Object Detectors Emerge in Deep Scene CNNs(2015)

文章目录
hh
Abstract
随着卷积神经网络(CNN)等新的视觉处理计算架构的成功,以及对包含数百万个标记示例的图像数据库的访问(例如:(ImageNet, Places),计算机视觉的最新技术正在迅速发展。持续进步的一个重要因素是理解由这些深层架构的内层学习的表示。在这里,我们展示了训练cnn来执行场景分类的目标检测器。由于场景是由物体组成的,用于场景分类的CNN会自动发现有意义的物体检测器,代表学习到的场景类别。随着学习识别场景而出现的物体检测器,我们的工作表明,同一个网络可以在单个前向传递中执行场景识别和物体定位,而无需明确地教授物体的概念。
Introduction
事实上,物体的强内部配置使得有用部件的定义缺乏约束:算法可以找到不同的和任意的部件配置,所有这些都具有相似的识别性能。在场景的情况下,表现更加清晰。场景类别由它们所包含的对象定义,在某种程度上,由这些对象的空间配置定义。例如,卧室的重要组成部分是床,一张边桌,一盏灯,一个橱柜,以及墙壁,地板和天花板。因此,对象代表了场景的分布式代码(即,对象类在不同的场景类别之间共享)。重要的是,在场景中,物体的空间结构,虽然紧凑,但自由度大得多。我们认为,正是这种松散的空间依赖性使得场景表示与大多数对象类不同(大多数对象类在部件之间没有松散的交互)。(说白了就是提取特征)
这篇论文的主要贡献是表明,在训练有素的CNN中,目标检测出现在识别场景中,甚至比使用ImageNet训练时还要多。这是令人惊讶的,因为我们的结果表明,即使与ImageNet不同,没有为对象提供监督,也可以找到可靠的对象检测器。虽然深度神经网络的对象发现之前已经在无监督设置中展示过(Le, 2013),但在这里我们发现,在调整为场景分类而不是对象分类的监督设置中,可以自然地发现更多的对象。
重要的是,CNN内部对象检测器的出现表明,单个网络可以支持多个抽象层次(例如,边缘、纹理、对象和场景)的识别,而不需要多个输出或网络集合。这里我们展示了同一个网络可以在单个前向传递中同时进行对象定位和场景识别。
ImageNet-CNN and Places-CNN
与来自ImageNet-CNN的特征相比,来自Places-CNN的深度特征在与场景相关的识别任务上表现得更好。例如,与Places-CNN在场景分类上达到50.0%相比,ImageNet-CNN结合线性支持向量机在相同的测试集2上仅达到40.8%,这说明了以场景为中心的数据的重要性。
Uncovering the CNN Representation
我们的目标是理解网络正在学习的表示的本质
简化输入图像
简化图像是一种众所周知的测试人类识别能力的策略。例如,可以从图像中删除信息,以测试它是否对特定对象或场景进行诊断
受这些方法的启发,我们的想法如下:给定一个被网络正确分类的图像,我们希望简化该图像,使其保留尽可能少的视觉信息,同时在同一类别中仍然具有较高的分类分数。这个简化的图像(称为最小图像表示)将允许我们突出显示导致高分类分数的元素。
在第一种方法中,给定图像,我们创建边缘和区域的分割,并迭代地从图像中删除片段。在每次迭代中,我们移除正确分类分数下降最小的部分,直到图像被错误分类。最后,我们得到原始图像的表示,它包含了网络正确识别场景类别所需的最少量的信息。在图2中,我们展示了这些最小图像表示的一些例子。注意,物体似乎为网络识别场景提供了重要的信息。例如,在卧室的情况下,这些最小的图像表示通常包含床的区域,或在艺术画廊类别中,墙壁上绘画的区域。
可视化单元的感受野和激活模式
虽然理论上的RF大小可以在给定网络架构的情况下计算(Long et al., 2014),但我们对RF的实际或经验大小感兴趣。我们期望经验RFs比理论RFs更好地定位,更能代表它们捕获的信息,使我们能够更好地理解CNN的每个单元学习了什么
因此,我们提出了一种数据驱动的方法来估计每层中每个单元的学习RF。它比反卷积网络可视化方法更简单(Zeiler & Fergus, 2014),并且可以很容易地扩展到可视化任何学习的CNNs。
如图3所示,估计给定单元的RF的过程如下:作为输入,我们使用一个包含200k张图像的图像集,其中场景和对象的分布大致相等(类似于第2节)。然后,我们为给定单元选择具有最高激活的前K张图像。对于K张图像中的每一张,我们现在想要准确地确定图像的哪些区域导致高单位激活。为了做到这一点,我们在图像的不同位置使用小的随机遮挡器(大小为11×11的图像补丁)多次复制每个图像。具体来说,我们在一个步幅为3的密集网格中生成闭塞点。这导致每个原始图像大约有5000个遮挡图像。我们现在将所有被遮挡的图像输入到同一个网络中,并记录与使用原始图像相比激活的变化。如果有很大的差异,我们知道给定的补丁是重要的,反之亦然。这允许我们为每个图像构建差异图。
每个滑动窗口刺激在不同的空间位置包含一个小的随机斑块(如红色箭头所示)。通过比较滑动窗口刺激的激活响应与原始图像的激活响应,我们得到了每个图像的差异图(中上)。通过汇总排名靠前的图像的校准差异图(中下),我们获得该单元的实际RF(右)。
最后,为了整合来自K张图像的信息,我们将差异图集中在导致给定图像最大激活的单元的空间位置周围。然后我们对重新中心的差异图进行平均,以生成最终的RF。
在图4中,我们可视化了来自Places-CNN和ImageNet- CNN的4个不同层的单元的RF,以及RF内得分最高的激活区域。我们观察到,随着层数的加深,RF大小逐渐增加,激活区域在语义上变得更有意义。此外,如图5所示,我们使用RFs使用不同单元的特征映射对图像进行分割。
最后,在表2中,我们比较了不同层的RFs的理论和经验大小。正如预期的那样,RF的实际尺寸比理论尺寸小得多,特别是在后面的层中。总的来说,这种分析使我们能够通过精确地聚焦于每张图像的重要区域来更好地理解每个单元。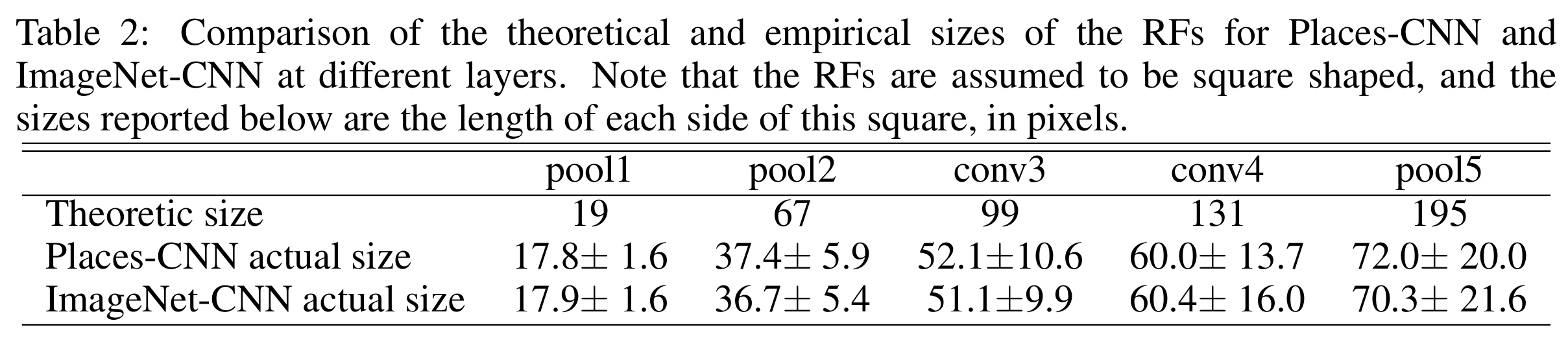
Conclusion
我们发现,目标检测器的出现是学习对场景类别进行分类的结果,这表明单个网络可以支持多个抽象层次(例如,边缘、纹理、对象和场景)的识别,而不需要多个输出或网络。虽然训练网络完成几个任务并使用最后一层作为输出是很常见的,但这里我们展示了可以在每一层提取可靠的输出。由于对象是组成场景的部分,因此在网络的内层中学习对不同场景之间有区别的对象进行调整的检测器。请注意,只有针对特定场景识别任务的信息对象才会出现。未来的工作应该探索哪些其他任务将允许在没有对象标签的显式监督的情况下学习其他对象类。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!