Redis-数据结构
参考资料 极客时间Redis(亚风)
Redis数据结构
SDS
sds(Simple Dynamic String) 字符串接结构体:
struct --attribute_- ((-_packed__)) sdshdr8{
uint8_t len;/* buf已保祥的字符串字节数,不包含结束标示*/
uint8_t alloc;/* buf申请的总的字节数,不包含结束标示*/
unsigned char flags;/*不同SDS的头类型,?来控制SDS的头??*/
char buf [];
}
Redis SDS 扩容机制
假如我们要给SDS追加?段字符串,Amy,这??先会申请新内存空间:
? 如果新字符串?于1M,则新空间为扩展后字符串?度的两倍+1;
? 如果新字符串?于1M,则新空间为扩展后字符串?度+1M+1。称为内存预分
配。
特别注意: :所以我们在生产中如果用Redis直接存储字符串最好是不要超过1M,不然可能回导致空间浪费。
IntSet
IntSet是Redis中set集合的?种实现?式,基于整数数组来实现,并且具备?度可变、有序等特征。
IntSet结构体
typedef struct intset {
uint32_t encoding; /*编码?式,?持存放16位、32位、64位整数*/
uint32_t Length;/* 元素个数 */
int8_t contents [];/*整数数组,保存集合数据*/
}
为了?便查找,Redis将intset中所有整数按升序依次保存在contents数组中。比如我们存储了1,2,3,4这个时候encoding 为16足以存储,如果我们插入50000这个时候有符号16位不足以存下,这个时候就会倒序扩容然后存储也就是从最后一个数据开始向后复制,最后的结果是每个数据都扩容到了32位。如果小于0插入最前面,如果大于0插入到最后面,如果是中间的数呢是通过二分法进行插入。
DICT
我们知道Redis是?个键值数据库,我们可以根据键实现快速的增删改查。?
键与值的映射关系是通过Dict来实现的。
Dict由三部分组成,分别是:DictHashTable(HashMap 类比java)、DictEntry(Map.entry)、Dict
typedef struct dictht {
// entry数组 数组中保存的是指向entry的指针
dictEntry **table;
//哈希表??
unsigned Long size;
//哈希表??的掩码,总等于size - 1 h % size == h & size - 1 的前提是size是2的倍数 引出面试题hashmap 为什么扩容是2倍扩容
unsigned Long sizemask;
// entry个数
unsigned Long used;
}
typedef struct dictEntry {
void *key;//键
union {
// 值可能是4中类型之一
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;//值
//下?个Entry的指针
struct dictEntry *next;
}
// 此数据结构用于扩容
typedef struct dict {
dictType *type;//dict类型,内置不同的hash函数
void *privdata; // 私有数据,在做特殊hash运算时?
dictht ht[2];//?个Dict包含两个哈希表,其中?个是当前数据,另?个?般是空,rehash时使?
Long rehashidx;
//rehash的进度,-1表示未进?
int16_t pauserehash;// rehash是否暂停,1则暂停,0则继续
}
当我们向Dict添加键值对时,Redis?先根据key计算出hash值 (h),然后利? h& sizemask来计算元素应该存储到数组中的哪个索引位置。
Dict中的HashTable就是数组结合单向链表的实现,当集合中元素较多时,必然导致哈希冲突增多,链表过?,则效率会??降低。Dict在每次新增键值对时都会检查负载因?(LoadFactor =used/size),used表示entry的数量也就是数据节点的数量,size是hash表的大小,满?以下两种情况时会触发哈希表扩容:
? 哈希表的 LoadFactor >= 1,并且服务器没有执? SAVE 或REWRITEAOF 等进程
? 哈希表的 LoadFactor>5;
扩容的逻辑
static int _dictExpandI fNeeded (dict *d){
//如果正在rehash,则返回ok
if (dictisRehashing(d)) return DIcT.oK;
//如果哈希表为空,则初始化哈希表为4
if (d->ht[0].size == 0) return dictExpand (d, 4);
// 当负载因?(used/size)达到1以上,并且当前没有进?rewriteaof等?进程操作
//或者负载因?超过5,则进? dictExpand,也就是扩容
if (d->ht[0].used >= d->ht[0].size &&dict_can_resize Il d->ht [0] .used/d->ht
[0] .size > 5){
//扩容??为used +1,底层会对扩容??做判断,实际上找的是第?个?于等于
used+1 的 2n
return dictExpand(d, d->ht[0].used + 1);
}
return DICT_OK;
}
Dict除了扩容以外,每次删除元素时,也会对负载因?做检查,当LoadFactor<0.1 时,会做哈希表收缩:
// 判断是否需要缩容 染出操作成功的时候检查
int htNeedsResize(dict *dict) {
//哈希表??
size = dictSlots(dict);
// entry数量
used = dictSize(dict);
// 负载因?低于0.1
return (size > 4 &&(used*100/size < 10));
}
// 收缩逻辑
int dictResize(dict *d){
unsigned Long minimal;
//如果正在做save或rewriteaof或rehash,则返回错误
if (!dict_can_resize || dictIsRehashing (d))
return DICT_ERR;
// 获取used,也就是entry个数
minimal = d->ht[0].used;
//如果used?于4,则重置为4
if (minimal < 4) minimal = 4;
// 重置??为minimal,其实是第?个?于等于minimal的2n
return dictExpand(d, minimal);
}
不管是扩容还是收缩,必定会创建新的哈希表,导致哈希表的size和sizemask变化,?key的查询与sizemask有关。因此必须对哈希表中的每?个key重新计算索引,插?新的哈希表,这个过程称为rehash。过程是这样的:
1 计算新hash表的realsize,即第?个?于等于dict.ht[0].used的2的n次方。
2 按照新的realsize申请内存空间,创建dictht,并赋值给dict.ht[1]。
3 设置rehashidx= 0,标示开始rehash。
4 将dict.ht[0]中的每?个dictEntry都rehash到dict.ht[1]每次执?新增、查询、修改、删除操作时,都检查?下dict.rehashidx是否?于-1,如果是则将ht[0].table[rehashidx]的entry链表rehash到dict.ht[1](这里的逻辑是每次将这个槽里面的数据全部搬过去,不是将整个数据(所有槽)搬过去),井且将rehashidx++。直?dict.ht[0]的所有数据都rehash到dict.ht[1]。搬运过程中,这条链表上的数据,有可能会搬到别的位置。满足一个原则:元素要不原位置不动,要不搬运到oldsize + index的位置去。
5 将dict.ht[1]赋值给dict.ht[0],给dict.ht[1]初始化为空哈希表。
6 将rehashidx赋值为-1,代表rehash结束。
7 在rehash过程中,新增操作,则直接写?ht[1],查询、修改和删除则会在dict.ht[0]和dict.ht[1]依次查找并执?。这样可以确保h[0]的数据只减不增,随着rehash最终为空。
ZipList
生成环境中最多存储几千的数据,数据多性能会下降
ZipList 是?种特殊的双端链表,由?系列特殊编码的连续内存块组成。可以在任意?端进?压?/弹出操作,并且该操作的时间复杂度为 0(1)。

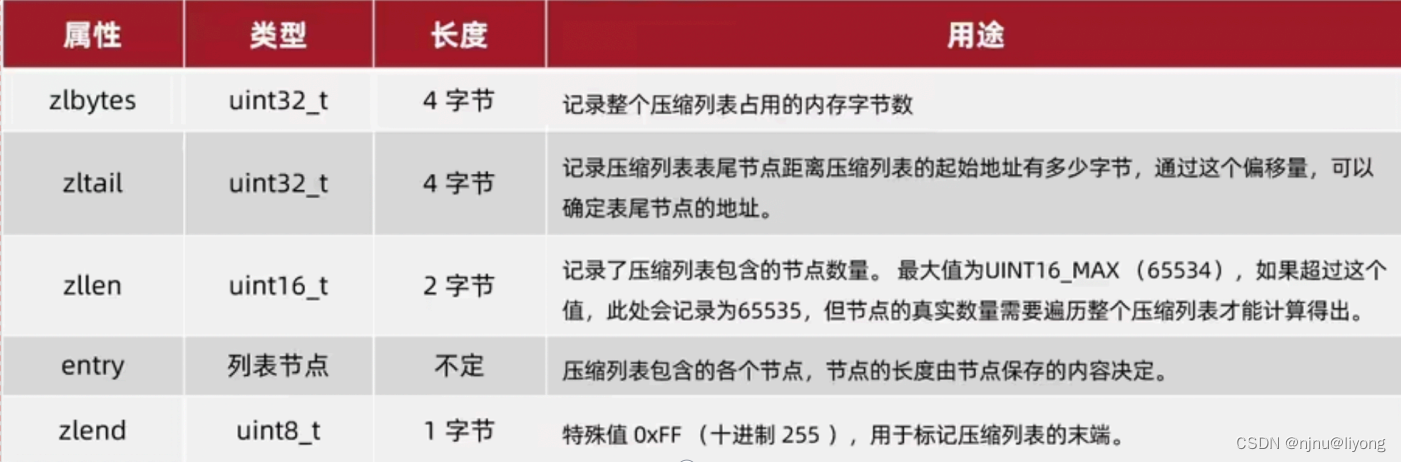
ZipList 中的Entry并不像普通链表那样记录前后节点的指针,因为记录两个指针要占?16个字节,浪费内存。?是采?了下?的结构:

previous_entry_length:前?节点的字节??,占1个或5个字节。如果前?节点的?度?于254字节,则采?1个字节来保存这个?度值。如果前?节点的?度?于254字节,则采?5个字节来保存这个?度值,第?个字节为0xfe,后4个字节才是真实?度数据。
encoding:编码属性,记录content的数据类型(字符串还是整数)以及content的字节数,占?1个、2个或5个字节。如果encoding是以“00”、“01〞或者“10”开头,则证明content是字符串,如果encoding是以“11〞开始,则证明content是整数,encoding占?1个字节。
Content:负责保存节点的数据,可以是字符串或整数
ZipList这种特殊情况下产?的连续多次空间扩展操作称之为连锁更新(Cascade Update)。新增、删除都可能导致连锁更新的发?。这种情况的发生就是因为254字节这个临界点,当前节点以后的数据都要被更新,因为大于254长度会用5个字节来存,所以不推荐存大量的数据存储
QuickList
问题1:ZipList虽然节省内存,但申请内存必须是连续空间,如果内存占?较多,申请内存效率很低。怎么办?
答:限制ZipList的?度和entry??。
问题2:但是我们要存储?量数据,超出了ZipList最佳的上限该怎么办?
答:可以创建多个ZipList来分?存储数据。
问题3:数据拆分后?较分散,不?便管理和查找,这多个ZipList如何建?联系?
答:使?QuickList,它是?个双端链表,只不过链表中的每个节点都是?个ZipList。
QuickList结构
typedef struct quicklist{
quicklistNode *head;
quicklistNode *tail;
// 所有ziplist的entry的数量
unsigned Long count;
// ziplists总数量
unsigned Long Len;
// ziplist的entry上限,默认值 -2
int fill: -2;
// ?尾不压缩的节点数量
unsigned int compress: 0
}
typedef struct quicklistNode
{
struct quicklistNode *prev;
struct quicklistNode *next;
//当前节点的ZipList指针
unsigned char *zl;
// 当前节点的ZipList的字节??
unsigned int sz;
//当前节点的ZipList的entry个数
unsigned int count: 16;
//编码?式:1,ZipList;2,压缩模式
unsigned int encoding: 2;
// 是否被解压缩。1:则说明被解压了,将来要重新压缩
unsigned int recompress : 1
}
为了避免QuickList中的每个ZipList中entry过多,Redis提供了?个配置项:listmax-ziplist-size来限制。
- 如果值为正,则代表ZipList的允许的entry个数的最?值
- 如果值为负,则代表ZipList的最?内存??,分5种情况:
① -1:每个ZipList的内存占?不能超过4kb
② -2: 每个ZipList的内存占?不能超过8kb
③ -3:每个ZipList的内存占?不能超过16kb
④ -4:每个ZipList的内存占?不能超过32kb
⑤ -5:每个ZipList的内存占?不能超过64kb
除了控制zipList的??,QuickList还可以对节点的ZipList做压缩。通过配置项list-compress-depth来控制。因为链表?般都是从?尾访问较多,所以?尾是不压缩的。这个参数是控制?尾不压缩的节点个数:
0:特殊值,代表不压缩
1:标示QuickList的?尾各有1个节点不压缩,中间节点压缩
2:标示QuickList的?尾各有2个节点不压缩,中间节点压缩
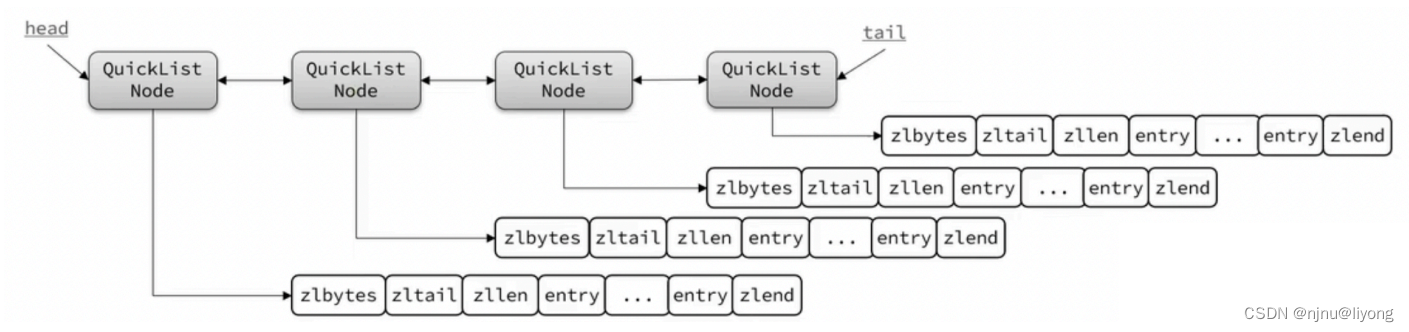
中间…表示被压缩的节点。
SkipList
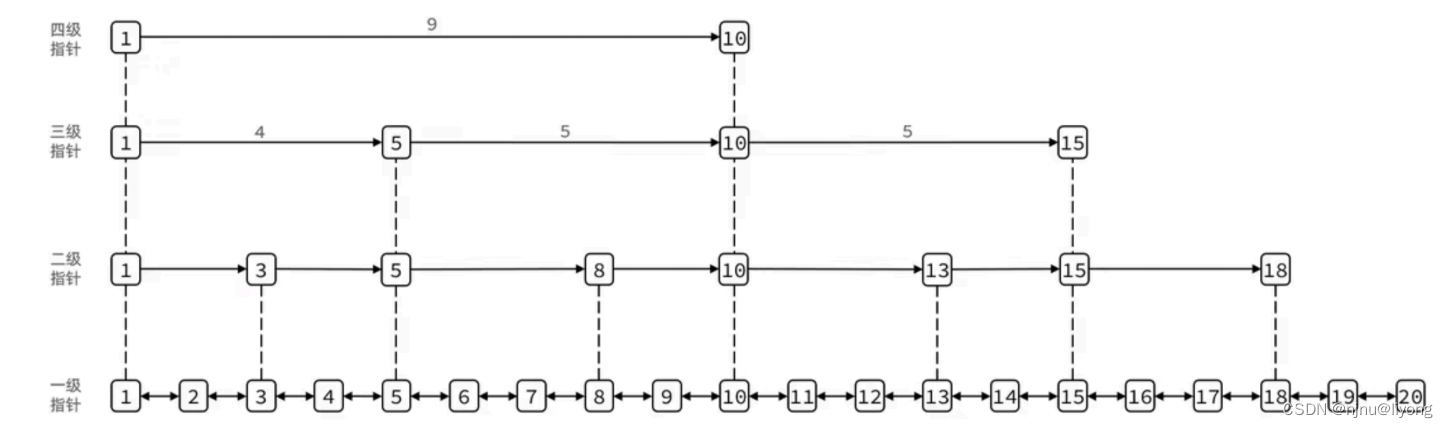
SkipList(跳表)?先是链表,但与传统链表相?有?点差异:
? 元素按照升序排列存储
? 节点可能包含多个指针,指针跨度不同
typedef struct zskiplist {
//头尾节点指针
struct zskiplistNode *header, *tail;
//节点数量
unsigned Long Length;
// 最?的索引层级,默认是1
int Level;
} zskiplist;
typedef struct zskiplistNode {
sds ele; //节点存储的值
double score;// 节点分数,排序、查找?
struct zskiplistNode *backward;// 前?个节点指针
struct zskiplistLevel {
struct zskiplistNode * forward;//下?个节点指针
unsigned Long span;//索引跨度
} level[];//多级索引数组
} zskiplistNode;
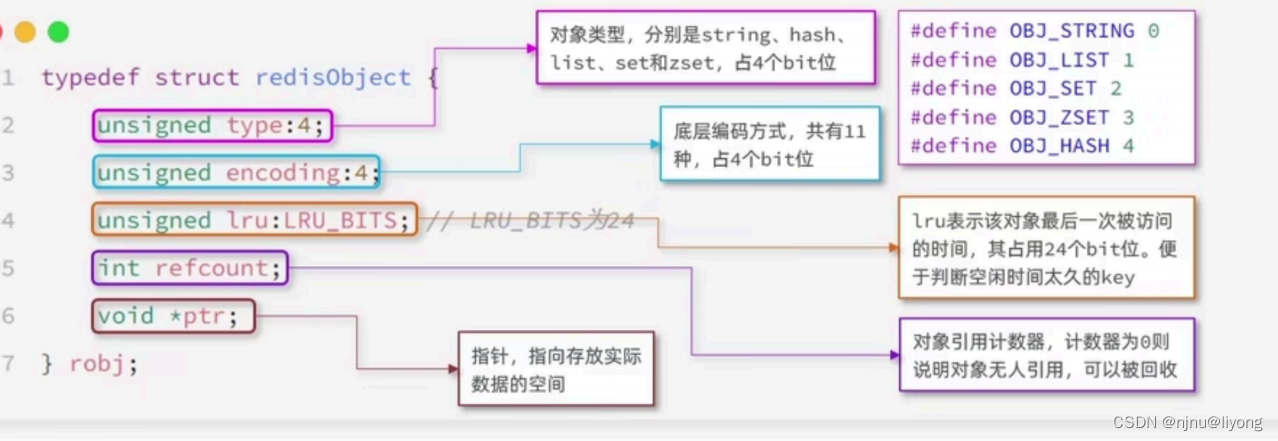
Redis对象
Redis 对底层的数据结构进行了进一步封装,但是其底层仍然是上面的几种数据结构实现:
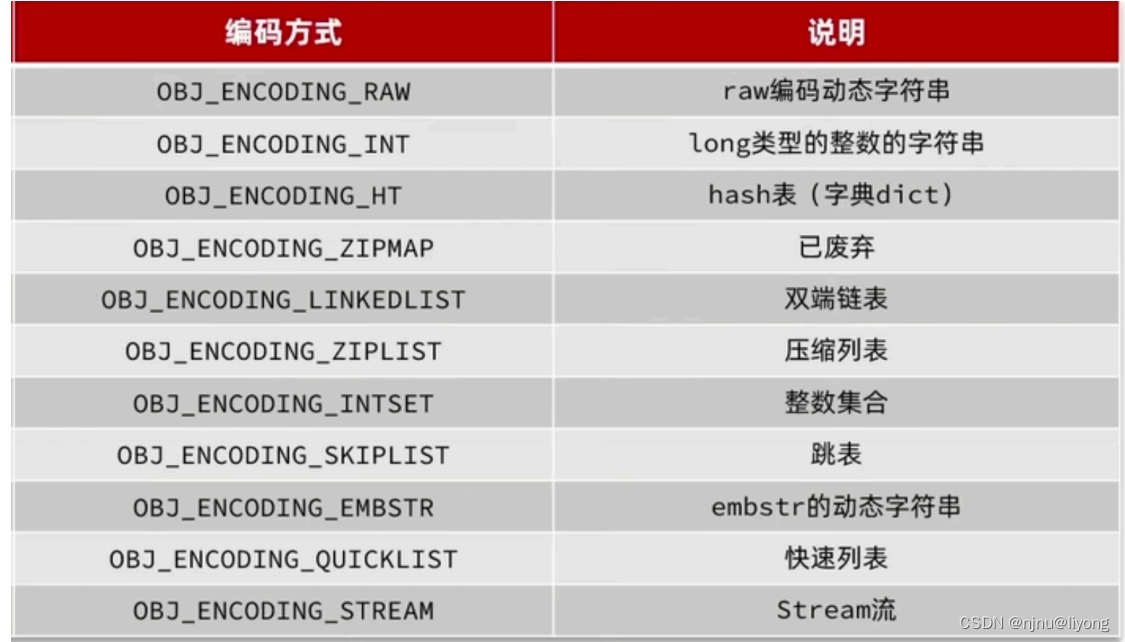
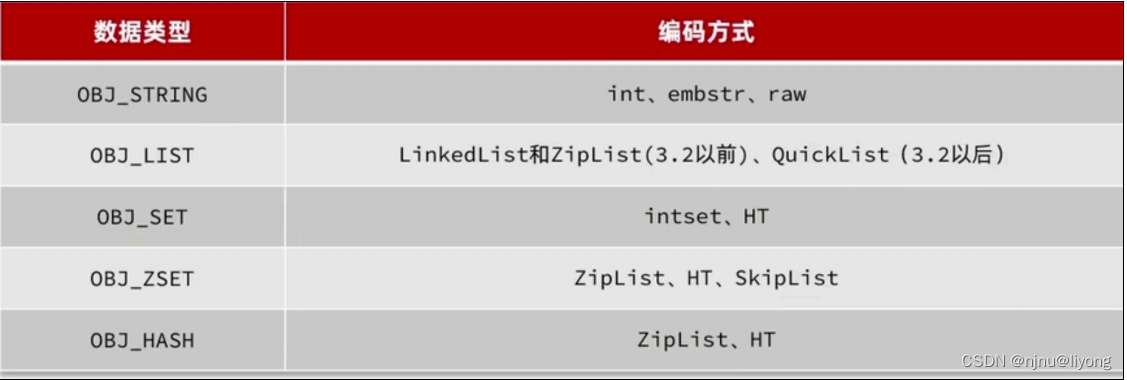
参考资料 极客时间Redis(亚风)
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!