Pix2Pix如何工作?
一、说明
????????在本指南中,我们将重点介绍 Pix2Pix [1],它是用于配对图像翻译的著名且成功的深度学习模型之一。在地理空间科学中,这种方法可以帮助传统上不可能的广泛应用,在这些应用中,我们可能希望从一个图像域转到另一个域,即图像到地图,RGB到多光谱图像,SAR到图像,DSM到图像等。
二、图像到图像的转换
????????图像到图像转换被定义为在给定来自两组场景的训练数据量的情况下,将场景的一种可能的表示或风格转换为另一种的任务。目前 arcgis.learn 模块中实现了两种类型的图像到图像转换模型:Pix2Pix 和 CycleGAN。
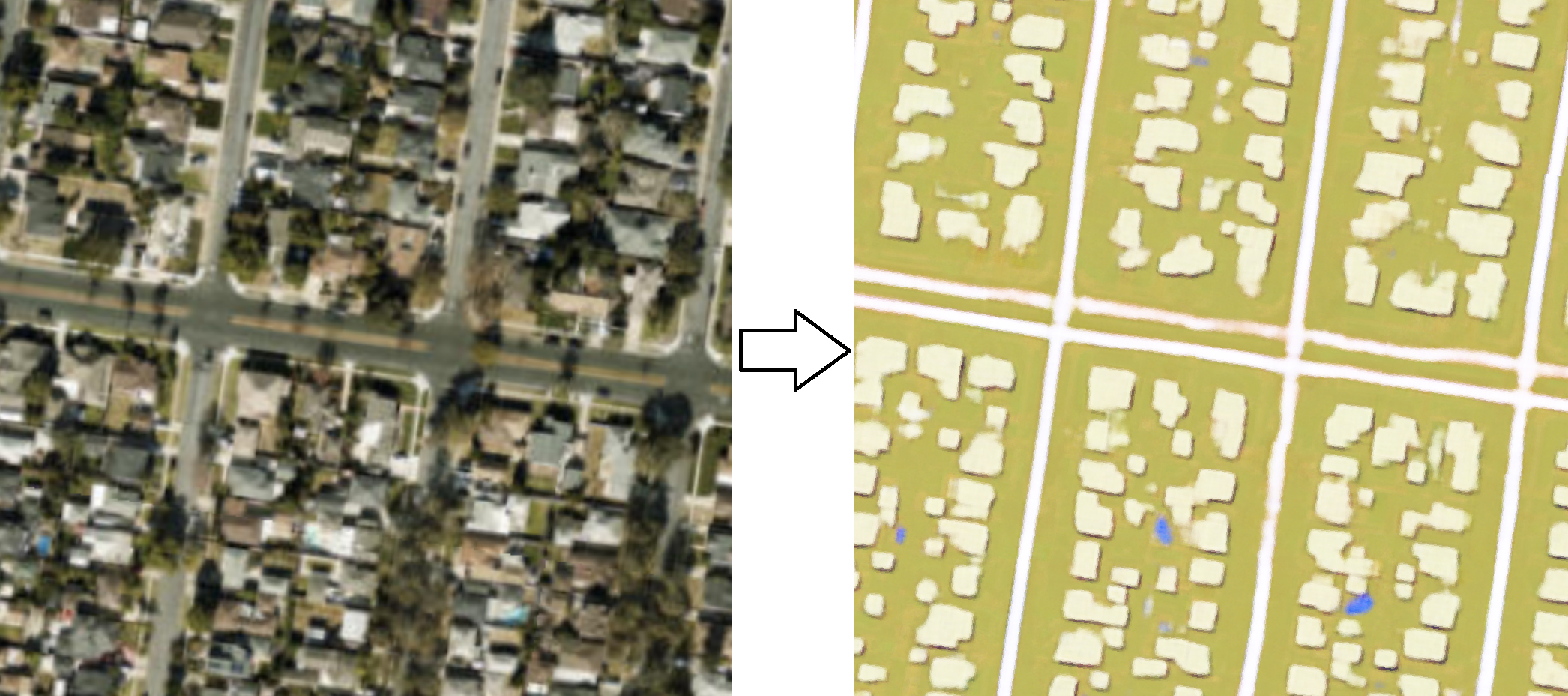
图 1.使用 Pix2Pix 进行地图翻译的卫星图像
????????
????????为了遵循下面的指南,我们假设您对卷积神经网络 (CNN) 概念有一些基本的了解。您可以通过阅读这篇简短的论文“深度学习卷积算术指南”和用于视觉识别的卷积神经网络 [2] 课程来更新您的 CNN 知识。此外,我们建议阅读这篇关于生成对抗网络:概述的论文,并在阅读本文之前先阅读 fast.ai?GAN?课程。Pix2Pix 是一种称为条件 GAN 的 GAN 架构。因此,了解 GAN 的基础知识对我们来说很重要。
三、生成对抗网络 (GAN) 的基础知识
????????GAN 是一种通过对抗过程估计生成模型的框架,其中两个模型同时训练,称为生成器 (G) 和判别器 (D) 模型。生成器模型学习生成可能的数据,而判别器模型学习区分 G 生成的假数据和真实数据 [3]。因此,用于训练 GAN 的目标函数 and 可以表示为一个双人最小-最大博弈,其中生成器 G 的目标是最小化目标,而判别器 D 试图最大化目标。
????????这种训练方法导致生成器 G 估计或生成样本数据,这些数据可以随着训练的进行而欺骗判别器 D,最终判别器 D 在区分真实和虚假数据方面变得很糟糕,其准确性降低。GAN的基本架构如图2所示[4]。

图2.基本 GAN 架构
?
四、Pix2Pix概要
????????Pix2Pix 基于连接 GAN 架构。条件 GAN 或 cGAN 是一种 GAN 架构。cGAN 在来自两个领域的配对图像或场景集上进行训练,用于翻译。由于 GAN 被训练为从整套训练数据集生成假样本,因此通常会导致结果不佳。因此,我们根据输入图像或一些辅助信息对生成器和鉴别器进行条件调整,从而从目标域有针对性地生成图像。这使得 cGAN 适用于图像到图像的转换任务,在该任务中,我们以输入图像为条件并生成相应的输出图像。
????????pix2pix 的架构由一个生成器 G 和一个鉴别器 D 组成。Generator G 是具有跳过连接的编码器-解码器网络或 U-Net,而 Discriminator 是一种补丁 GAN 架构,它以补丁的规模进行惩罚。
五、模型架构
5.1?U-Net发电机
????????U-net最初被发明并首先用于生物医学图像分割。它的架构可以被广泛地认为是一个编码器网络,然后是解码器网络。
- 编码器是架构图的前半部分(图 3)。它通常是像 VGG/ResNet 这样的分类网络,您可以在其中应用卷积块,然后应用 maxpool 下采样,将输入图像编码为多个不同级别的特征表示。
- 解码器是架构的后半部分。目标是将编码器学习的判别特征(较低分辨率)投影到像素空间(较高分辨率)上,以获得密集值。解码器由上采样和串联组成,然后是常规卷积操作。

图3.U-Net 中的跳过连接将其与标准的编码器-解码器架构区分开来
????????生成器损耗是生成图像和 Array of Images 之间的 S 形交叉熵损耗(gan 对抗损耗)和生成图像和目标图像之间的 L1 损耗,也称为 MAE(平均绝对误差)。因此,总生成的损失变为 gan 对抗性损失 + LAMBDA * l1 损失,其中 LAMBDA = 100 [1]。
????????在网络中,输入通过一系列层,这些层逐渐下采样(编码器),直到瓶颈层,此时过程被逆转(解码器)。这样的网络要求所有信息流都经过所有层,包括瓶颈。为了捕获输入和输出之间共享的每个低级信息,我们在每层 i 和层 n ? i 之间添加跳过连接,其中 n 是总层数。每个跳过连接只是将第 i 层的所有通道与第 n 层 ? i 的所有通道连接起来(图 3)。
5.2 Patch-GAN 鉴别器
????????patch-GAN 鉴别器是添加到 pix2pix 架构中的独特组件。它的工作原理是将图像中的 (n*n) 片段分类为真实和虚假,而不是将整个图像分类为真实和虚假。这迫使更多的约束,并鼓励清晰的高频细节。这比对整个图像进行分类更快,并且参数更少。判别器接受两个图像对作为输入,输入图像,目标图像和输入图像,生成图像。我们将这两个输入对连接起来。
????????鉴别器损失由两个损失组成,一个是真实图像和 1 数组之间的 S 形交叉熵损失,另一个是生成的图像和零数组之间的 S 形交叉熵损失。总鉴别器损耗是这两个损耗的总和。有关架构和超参数的详细说明,请参阅本文
????????图 4 中所示的 Pix2Pix 模型架构正在从简单的样式化映射转换为目标样式化映射域。[4]
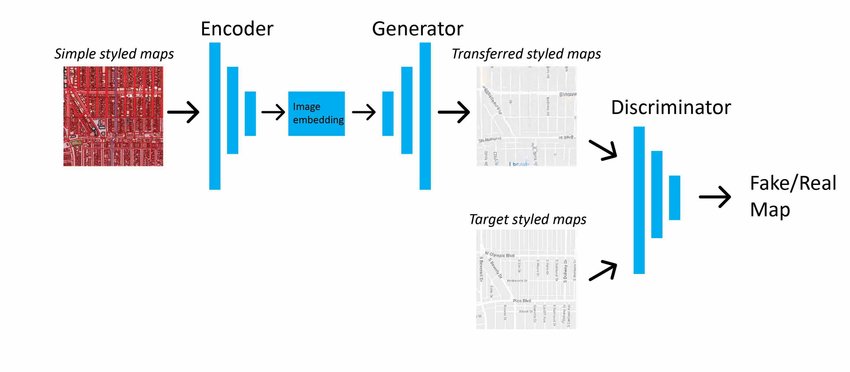
图4.Pix2Pix 模型架构
六、在arcgis.learn
????????首先,我们必须使用 ArcGIS Pro 中提供的深度学习导出训练数据工具以导出切片元数据格式导出图像芯片,方法是在输入栅格和附加输入栅格中提供两个影像域,然后将路径提供给 arcgis 中的prepare_data 函数.学习创建数据束。...? ? ? ??
? ?data = arcgis.learn.prepare_data(path=r"path/to/exported/data")
????????默认情况下,我们在初始化Pix2Pix对象时创建 U-Net 生成器和 patch-GAN 鉴别器。我们可以简单地这样做,如下所示:
model = arcgis.learn.Pix2Pix(data=data)
????????这里的数据是一个fastai数据包,从函数返回的对象,更多解释可以在fast.ai的文档中找到[6prepare_data]
然后我们可以继续arcgis.learn基本的工作流程。
有关 API 和模型应用程序的更多信息,请转到?API 参考和示例笔记本。
七、总结
在本指南中,我们了解了图像到图像转换模型的各种细节,以及如何在Pix2Pixarcgis.learn
八、引用
- [1] Isola, Phillip, Jun-Yan Zhu, Tinghui 周, and Alexei A. Efros.“使用条件对抗网络进行图像到图像转换。”IEEE计算机视觉和模式识别会议论文集,第1125-1134页。2017.
- [2] CS231n:用于视觉识别的卷积神经网络。Stanford University CS231n: Deep Learning for Computer Vision
- [3] Goodfellow、Ian、Jean Pouget-Abadie、Mehdi Mirza、Bing Xu、David Warde-Farley、Sherjil Ozair、Aaron Courville 和 Yoshua Bengio。“生成对抗网络。”在《神经信息处理系统进展》中,第 2672-2680 页。2014.
- [4]?ACGAN Architectural Design - coding.2020年11月27日访问。
- [5] Kang、Yuhao、Song Gao 和 Robert E. Roth。“使用生成对抗网络传输多比例地图样式。”国际制图学杂志 5, no. 2-3 (2019): 115-141.
- [6] Fast.ai 文档。| fastai。2020年11月27日访问。
- [7] Fast.ai 的 GAN 课程。Deep Learning For Coders—36 hours of lessons for free。2020年11月27日访问。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!