慢SQL的治理经验
其他系列文章导航
文章目录
前言
在当今的数字化时代,数据库已经成为企业不可或缺的核心组件。
然而,随着数据量的不断增加和查询的复杂性提高,慢查询成为了数据库性能的瓶颈之一。慢SQL不仅会影响系统的响应速度,还可能导致数据丢失或损坏,给企业带来巨大的损失。因此,慢SQL的治理成为了数据库管理的重要任务之一。
本文将分享一些慢SQL的治理经验,包括如何识别、分析和优化慢查询。通过了解慢查询的原因和解决方法,我们可以提高数据库的性能和稳定性,为企业的业务发展提供更好的支持。
一、慢SQL导致的后果
我一般认为的慢SQL的定义,执行超过1s的SQL为慢SQL。
- 系统的响应时间延迟,影响用户体验。
- 资源占用增加,增高了系统的负载,其他请求响应时间也可能会收到影响。
- 慢SQL占用数据库连接的时间长,如果有大量慢SQL查询同时执行,可能会导致数据库连接池的连接被全部占用,导致数据连接池打满、缓冲区溢出等问题,使数据库无法响应其他请求。
- 还有可能造成锁竞争增加、数据不一致等问题。
二、可能导致慢SQL的原因
- 缺乏索引/索引未生效,导致数据库全表扫描,会产生大量的IO消耗,产生慢SQL。
- 单表数据量太大,会导致加索引的效果不够明显。
- SQL语句书写不当,例如join或者子查询过多、in元素过多、limit深分页问题、order by导致文件排序、group by使用临时表等。
- 数据库在刷“脏页”,redo log写满了,导致所有系统更新被堵住,无法写入了。
- 执行SQL的时候,遇到表锁或者行锁,只能等待锁被释放,导致了慢SQL。
三、如何发现慢SQL
3.1?JVM Sandbox
今天介绍一下基于JVM Sandbox进行SQL流水记录的采集。
这是一个全量采集,起到预防的作用。
关于JVM Sandbox的定义:「JVM-Sandbox提供动态增强你所指定的类,获取你想要的参数和行信息;提供动态可插拔容器,管理基于JVM-Sandbox的模块。」
简单来说,JVM Sandbox可以动态地将你要实现的代码模板打包编织到目标代码中,实现事件的监听、切入与代码增强。将目标代码的Java方法的调用分解为BEFORE、RETURN和THROWS三个环节,由此在三个环节上引申出对应环节的事件探测和流程控制机制。不仅如此,还有Line事件,可以完成代码行的记录。
如下所示:
// BEFORE-EVENT
try {
/*
* do something...
*/
//LINE-EVENT
a();
// RETURN-EVENT
return;
} catch (Throwable cause) {
// THROWS-EVENT
}jvm-sandbox-repeater是JVM-sandbox生态体系下的重要模块,具备了JVM-Sandbox所有特点, 封装请求录制/回放基础协议,也提供了通用可拓展的丰富API。
repeator模块可以无侵入式地录制HTTP/Java/Dubbo入参/返回值,业务系统无感知。基于这个能力,我们可以方便的采集和SQL执行相关的Java方法参数以及返回值。通过配置采集点,来采集执行sql的java代码的相关方法、参数和返回值,辅助实现sql采集功能。
-
确认采集点
根据对MyBatis源码分析,我们确认了如下采集点:

JVMSandbox完成数据采集后,通过发送metaq消息的方式,与系统进行对话。对于不同种类的采集消息,我们通过不同的字段加以匹配,最终可以获得每一条SQL流水对应的SQL文本、执行时长、sql参数、db名称、ip端口、sql_mapper资源文件等全部信息。?
四、识别高危SQL
4.1 阿里的重点强制SQL规约
规约如下:
【强制】不要使用count(列名)或count(常量)来替代count(*),count(*)就是SQL92定义的标准统计行数的语法,跟数据库无关,跟NULL和非NULL无关。
【强制】count(distinct col) 计算该列除NULL之外的不重复数量。注意 count(distinct col1, col2) 如果其中一列全为NULL,那么即使另一列有不同的值,也返回为0。
【强制】当某一列的值全是NULL时,count(col)的返回结果为0,但sum(col)的返回结果为NULL,因此使用sum()时需注意NPE问题。
【强制】使用ISNULL()来判断是否为NULL值。
【强制】对于数据库中表记录的查询和变更,只要涉及多个表,都需要在列名前加表的别名(或表名)进行限定。
【强制】在代码中写分页查询逻辑时,若count为0应直接返回,避免执行后面的分页语句。
【强制】不得使用外键与级联,一切外键概念必须在应用层解决。
【强制】禁止使用存储过程,存储过程难以调试和扩展,更没有移植性。
【强制】IDB数据订正(特别是删除或修改记录操作)时,要先select,避免出现误删除,确认无误才能提交执行。
可以使用Druid SQL Parser进行SQL解析,Druid SQL Parser是阿里巴巴的开源项目,可以将SQL语句解析为语法树,可以解析SQL的各个部分,如SELECT语句、FROM语、WHERE语句等,并且可以方便获取SQL语句的结构信息,如表名、列名、操作符等。通过分析SQL,可以轻松判断SQL是否符合规约。
4.2 SQL explain语句
SQL explain语句可以提供关于SQL查询执行的详细信息和执行计划,并且可以了解sql的索引使用情况以及数据访问方式。通过使用Explain语句,可以了解SQL是如何执行的,并且可以看出其可能存在的性能问题。
一个常见的返回结果示例如下:

返回结果解析:
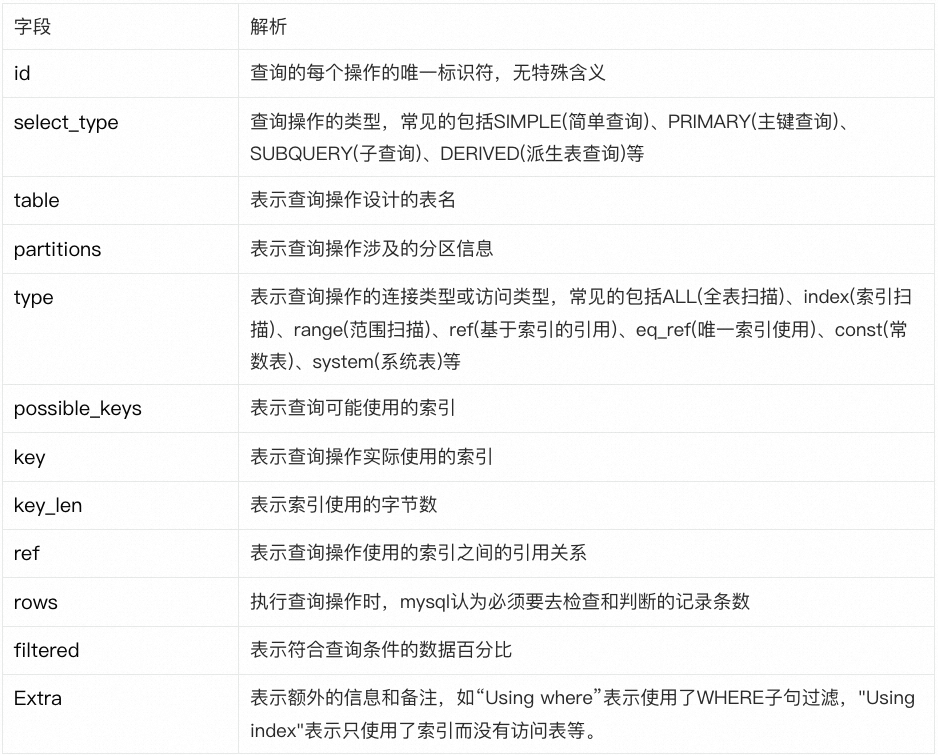
我们重点关注的点如下:
-
使用全表扫描,性能最差,即type="ALL"
-
扫描行数过多,即rows>阈值
-
查询时使用了排序操作,也比较耗时,即Extra包含"Using filesort"
-
索引类型为index,代表全盘扫描了索引的数据,Extra信息为Using where,代表要搜索的列没有被索引覆盖,需要回表,性能较差。
以上几点都可能造成SQL性能的劣化,是我们需要额外关注的高风险sql。
五、总结
总之,慢 SQL 治理需要综合考虑多个方面,包括查询语句优化、参数调整、分区和分片、缓存使用、定期维护和优化、分布式数据库解决方案等。通过这些措施的实施,可以提高数据库的性能和稳定性,提升应用程序的用户体验。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!