异策略深度强化学习中的经验回放研究综述
2023-12-25 10:49:26
源自:自动化学报
作者:胡子剑, 高晓光, 万开方, 张乐天, 汪强龙
“人工智能技术与咨询”? 发布
摘 要
作为一种不需要事先获得训练数据的机器学习方法, 强化学习(Reinforcement learning, RL)在智能体与环境的不断交互过程中寻找最优策略, 是解决序贯决策问题的一种重要方法. 通过与深度学习(Deep learning, DL)结合, 深度强化学习(Deep reinforcement learning, DRL)同时具备了强大的感知和决策能力, 被广泛应用于多个领域来解决复杂的决策问题. 异策略强化学习通过将交互经验进行存储和回放, 将探索和利用分离开来, 更易寻找到全局最优解. 如何对经验进行合理高效的利用是提升异策略强化学习方法效率的关键. 首先对强化学习的基本理论进行介绍; 随后对同策略和异策略强化学习算法进行简要介绍; 接着介绍经验回放(Experience replay, ER)问题的两种主流解决方案, 包括经验利用和经验增广; 最后对相关的研究工作进行总结和展望.
关键词
深度强化学习?/ 异策略?/ 经验回放?/ 人工智能




1????深度强化学习理论基础


![]()


















2????经验回放机制






















![]()




















![]()
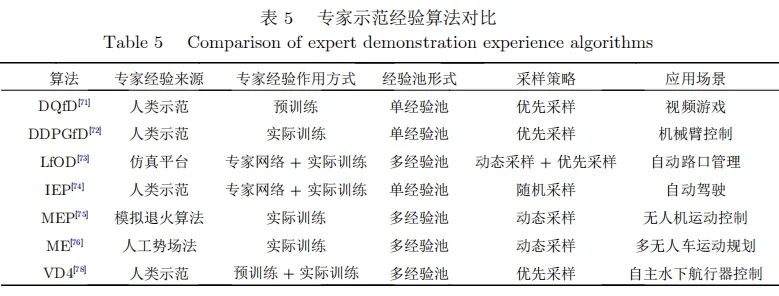









3????总结与展望




声明:公众号转载的文章及图片出于非商业性的教育和科研目的供大家参考和探讨,并不意味着支持其观点或证实其内容的真实性。版权归原作者所有,如转载稿涉及版权等问题,请立即联系我们删除。
“人工智能技术与咨询”? 发布
文章来源:https://blog.csdn.net/renhongxia1/article/details/135191127
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!