16-高并发-队列术
队列,在数据结构中是一种线性表,从一端插入数据,然后从另一端删除数据。
在我们的系统中,不是所有的处理都必须实时处理,不是所有的请求都必须实时反馈结果给用户,不是所有的请求都必须100%一次性处理成功,不知道哪个系统依赖“我”来实现其业务处理,保证最终一致性,不需要强一致性。
此时,我们应该考虑使用队列来解决这些问题。当然我们也要考虑是否需要保证消息处理的有序性及如何保证,是否能重复消费及如何保证重复消费的幂等性。
在实际开发时,我们经常使用队列进行异步处理、系统解耦、数据同步、流量削峰、扩展性、缓冲等。
应用场景
异步处理
使用队列的一个主要原因是进行异步处理,比如,用户注册成功后,需要发送注册成功邮件/新用户积分/优惠券等;缓存过期时,先返回过期数据,然后异步更新缓存、异步写日志等。
通过异步处理,可以提升主流程响应速度,而非主流程/非重要处理可以集中处理,这样还可以将任务聚合批量处理。
因此,可以使用消息队列/任务队列来进行异步处理。
系统解耦
比如,用户成功支付完成订单后,需要通知生产配货系统、发票系统、库存系统、推荐系统、搜索系统等进行业务处理,而未来需要支持哪些业务是不知道的,并且这些业务不需要实时处理、不需要强一致,只需要保证最终一致性即可,因此,可以通过消息队列/任务队列进行系统解耦。
数据同步
比如,想把MySQL变更的数据同步到Redis,或者将MySQL的数据同步到Mongodb,或者让机房之间的数据同步,或者主从数据同步等,此时可以考虑使用databus、canal、otter等。
使用数据总线队列进行数据同步的好处是可以保证数据修改的有序性。
流量削峰
系统瓶颈一般在数据库上,比如扣减库存、下单等。
此时可以考虑使用队列将变更请求暂时放入队列,通过缓存+队列暂存的方式将数据库流量削峰。
同样,对于秒杀系统,下单服务会是该系统的瓶颈,此时,可以使用队列进行排队和限流,从而保护下单服务,通过队列暂存或者队列限流进行流量削峰。
队列的应用场景非常多,以上只列举了一些常见用法和场景。
缓冲队列
典型的如Log4j日志缓冲区,当我们使用log4j记录日志时,可以配置字节缓冲区,字节缓存区满时,会立即同步到磁盘。
Log4j是使用BufferedWriter实现的。
此模式不是异步写,在缓冲区满的时候还是会阻塞主线程。
如果需要异步模式,则可以使用AsyncAppender,然后通过bufferSize控制日志事件缓冲区大小。
同样,在电商进行大促时,此时的系统流量会高于平常流量的几倍甚至几十倍,此时应进行一些特殊的设计来保证系统平稳度过这段时期。
而解决的手段很多,一般牺牲业务的强一致性,保证最终一致性即可。
如下图所示,使用缓冲队列应对突发流量时,并不能使处理速度变快,而是使处理速度变平滑,从而不会因瞬间压力太大而压垮应用。

任务队列
使用任务队列可以将一些不需要与主线程同步执行的任务扔到任务队列进行异步处理。
用得最多的是线程池任务队列(默认为LinkedBlockingQueue)和Disruptor任务队列(RingBuffer)。
如用户注册完成后,将发送邮件/送积分/送优惠券任务扔到任务队列进行异步处理;刷数据时,将任务扔到队列异步处理,处理成功后再异步通知用户。
还有删除SKU操作,在用户请求时直接将任务分解并扔到队列进行异步处理,处理成功后异步通知用户。
以及查询聚合时,将多个可并行处理的任务扔到队列,然后等待最慢的一个任务返回。
通过任务队列可以实现异步处理、任务分解/聚合处理。
消息队列
使用消息队列存储各业务数据,其他系统根据需要订阅即可。
常见的订阅模式是:点对点(一个消息只有一个消费者)、发布订阅(一个消息可以有多个消费者)。而常用的是发布订阅模式。
比如,修改商品数据、变更订单状态时,都应该将变更信息发送到消息队列,如果其他系统有需要,则直接订阅该消息队列即可。
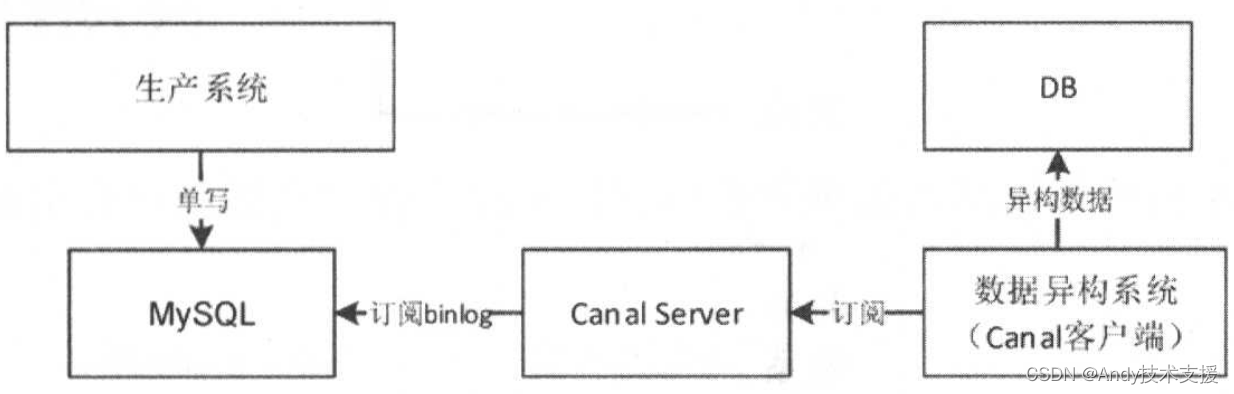
一般我们会在应用系统中采用双写模式,同时写DB和MQ,然后异构系统可以订阅MQ进行业务处理(见下图)。

因为在双写模式下没有事务保证,所以会出现数据不一致的情况,如果对一致性要求没那么严格,则这种模式是没问题的,而且在实际应用中这种模式也非常多。
如果在事务中发MQ,会存在事务回滚,但是MQ发送成功了,则需要消息消费者进行幂等处理。
如果事务提交慢,但是MQ已经发出去了,则此时根据MQ信息再去获取数据库数据可能不是最新的。如果MQ发送慢,则会导致事务无法快速提交,造成数据库堵塞。同样不要在事务中掺杂RPC调用,RPC服务不稳定,同样会引起数据库阻塞。
也可以采用订阅数据库日志机制来实现数据库变更捕获,这样生产系统只需要单写DB,然后通过如Canal订阅数据库binlog实现数据库数据变更捕获,然后业务端订阅Canal进行业务处理。这种方式可以保证一致性。
请求队列
请求队列是指类似在Web环境下对用户请求排队,从而进行一些特殊控制:流量控制、请求分级、请求隔离。例如将请求按照功能划分到不同的队列,从而使得不同的队列出现问题后相互不影响。
还可以对请求分级,一些重要的请求可以优先处理(发展到一定程度应将功能物理分离)。
另外,服务器处理能力有限,在接近服务器瓶颈时需要考虑限流,最简单的限流是丢弃处理不了的请求,此时可以使用队列进行流量控制。
如下图所示,这里使用请求队列来实现漏斗模式,对请求进行排队、过滤、限流,经过这些步骤后,流入业务系统的流量就非常小了,这样业务系统就不会被突发的大量请求搞垮。
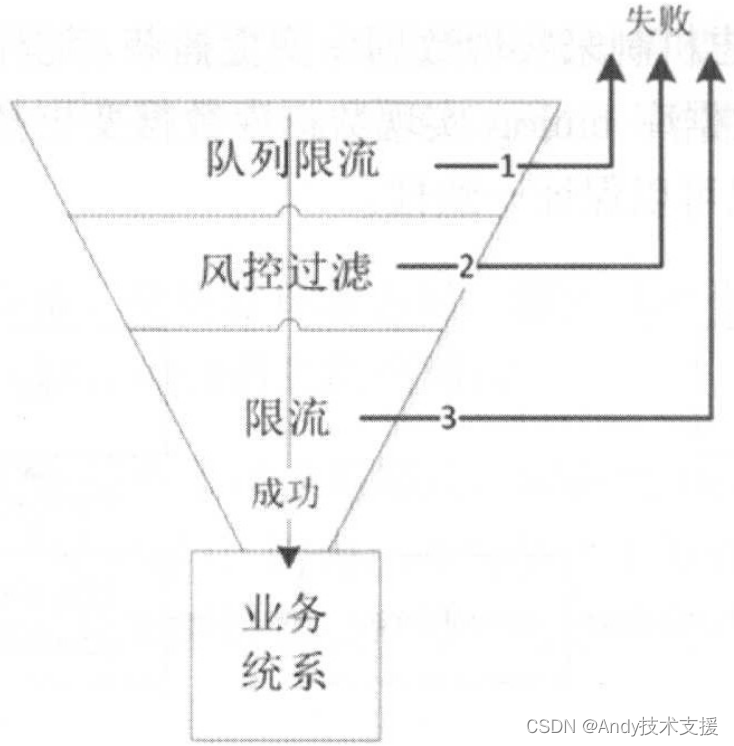
队列限流可以通过队列大小(如果队列满了,就抛弃新的请求)和排队超时(队列里的请求很长时间没被处理)实现,如果失败了,则返回让客户重新排队或者重试。
使用这种机制可以很好地保护系统不会受到突发流量的冲击。这种机制一般用于前端入口。
数据总线队列
一般消息队列中的消息都是业务维度的简单数据,如业务键或业务状态。
在商品信息变更场景中,当SKU信息变更了,只下发一个SKU ID,订阅者需要再查一遍商品系统来获取最新的变更数据,进行如商品信息缓存同步。
所以使用现有的消息队列方式很难只进行变更部分的推送并保证数据的有序性。
而此种场景比较适合使用数据总线队列实现。
例如数据库变更后需要同步数据到缓存,或者需要将一个机房的数据同步到另一个机房,只是数据维度的同步,此时应该使用数据总线队列,如阿里的Canal、LinkedIn的databus。
使用数据总线队列的好处是,可以保证数据的有序性。
阿里的otter是基于Canal的一款分布式数据库同步系统,如果想实时进行多机房、多数据库数据增量同步,则可以使用otter。
如果需要全量离线数据同步,则可以使用kettle。
可以通过otter订阅某个DB的某些表,然后同步到另一个数据库中。
如果系统中存在一些基础数据,则可以使用这种方式进行同步(见下图)。

混合队列
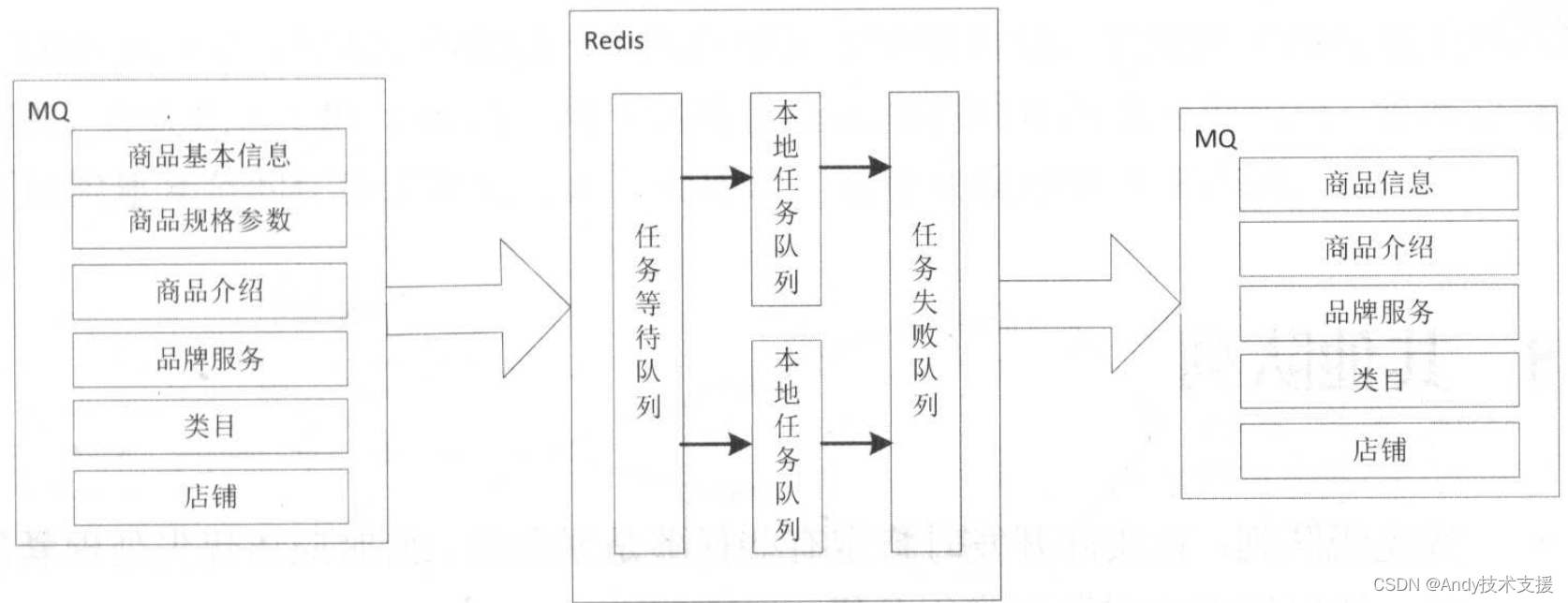
应用会按照不同的维度发布消息到MQ。
下游应用接收到该消息后会将其放入Redis中,使用RedisList来存储这些任务。应用将Redis消息消费处理后,会按照不同的维度聚合商品消息,然后再次发送出去。
使用Redis队列的主要原因是想提升消息堆积能力和并发处理能力。
另外,在使用Redis构建消息队列时,需要考虑因网络抖动造成的消息丢失问题,因为Redis是没有事务回滚的,或者说是没有确认机制的。
而对于失败我们会进行三次重试,重试失败后放入失败队列,而失败队列是具有防重功能的(从本地队列和失败队列排重),这里使用Redis Lua脚本实现。
其他队列
优先级队列
在实际开发时肯定有些任务是紧急的,此时应该优先处理紧急任务。所以请考虑对队列进行分级。
副本队列
在进行一些系统重构或者上新的功能时,如果没有足够的信心保证业务逻辑正确,则可以考虑存储一份队列的副本(比如1小时、1天的消息),从而当业务出现问题时,可以对这些消息进行回放。
镜像队列
每个队列不可能无限制被订阅消费,会有一个订阅量极限。当达到极限时,请考虑使用镜像队列方式解决该问题。
队列并发数
不同队列实现,队列服务器端并发连接数是不一样的。
一定不是增大队列并发连接数消费能力也随着增加,也不会因为增加了消费服务器消费,并发能力也随之增加,需要根据实际情况来设置合理的并发连接数。
推送拉取
消息体内容不是越全越好,需要根据具体业务设计消息体。
如有些系统依赖商品变更消息(只有一个SKU),有些系统依赖商品状态消息(SKU、状态),有些系统依赖商品属性变更消息(SKU、变更的属性)等。
如果让所有系统都消费商品变更消息,那么这些系统都会调用商品查询服务,拉取最新商品信息,然后进行处理。
因此,要根据实际情况来决定是使用推送方式(将系统需要的所有信息推过去)还是使用拉取方式(只推送ID,然后再查一遍)。
下单系统水平可扩展架构
订单系统是交易型网站的核心之一,用户会在这类网站上浏览并购买商品,购买后就会产生订单,接着需要用户进行支付,支付成功后就进入生产流程。
而这其中最重要的一步就是能让用户先下单并成功支付,而后续流程可以不用实时处理。
因此,如何保证下单功能的高性能和高可用是一个交易型网站的核心之一,当然这对于其他系统也同等重要。
一般订单系统会进行分库分表,如果分库分表的数量不够,则会影响到系统的性能,一般通过扩容来解决。或者当同一个订单库被多个系统依赖,其中某个系统有慢操作时,以及当一次下单需要写很多表并且订单量较大时,这都会造成用户下单速度变慢,甚至无法下单。
如果把订单放入缓冲队列,然后能迅速同步到订单中心,那么就可以把下单逻辑和操作订单逻辑分开,用户下单只操作缓冲表,而操作订单只操作订单表,从而在操作订单表时不会影响到缓冲表。
而且缓冲表可以通过水平扩容来支持更大请求。下图是我们的订单系统的整体架构。
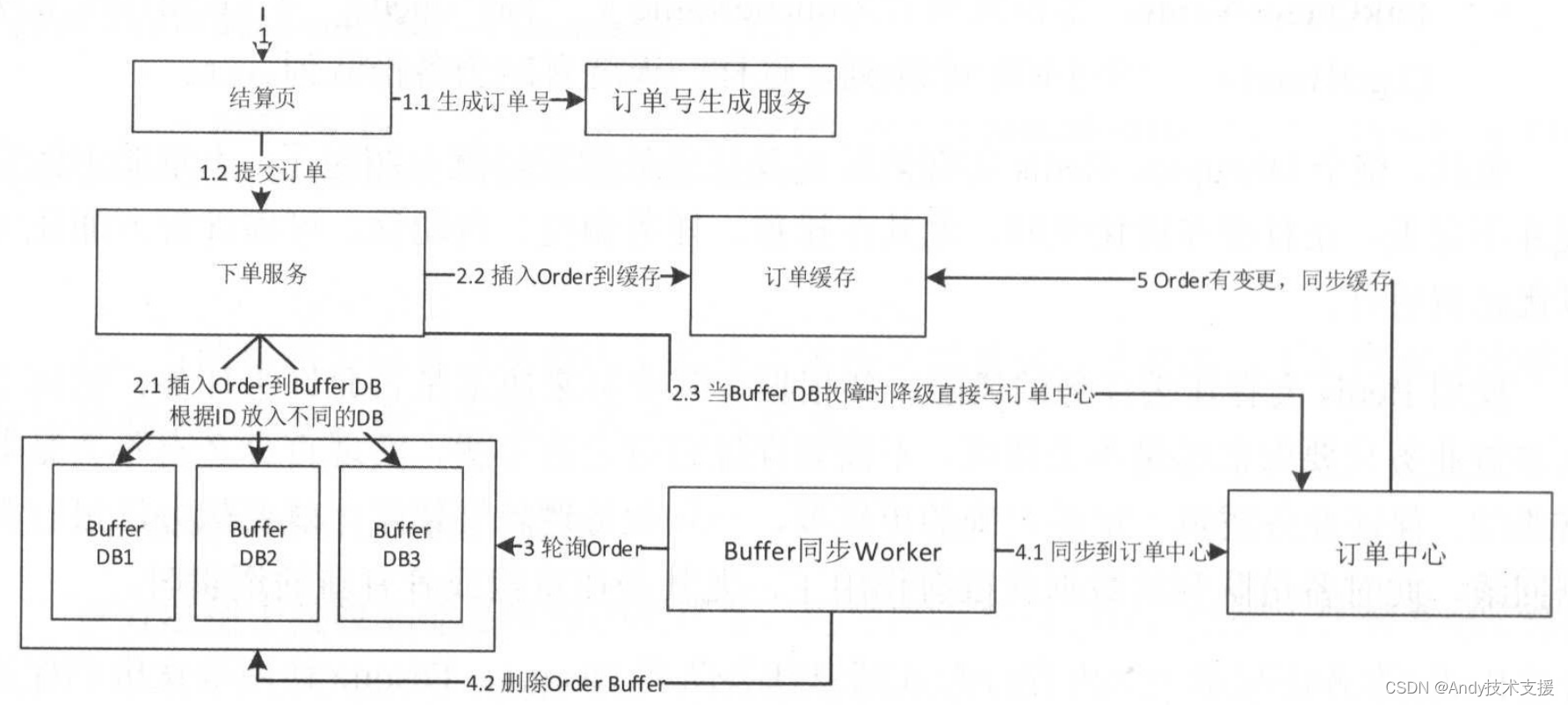
- 首先,用户在结算页提交订单后,系统调用订单号生成服务,然后结算服务会进行一些业务处理,最后调用下单服务提交订单。
- 下单服务将订单写入订单缓冲表,下单服务和订单缓存表可以水平扩展,从而支持更多的下单操作。写入缓冲表成功后,将订单写入缓存,从而前端用户可以查看到当前订单。如果下单服务有问题,则可以考虑直接降级将订单写入订单中心。
- 接着缓冲同步Worker轮询这些缓冲表。
- 同步Worker将订单同步到订单中心,如果订单中心数据有变更,则更新订单缓存。
基于Canal实现数据异构
在大型网站架构中,DB都会采用分库分表来解决容量和性能问题,但是分库分表之后带来了新的问题,比如不同维度的查询或者聚合查询,此时就会非常棘手。
一般我们会通过数据异构机制来解决此问题。
如下图所示,为了提升系统的接单能力,我们会对订单表进行分库分表,但是,随之而来的问题是:用户怎么查询自己的订单列表呢?一种办法是扫描所有的订单表,然后进行聚合,但是这种方式在大流量系统架构中肯定是不行的。
另一种办法是双写,但是双写的一致性又没法保证。还有一种办法就是订阅数据库变更日志,比如订阅MySQL的binlog日志模拟数据库的主从同步机制,然后解析变更日志将数据写到订单列表,从而实现数据异构,这种机制也能保证数据的一致性。

除了可以进行订单列表的异构,像商家维度的异构、ES搜索异构、订单缓存异构等都可以通过这种方式解决。
在介绍Canal之前,我们先看一下MySQL的主从复制架构。
MySQL主从复制
MySQL主从复制架构如下图所示。
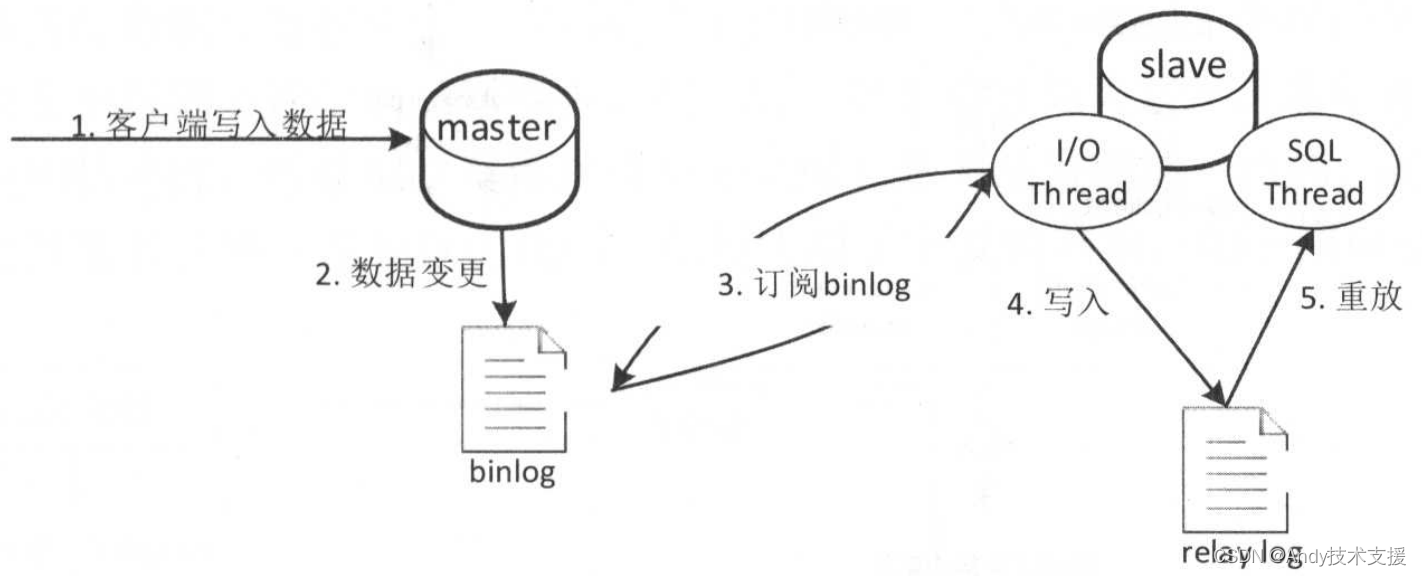
- 首先MySQL客户端将数据写入master数据库。
- master数据库会将变更的记录数据写入二进制日志中,即binlog。
- slave数据库会订阅master数据库的binlog日志,通过一个I/O线程从binlog的指定位置拉取日志进行主从同步,此时master数据库会有一个Binlog Dump线程来读取binlog日志与slave I/O线程进行数据同步。
- slave I/O线程读取到日志后会先写入relay log重放日志中。
- slave数据库会通过一个SQL线程读取relay log进行日志重放,这样就实现了主从数据库之间的同步。
可以把Canal看作slave数据库,其订阅主数据库的binlog日志,然后读取并解析日志,这样就实现了数据同步/异构。
Canal简介
Canal是阿里开源的一款基于MySQL数据库binlog的增量订阅和消费组件,通过它可以订阅数据库的binlog日志,然后进行一些数据消费,如数据镜像、数据异构、数据索引、缓存更新等。相对于消息队列,通过这种机制可以实现数据的有序性和一致性。
Canal架构如下图所示。

首先需要部署canal server,可以同时部署多台,但是只有一台是活跃的,其他的作为备机。
canal server会通过slave机制订阅数据库的binlog日志。canal server的高可用是通过来zk维护的。
然后canal client会订阅canal server,消费变更的表数据,然后写入到如镜像数据库、异构数据库、缓存数据库,具体如何应用就看自己的场景了,同时也只有一台canal client是活跃的,其他的作为备机,当活跃的canal client不可用后,备机会被激活。
canal client的高可用也是通过zk来维护的,比如zk维护了当前消费到的日志位置。
canal server目前读取的binlog事件只存储在内存中,且只有一个canal client能进行消费,其他的作为备机。
如果需要多消费客户端,则可以先写入ActiveMQ/kafka,然后进行消费。
如果有多个消费者,那么也建议使用此种模式,而不是启动多个canal server读取binlog日志,这样会使得数据库的压力较大。
ActiveMQ提供了虚拟主题的概念,支持同一份内容多消费者镜像消费的特性。
canal一个常见应用场景是同步缓存,当数据库变更后通过binlog进行缓存的增量更新。当缓存更新出现问题时,应能回退binlog到过去某个位置进行重新同步,并提供全量刷缓存的方法,如下图所示。

另一个常见应用场景是下发任务,当数据变更时需要通知其他依赖系统。
其原理是任务系统监听数据库数据变更,然后将变更的数据写入MQ/Kafka进行任务下发,比如商品数据变更后需要通知商品详情页、列表页、搜索页等相关系统。
这种方式可以保证数据下发的精确性,通过MQ发消息通知变更缓存是无法做到这一点的,而且业务系统中也不会散落着各种下发MQ的代码,从而实现了下发的归集,如下图所示。

类似于数据库触发器,只要想在数据库数据变更时进行一些处理,都可以使用Canal来完成。
在MySQL主从架构中,当有多个slave连接master数据库时,master数据库的压力比较大,为保障master数据库的性能,canal server可订阅slave的binlog日志,即是slave的slave。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!