MindSpore Serving与TGI框架 の 对比
一、MindSpore Serving
MindSpore Serving是一款轻量级、高性能的服务工具,帮助用户在生产环境中高效部署在线推理服务。
使用MindSpore完成模型训练>导出MindSpore模型,即可使用MindSpore Serving创建该模型的推理服务。
MindSpore Serving包含以下功能:
-
支持自定义关于模型的预处理和后处理,简化模型的发布和部署。
-
支持batch功能,包含多个实例的请求会被拆分组合以满足模型batch size的需要。
-
支持分布式模型推理功能。
-
支持客户端gRPC接口,提供简单易用的客户端Python封装接口。
-
支持客户端RESTful接口。

部署Serving推理服务
- serving_server.py为启动服务脚本文件。
- xxx.mindir为上一步网络生成的模型文件。
- servable_config.py为模型配置文件:定义了模型的处理函数。
启动服务
执行serving_server.py,完成服务启动:
import os
import sys
from mindspore_serving import server
def start():
servable_dir = os.path.dirname(os.path.realpath(sys.argv[0]))
servable_config = server.ServableStartConfig(servable_directory=servable_dir, servable_name="add",
device_ids=(0, 1))
server.start_servables(servable_configs=servable_config)
server.start_grpc_server(address="127.0.0.1:5500")
server.start_restful_server(address="127.0.0.1:1500")
if __name__ == "__main__":
start()
启动脚本中start_servables将在设备0和1上共加载和运行两个推理副本,来自客户端的推理请求将被切割分流到两个推理副本。
当服务端打印如下日志时,表示Serving gRPC服务和RESTful服务启动成功。
Serving gRPC server start success, listening on 127.0.0.1:5500
Serving RESTful server start success, listening on 127.0.0.1:1500
执行推理
客户端提供两种方式访问推理服务,一种是通过gRPC方式,一种是通过RESTful方式。
使用serving_client.py,启动Python客户端。
————————————————————————————————————————
RESTful是一种基于HTTP协议的网络应用程序的设计风格和开发方式,通过URI实现对资源的管理及访问,具有扩展性强、结构清晰的特点。基于其轻量级以及通过HTTP直接传输数据的特性,RESTful已经成为最常见的Web服务访问方式。用户通过RESTful方式,能够简单直接的与服务进行交互。
- 通过mindspore_serving.server.start_restful_server接口启动RESTful服务:
请求方式
当前仅支持POST类型的RESTful请求,请求格式如下:
POST http://HOST:1234/model/LLaMA:generated_stream
如果使用curl工具,RESTful请求方式如下:
curl -X POST -d '{"instances":{"image":{"b64":"babe64-encoded-string"}}}' http://HOST:1234/model/LLaMA:generated_stream
二、TGI框架
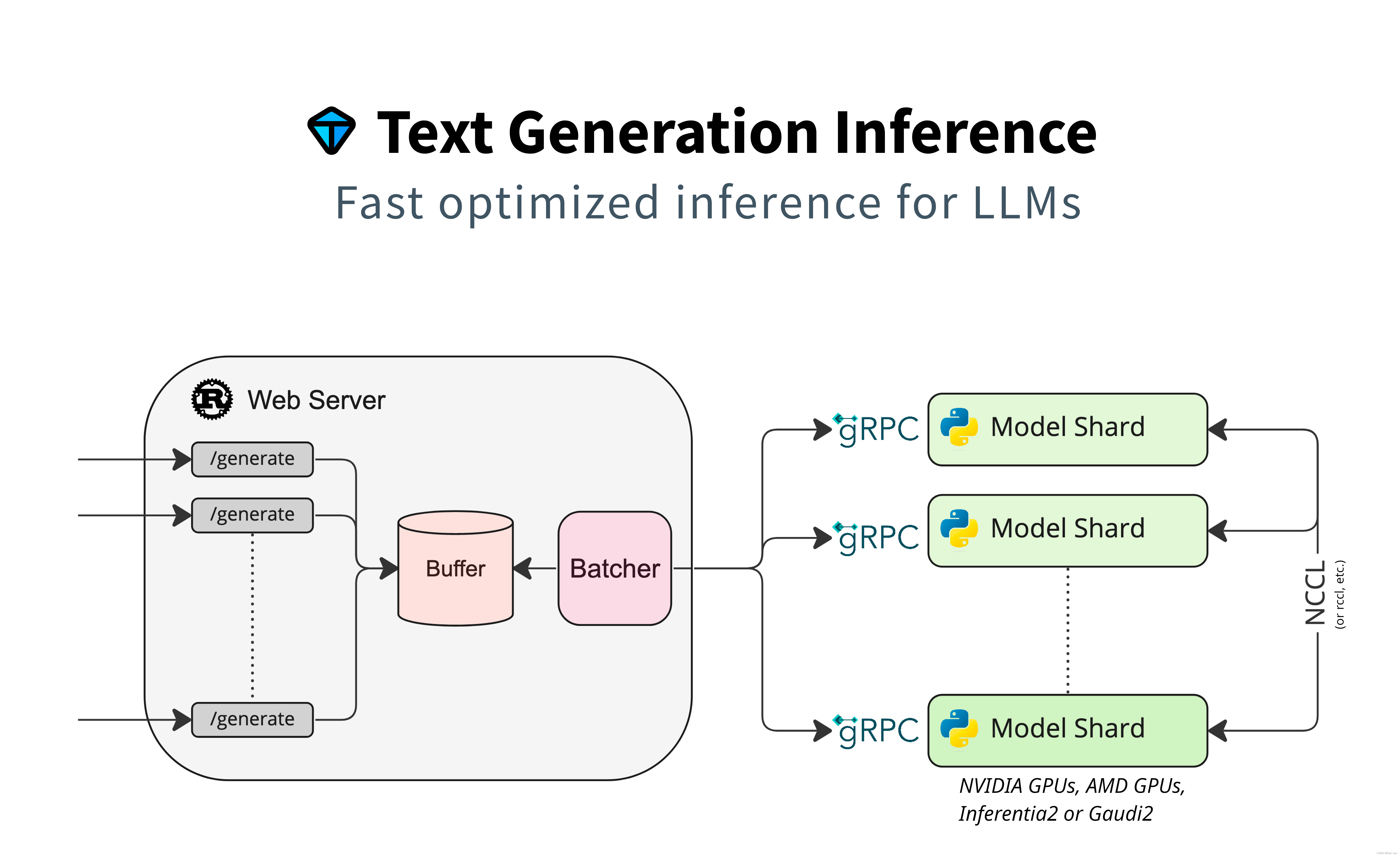
若干客户端同时请求Web Server的“/generate”服务后,服务端将这些请求在“Buffer”组件处整合为Batch,并通过gRPC协议转发请求给NPU推理引擎进行计算生成。
将请求发给多个Model Shard,多个Model Shard之间通过NCCL通信 是因为显存容量有限或出于计算效率考虑,需要多卡进行分布式推理。
推理框架一般会将第1次推理(首Token)和余下的推理(生成其余Token)分别设计为Prefill和Decode两个过程
-
Prefill 是将1个请求的Prompt一次性转换为KV Cache,并生成第1个Token的过程。
假设Prompt的长度为L,MultiHead Attention的头数为H(Head),每个头的维度为HS(Head Size,暂不考虑GQA/MQA)。
计算该过程时,输入Attention的Q、K、V维度均为[L,H, HS],输入FFN的hidden(隐藏层向量)维度为[L, H *HS]。
完成模型计算后,仅对最后一个Logit进行解码得到首Token;中间过程计算得到的K、V被保留在显存中(即KV Cache,用于避免后续Decode过程重复计算这些K、V导致算力浪费)。 -
Decode:从第2个Token开始,将上一次推理的输出(新生成的1个Token)作为输入进行一次新的推理。假设BatchSize=1,已生成的新子序列长度为N,在计算该过程时,输入Attention的Q维度为[1,H, HS], K、V维度则为[L+N+1,H, HS],输入FFN的hidden维度为[1, H*HS]。
完成模型计算后,对唯一的Logit进行解码得到新生成的Token;中间过程计算得到的K、V追加到KV Cache中(原因同上)。重复Decode流程持续生成Token直到模型输出(End of Sentence,表示输出结束的特殊Token)。
将推理分为Prefill和Decode,是考虑到生成第1个Token和其余Token时计算模式的差异较大,分开实现有利于针对性优化。
TGI引入Continuous Batching特性,其中请求的合并和剔除就是通过Router向Server发送Concatenate和Filter的Request实现。
Continuous Batching(或称Inflight Batch)核心思想是在两次Decode的间隙插入新请求的Prefill、各请求的合并和剔除等操作,从而以动态Batch推理的方法提高NPU利用率。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!