【 AI 两步实现文本 转 语音】
2023-12-18 15:22:08
基于hugging face 中 XTTS-v2 模型做文本转语音,此模型支持17种语言
1.登录hugging face 官网
https://huggingface.curated.co/ 或者 https://hf-mirror.com/models
找到models处下载XTTS-V2
如果你全程可以联网(/huggingface.co)直接步骤2
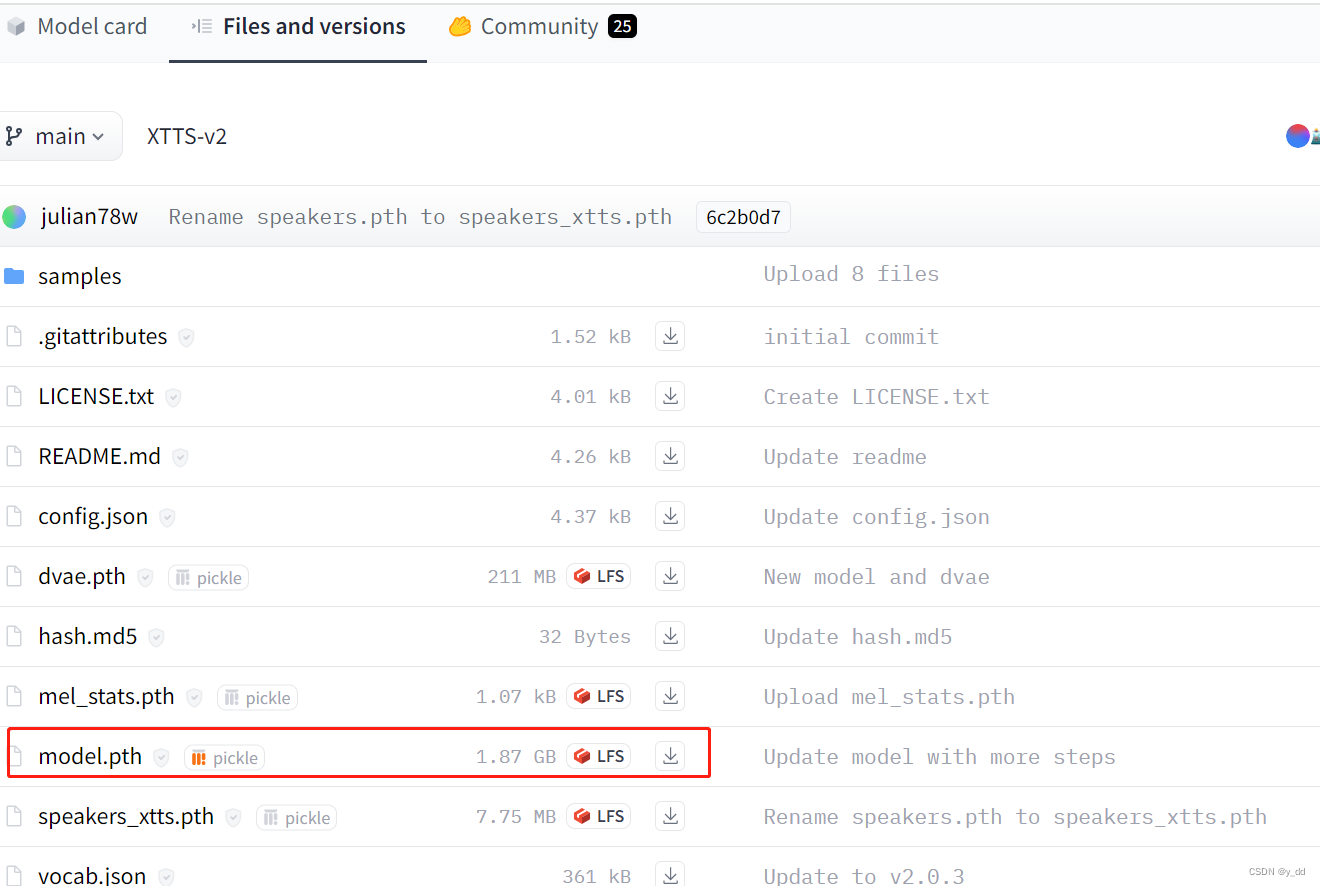
搜索模型XTTS-V2,选Files and Versions下载所有文件,其中红框选出来的是训练好的模型
2.生成语音
from TTS.api import TTS
tts = TTS("tts_models/multilingual/multi-dataset/xtts_v2", gpu=True)
# generate speech by cloning a voice using default settings
tts.tts_to_file(text="It took me quite a long time to develop a voice, and now that I have it I'm not going to be silent.",
file_path="output.wav",
speaker_wav="/path/to/target/speaker.wav",
language="en")
如果不想玩花活,这两步就可以根据文本生成语音啦!
需要说明的是:生成的方式其实有多中,可以看Model card标签
代码的参数说明一下:
text:是要转换成语音的文字
tts_models/multilingual/multi-dataset/xtts_v2不要更改,这个是有规律的命名,model名/xxx
speaker_wav:是一段现成的语音,模型根据发音的音色来生成语音,所以理论上是可以生成任何人的语音。
file_path:是生成的语音
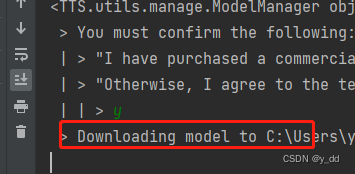
如无法联网,把你在步骤1下载好的 模型放进模型加载的路径,这个路径怎么看呢,执行的时候,可以代码执行的终端有输出日志,下面红框可以看到:
3.环境怎么配置
首先基础环境配置好.
- 要求pytorch 2.1以上,torch torchaudio等配套安装,安装方法pytorch官网
- 安装TTS,pip install TTS
其次如果使用代码的方式比如 from TTS.api import TTS 的方式,必须得把下载的包放在你运行的代码的目录里引用,下载离线包的路径,https://pypi.tuna.tsinghua.edu.cn/simple/tts/TTS-0.22.0.tar.gz
文章来源:https://blog.csdn.net/zishuijing_dd/article/details/135057985
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!