YOLOv5改进 | 卷积篇 | SPD-Conv空间深度转换卷积(高效空间编码技术)
一、本文介绍
本文给大家带来的改进内容是SPD-Conv(空间深度转换卷积)技术。SPD-Conv是一种创新的空间编码技术,它通过更有效地处理图像数据来改善深度学习模型的表现。SPD-Conv的基本概念:它是一种将图像空间信息转换为深度信息的技术,从而使得卷积神经网络(CNN)能更加有效地学习图像特征。这种方法通过减少信息损失和提高特征提取的准确性,优化了模型对小物体和低分辨率图像的处理能力。我在YOLOv8中利用SPD-Conv被用于替换传统的步长卷积和池化层,在不牺牲精确度的情况下减少计算复杂度(精度甚至略有提升)。本文后面会有SPD-Conv的代码和使用方法,手把手教你添加到自己的网络结构中。(值得一提的是该卷积模块可以做到轻量化模型的作用GFLOPs由8.9降低到8.2,参数量也有一定降低)
推荐指数:?????
训练结果对比图->??
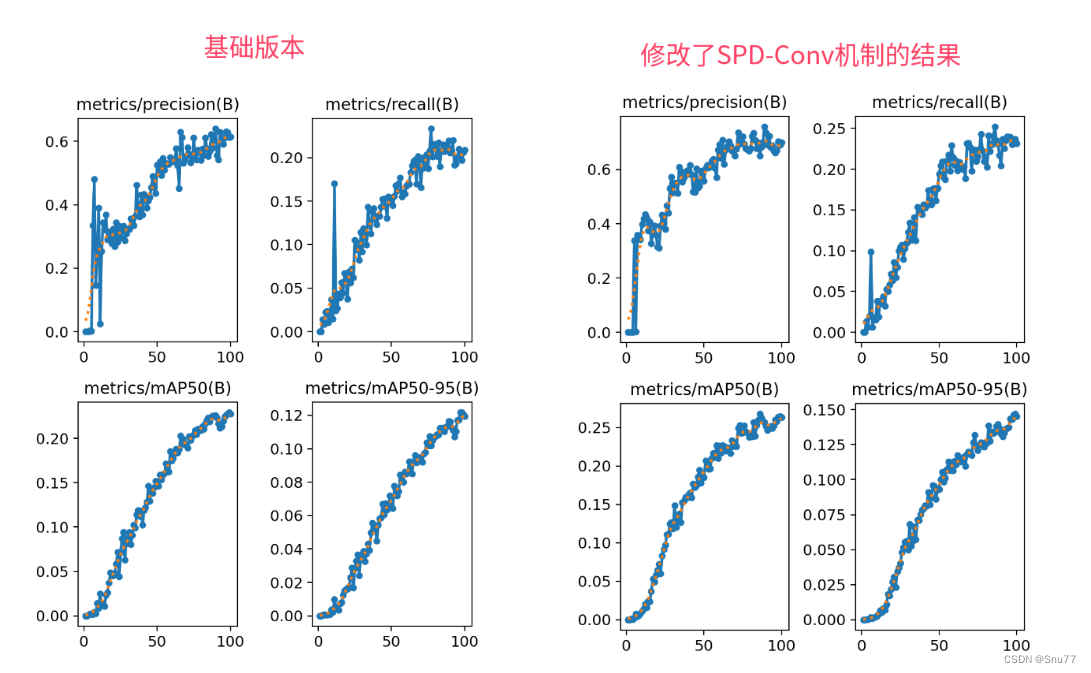 ?
?
二、SPD-Conv构建块原理
 ?
?
论文地址:论文官方地址
代码地址:
 ?
?
2.1?SPD-Conv的基本原理
SPD-Conv(空间到深度卷积)的基本原理是用于改进传统卷积神经网络(CNN)中对小物体和低分辨率图像处理的性能。它主要通过以下几个关键步骤实现:
1. 替换步长卷积和池化层:SPD-Conv设计用来替代传统CNN架构中的步长卷积层和池化层。步长卷积和池化层在处理低分辨率图像或小物体时会导致细粒度信息的丢失。
2. 空间到深度(SPD)层:SPD层的作用是降采样特征图的通道维度,同时保留信息。这种方式可以避免传统方法中的信息丢失。
3. 非步长卷积层:在SPD层之后,SPD-Conv使用一个非步长(即步长为1)的卷积层。这有助于在降低通道数量的同时利用可学习的参数对特征进行处理。
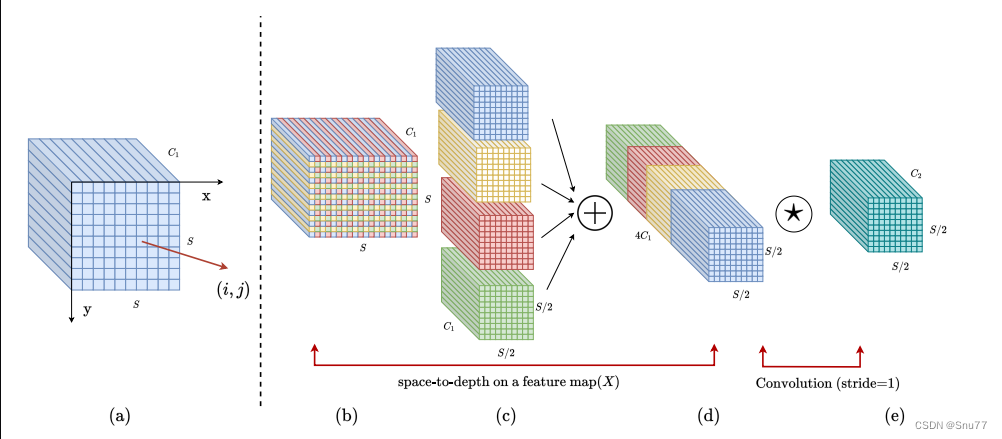 ?
?
以下是我对这个图的理解:
1. 特征图 (a):传统的特征图,具有通道数 ?,高度和宽度。
2. 空间到深度变换 (b):通过空间到深度操作,将像素的空间块重新排列到深度/通道维度,增加通道数到 4?,同时将空间维度缩小2倍。
3. 通道合并 (c):不同的通道组在通道维度上进行合并。
4. 加法操作 (d):合并的特征图可能会与其他处理过的特征图(图中未详细展示)进行加法操作。
5. 非步长卷积 (e):对结果特征图应用步长为1的卷积,减少通道维度至?,同时保持空间分辨率,其仍是原始大小的1/2。
2.1.1替换步长卷积和池化层
论文中提出的SPD-Conv构建块是为了替代传统CNN中的步长卷积和池化层。步长卷积和池化层在处理低分辨率图像和小物体时会导致信息的丢失。SPD-Conv使用空间到深度(SPD)层,该层将特征图的空间维度转换成深度维度,通过增加通道数来保留更多信息。随后是非步长卷积层,它保持了空间维度,减少了通道数。这种替代方法避免了信息的丢失,并允许网络捕获更精细的特征,从而提高了在复杂任务上的性能。
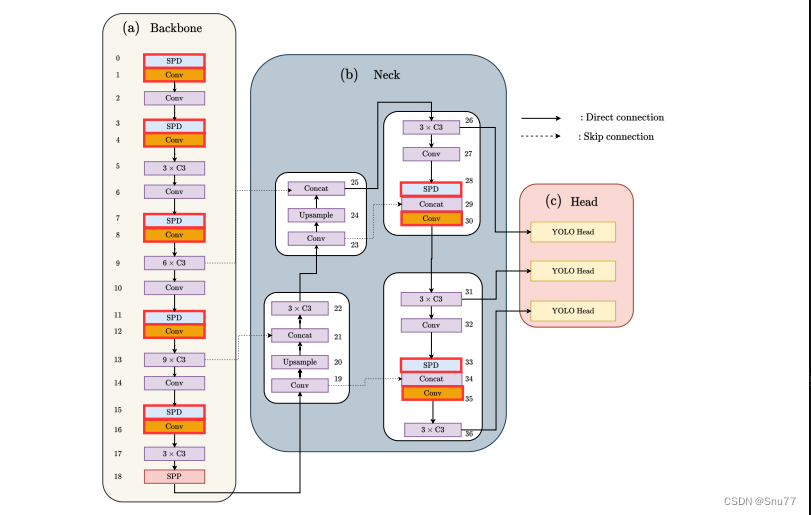 ?
?
上图是SPD-Conv论文中的一个图表,展示了如何在YOLOv5的结构中实施SPD-Conv(在YOLOv8中同样适用)。图中标红的部分代表了SPD-Conv替换传统卷积操作的地方。YOLOv5的架构被分为三个主要部分:
1. 主干网络(Backbone):这是特征提取的核心部分,每个SPD和Conv层的组合都替换了原始YOLOv5中的步长卷积层。
2. 颈部(Neck):这部分用于进一步处理特征图,以获得不同尺度的特征,从而提高检测不同大小物体的能力。它也包含SPD和Conv层的组合,以优化特征提取。
3. 头部(Head):这是决策部分,用于物体检测任务,包括定位和分类。头部保持了YOLO原始架构的设计。
直连线表示直接的前向连接,虚线代表跳跃连接,用于整合不同层次的特征。
2.1.2?空间到深度(SPD)层
空间到深度(SPD)层是SPD-Conv中的一个关键组件,其作用是将输入特征图的空间块(像素块)重新排列进入深度(通道)维度,以此来增加通道数,同时减少空间分辨率,但不丢失信息。通过这种方式,这一转换允许CNN捕捉和保留在处理小物体和低分辨率图像时经常丢失的精细信息。SPD层后面紧跟的是非步长卷积层,它进一步处理重新排列后的特征图,确保有效特征的提取和使用??。通过这种方法,SPD-Conv能够在特征提取阶段保留更丰富的信息,从而提高模型对于小物体和低分辨率图像的识别性能。
2.1.3?非步长卷积层
在SPD-Conv的背景下,非步长卷积层采用的是步长为1的卷积操作,意味着在卷积过程中,滤波器(或称为卷积核)会在输入特征图上逐像素移动,没有跳过任何像素。这样可以确保在特征图的每个位置都能应用卷积核,最大程度地保留信息,并生成丰富的特征表示。非步长卷积层是紧随空间到深度(SPD)层的一个重要组成部分。在SPD层将输入特征图的空间信息重新映射到深度(通道)维度后,非步长卷积层(即步长为1的卷积层)被用来处理这些重新排列的特征图。由于步长为1,这个卷积层不会导致任何进一步的空间分辨率降低,这允许网络在不损失细节的情况下减少特征图的通道数。这种方法有助于改善特征的表征,特别是在处理小物体或低分辨率图像时,这些场景在传统CNN结构中往往会丢失重要信息。
2.2 检测效果
 ?
?
上图比较了标准YOLOv5m模型和集成了SPD-Conv的改进版本YOLOv5-SPD-m的性能。紫色框表示标准YOLOv5m的预测,绿色框显示了YOLOv5-SPD-m的预测。蓝色框代表地面真相(ground truth)。红色箭头突出了两个模型预测之间的差异。
从图像中我们可以看出,YOLOv5-SPD-m(绿色框)的预测与地面真相更为接近,与YOLOv5m(紫色框)的预测相比,这表明将SPD-Conv整合进YOLOv5能增强模型准确检测物体的能力,这对于需要精确定位和识别的应用来说至关重要,例如自动驾驶或监控。
三、SPD-Conv完整代码
我们找到如下的目录'yolov5-master/models'在这个目录下创建一个文件目录(注意是目录,因为我这个专栏会出很多的更新,这里用一种一劳永逸的方法)文件目录起名modules,然后在下面新建一个文件,将我们的代码复制粘贴进去。
class SPDConv(nn.Module):
"""Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation)."""
default_act = nn.SiLU() # default activation
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):
"""Initialize Conv layer with given arguments including activation."""
super().__init__()
c1 = c1 * 4
self.conv = nn.Conv2d(c1 , c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
def forward(self, x):
x = torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1)
"""Apply convolution, batch normalization and activation to input tensor."""
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):
"""Perform transposed convolution of 2D data."""
x = torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1)
return self.act(self.conv(x))
四、手把手教你添加SPD-Conv
4.1 细节修改教程
4.1.1 修改一
我们找到如下的目录'yolov5-master/models'在这个目录下创建一个文件目录(注意是目录,因为我这个专栏会出很多的更新,这里用一种一劳永逸的方法)文件目录起名modules,然后在下面新建一个文件,将我们的代码复制粘贴进去。
?
?
?4.1.2 修改二
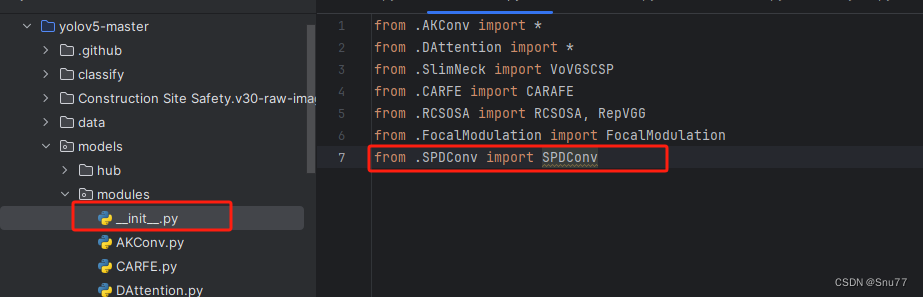
然后新建一个__init__.py文件,然后我们在里面添加一行代码。注意标记一个'.'其作用是标记当前目录。
 ?
?
?
4.1.3 修改三?
然后我们找到如下文件''models/yolo.py''在开头的地方导入我们的模块按照如下修改->
(如果你看了我多个改进机制此处只需要添加一个即可,无需重复添加。)
 ????
????
4.1.4 修改四
然后我们找到parse_model方法,按照如下修改->
 ?
?
到此就修改完成了,复制下面的ymal文件即可运行。
4.2 SPD-Conv的yaml文件(仔细看这个否则会报错)
4.2.1 SPD-Conv的yaml文件一
下面的配置文件为我修改的SPD-Conv的位置(这里需要注意的是你可以和初始的yaml对比一下修改了SPD-Conv的参数被修改了,你如果不修改该卷积那么则不需要修改另外两个参数),同时该卷积只能替换卷积核为3和步长为2的卷积。
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, SPDConv, [128]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, SPDConv, [256]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, SPDConv, [512]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, SPDConv, [1024]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, SPDConv, [256]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, SPDConv, [512]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
4.2.2?SPD-Conv的yaml文件二
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, SPDConv, [128]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, SPDConv, [256]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, SPDConv, [512]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, SPDConv, [1024]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
4.3 SPD-Conv运行成功截图
附上我的运行记录确保我的教程是可用的。?

五、本文总结?
到此本文的正式分享内容就结束了,在这里给大家推荐我的YOLOv5改进有效涨点专栏,本专栏目前为新开的平均质量分98分,后期我会根据各种最新的前沿顶会进行论文复现,也会对一些老的改进机制进行补充,目前本专栏免费阅读(暂时,大家尽早关注不迷路~),如果大家觉得本文帮助到你了,订阅本专栏,关注后续更多的更新~
 ?
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!