这种数据结构?
列表
问题2:上面叙述的流程有没有一个约定俗成的算法名称?
有!滑动窗口法
由于队列中的元素个数是随着遍历字符串s不断增加/删除的,且队列的长度也在不断发生变化 ? 我们可以将队列想象成一个不定长窗口,在字符串s上按照从左往右的顺序进行滑动 ? 滑动窗口法
完整代码如下:
class Solution:
def lengthOfLongestSubstring(self, s: str) -> int:
# 用列表对象初始化一个空队列
queue = []
# 初始化最大长度为0
max_len = 0
# 遍历字符串s的每个字符
for c in s:
# 如果当前字符在队列中 ---> 出现重复
while c in queue:
# 从队列的头部不断删除字符,直到当前字符不存在于队列中
queue.pop(0)
# 由于当前字符不存在于队列中,将当前字符添加到队列尾部
queue.append(c)
# 如果队列的长度大于最大长度
if len(queue) > max_len:
# 更新最大长度为队列的长度
max_len = len(queue)
# 返回最大长度
return max_len
运行结果:

问题3:从运行结果来看,似乎还有很大的优化空间,可以从哪些方面入手优化呢?
- 换一个查找速度更快的数据结构存储“子串”。
由于当前队列是基于列表进行实现的,而列表中查找元素的时间复杂度是O(n)。有没有查找元素的时间复杂度更低的数据结构,并且也能实现队列?
有!基于哈希表的集合对象set(),但需要额外的变量进行辅助。
完整代码如下:
class Solution:
def lengthOfLongestSubstring(self, s: str) -> int:
# 如果字符串为空,返回0
if not s:
return 0
# 初始化变量
n = len(s)
look_up = set() # 用于存储当前子字符串
cur_len = 0 # 当前子字符串的长度
max_len = 0 # 最长子字符串的长度
left = 0 # 滑动窗口的左边界
# 遍历字符串
for i in range(n):
# 如果当前字符在已出现的字符集中,则需要移动左边界并缩小当前子字符串的长度
while s[i] in look_up:
look_up.remove(s[left]) # 队列移除头部元素,left指向的就是头部元素所在位置
cur_len -= 1
left += 1
# 将当前字符添加到字符集中,并增加当前子字符串的长度
look_up.add(s[i])
cur_len += 1
# 如果当前子字符串的长度大于最长子字符串的长度,则更新最长子字符串的长度
if cur_len > max_len:
max_len = cur_len
# 返回最长子字符串的长度
return max_len
运行结果:

问题4:从运行结果来看,已经有一定程度的优化,还能在进一步优化吗?
- 当最大无重复子串长度
max_len已经大于当前子串长度cur_len和字符串s尚未遍历的元素个数n-i之和时,可以提前终止遍历,并返回结果。
完整代码如下:
class Solution:
def lengthOfLongestSubstring(self, s: str) -> int:
# 如果字符串为空,返回0
if not s:
return 0
# 初始化变量
n = len(s)
look_up = set() # 用于存储已经出现过的字符
cur_len = 0 # 当前子字符串的长度
max_len = 0 # 最长子字符串的长度
left = 0 # 滑动窗口的左边界
# 遍历字符串
for i in range(n):
# 如果当前字符在已出现的字符集中,则需要移动左边界并缩小当前子字符串的长度
while s[i] in look_up:
look_up.remove(s[left])
cur_len -= 1
left += 1
# 将当前字符添加到字符集中,并增加当前子字符串的长度
look_up.add(s[i])
cur_len += 1
# 如果当前子字符串的长度大于最长子字符串的长度,则更新最长子字符串的长度
if cur_len > max_len:
max_len = cur_len
# 最大无重复子串长度max_len已经大于等于当前子串长度cur_len和字符串s尚未遍历的元素个数n-i之和时,退出for循环
if cur_len + (n-i) <= max_len:
break
# 返回最长子字符串的长度
return max_len
运行结果:
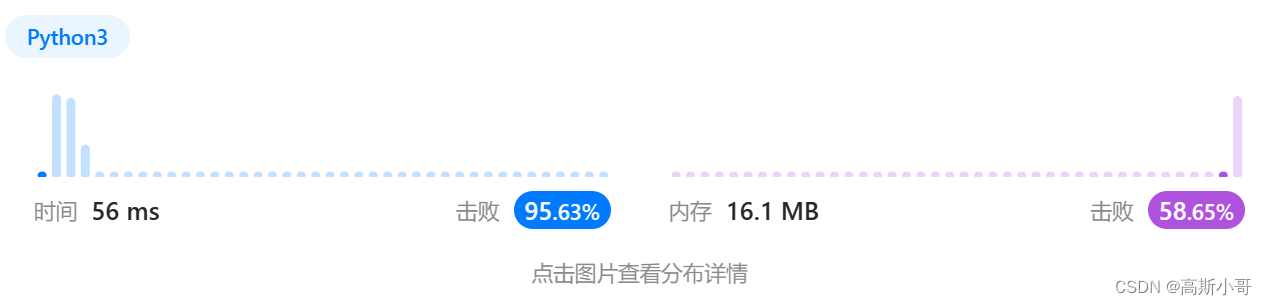
复杂度分析
- 时间复杂度:O(N),其中 N 是字符串
s元素的数量。 - 空间复杂度:参考官方题解
结束语
- 亲爱的读者,感谢您花时间阅读我们的博客。我们非常重视您的反馈和意见,因此在这里鼓励您对我们的博客进行评论。
- 您的建议和看法对我们来说非常重要,这有助于我们更好地了解您的需求,并提供更高质量的内容和服务。
- 无论您是喜欢我们的博客还是对其有任何疑问或建议,我们都非常期待您的留言。让我们一起互动,共同进步!谢谢您的支持和参与!
- 我会坚持不懈地创作,并持续优化博文质量,为您提供更好的阅读体验。
- 谢谢您的阅读!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!