深度学习——第3章 Python程序设计语言(3.8 深度学习框架PyTorch)
3.8 深度学习框架PyTorch
目录
PyTorch简介
PyTorch是由Meta AI(Facebook)人工智能研究小组开发的一种基于Lua编写的Torch库的Python实现的深度学习库,目前被广泛应用于学术界和工业界,相较于Tensorflow2.x,PyTorch在API的设计上更加简洁、优雅和易懂。
本节内容:
- 了解PyTorch的发展流程
- 了解PyTorch相较于其他框架的优势
PyTorch的发展
“All in PyTorch”,PyTorch自从推出就获得巨大的关注并受到了很多人的喜欢,而最直观的莫过于下面数据所表现的。
下图来自Paper with code网站,颜色面积代表使用该框架的论文公开代码库的数量。
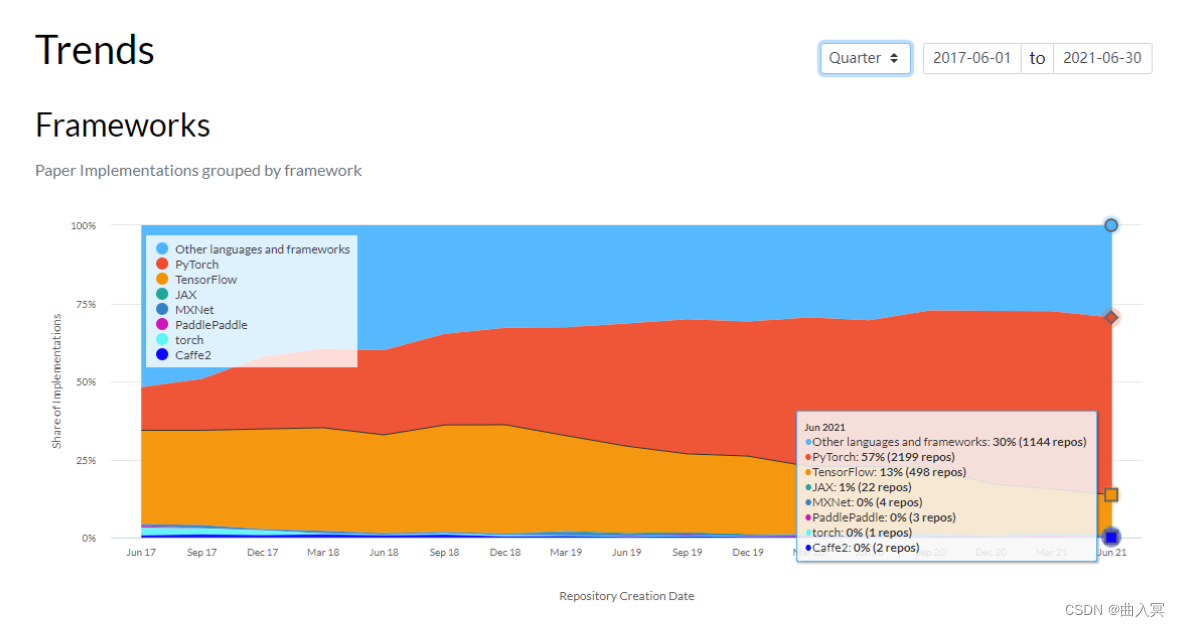
可以发现截至2021年6月,PyTorch的代码实现已经是TensorFlow实现的4倍,红色部分的PyTorch正在取代他的老大哥称霸学术圈,PyTorch会借助ONNX所带来的落地能力在工业界逐渐走向主导地位。
目前为止,PyTorch 1.x还是有不如别的框架的地方,但是PyTorch 2.x版本会给带来更大的惊喜。
PyTorch的优势
-
更加简洁,相比于其他的框架,PyTorch的框架更加简洁,易于理解。PyTorch的设计追求最少的封装,避免重复造轮子。
-
上手快,掌握numpy和基本的深度学习知识就可以上手。
-
PyTorch有着良好的文档和社区支持,作者亲自维护的论坛供用户交流和求教问题。Meta AI(Facebook AI)对PyTorch提供了强力支持,作为当今排名前三的深度学习研究机构,MAIR的支持足以确保PyTorch获得持续的开发更新。
-
项目开源,在Github上有越来越多的开源代码是使用PyTorch进行开发。
-
可以更好的调试代码,PyTorch可以让逐行执行的脚本。这就像调试NumPy一样,可以轻松访问代码中的所有对象,并且可以使用打印语句(或其他标准的Python调试)来查看方法失败的位置。
-
越来越完善的扩展库,活力旺盛,正处在当打之年。
PyTorch的安装
PyTorch的安装是学习PyTorch的第一步,也是经常出错的一步。在安装PyTorch时,通常使用的是Anaconda/miniconda+Pytorch+ IDE 的流程。
本节内容:
- Anaconda/miniconda的安装及其常见命令
- PyTorch的安装流程
- 如何选择一个适合自己的PyTorch版本
Anaconda的安装
在数据科学和深度学习中,要用到大量成熟的package。一个个安装 package 很麻烦,而且很容易出现包之间的依赖不适配的问题。而 Anaconda/miniconda的出现很好的解决了的问题,它集成了常用于科学分析(机器学习, 深度学习)的大量package,并且借助于conda可以实现对虚拟Python环境的管理。
Step 1:安装Anaconda/miniconda
登陆Anaconda | Individual Edition,选择相应系统DownLoad,此处以Windows为例(Linux可以点击链接选择合适的版本进行下载或者通过官方提供的shell脚本进行下载):
Step 2:检验是否安装成功
在开始页找到Anaconda Prompt,一般在Anaconda3的文件夹下,( Linux在终端下就行了)
Step 3:创建虚拟环境
Linux在终端(Ctrl+Alt+T)进行,Windows在Anaconda Prompt进行
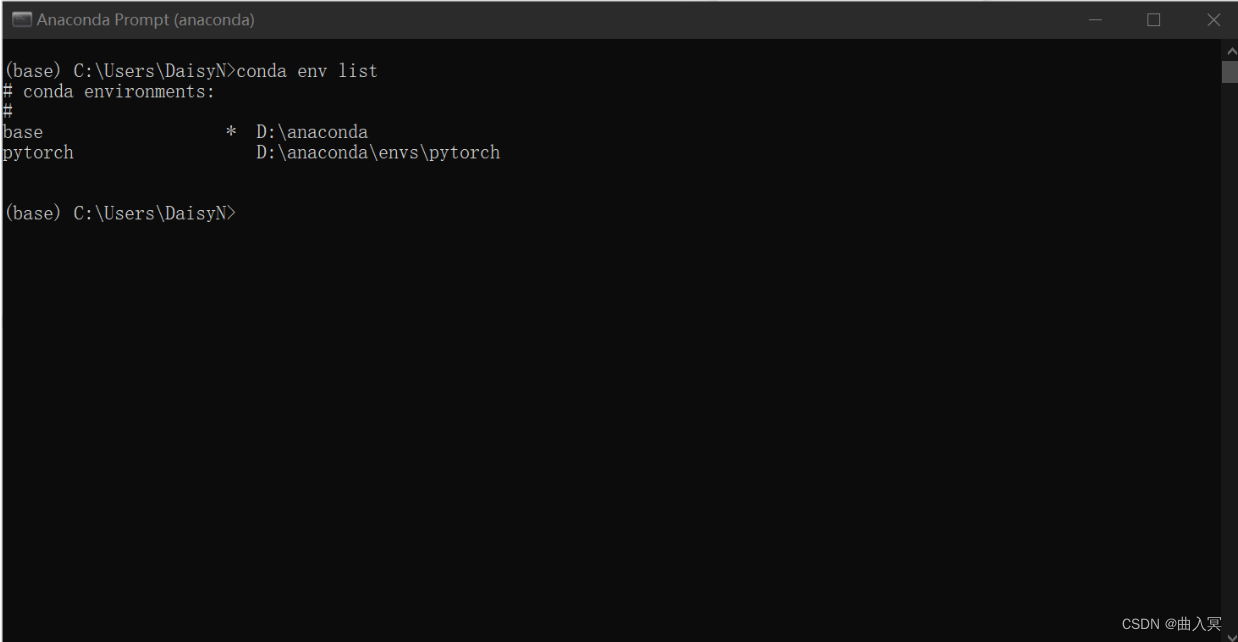
查看现存虚拟环境
查看已经安装好的虚拟环境,可以看到这里已经有两个环境存在了
conda env list
创建虚拟环境
在深度学习和机器学习中,经常会创建不同版本的虚拟环境来满足的一些需求。下面介绍创建虚拟环境的命令。
conda create -n env_name python==version
## 注:将env_name 替换成你的环境的名称,version替换成对应的版本号,eg:3.8
注:
- 这里忽略的warning,因为测试的时候已经安装后又卸载一遍,正常是不会有warning的。
- 在选择Python版本时,不要选择太高,建议选择3.6-3.8,版本过高会导致相关库不适配。
安装包
conda install package_name
## 注:package_name 替换成对应的包的名称,eg: pandas
卸载包
conda remove package_name
## 注:package_name 替换成对应的包的名称,eg: pandas
显示所有安装的包
conda list
删除虚拟环境命令
conda remove -n env_name --all
## 注:env_name 替换成对应的环境的名称
激活环境命令
conda activate env_name
## 注:env_name 替换成对应的环境的名称
退出当前环境
conda deactivate
关于更多的命令,可以查看Anaconda/miniconda官方提供的命令,官网链接:点击这里
Step 4:换源
在安装package时,经常会使用pip install package_name和conda install package_name 的命令,但是一些package下载速度会很慢,因此需要进行换源,换成国内源,加快的下载速度。以下便是两种对应方式的永久换源。如果仅仅想为单次下载换源可以使用pip install package_name -i https://pypi.tuna.tsinghua.edu.cn/simple进行下载。
pip换源
Linux:
Linux下的换源,首先需要在用户目录下新建文件夹.pip,并且在文件夹内新建文件pip.conf,具体命令如下
cd ~
mkdir .pip/
vi pip.conf
随后,需要在pip.conf添加下方的内容:
[global]
index-url = http://pypi.douban.com/simple
[install]
use-mirrors =true
mirrors =http://pypi.douban.com/simple/
trusted-host =pypi.douban.com
Windows:
1、文件管理器文件路径地址栏敲:%APPDATA% 回车,快速进入 C:\Users\电脑用户\AppData\Roaming 文件夹中
2、新建 pip 文件夹并在文件夹中新建 pip.ini 配置文件
3、需要在pip.ini 配置文件内容,可以选择使用记事本打开,输入以下内容,并按下ctrl+s保存,在这里使用的是豆瓣源为例子。
[global]
index-url = http://pypi.douban.com/simple
[install]
use-mirrors =true
mirrors =http://pypi.douban.com/simple/
trusted-host =pypi.douban.com
conda换源(清华源)官方换源帮助
Windows系统:
TUNA 提供了 Anaconda 仓库与第三方源的镜像,各系统都可以通过修改用户目录下的 .condarc 文件。Windows 用户无法直接创建名为 .condarc 的文件,可先执行conda config --set show_channel_urls yes生成该文件之后再修改。
完成这一步后,需要修改C:\Users\User_name\.condarc这个文件,打开后将文件里原始内容删除,将下面的内容复制进去并保存。
channels:
- defaults
show_channel_urls: true
default_channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2
custom_channels:
conda-forge: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
msys2: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
bioconda: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
menpo: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
pytorch: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
simpleitk: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
这一步完成后,需要打开Anaconda Prompt 运行 conda clean -i 清除索引缓存,保证用的是镜像站提供的索引。
Linux系统:
在Linux系统下,还是需要修改.condarc来进行换源
cd ~
vi .condarc
在vim下,需要输入i进入编辑模式,将上方内容粘贴进去,按ESC退出编辑模式,输入:wq保存并退出
可以通过conda config --show default_channels检查下是否换源成功,如果出现下图内容,即代表换源成功。
同时,仍然需要conda clean -i 清除索引缓存,保证用的是镜像站提供的索引。
查看显卡
该部分如果仅仅只有CPU或者集显的小伙伴们可以跳过该部分
windows:
可以通过在cmd/terminal中输入nvidia-smi(Linux和Win命令一样)、使用NVIDIA控制面板和使用任务管理器查看自己是否有NVIDIA的独立显卡及其型号
linux:
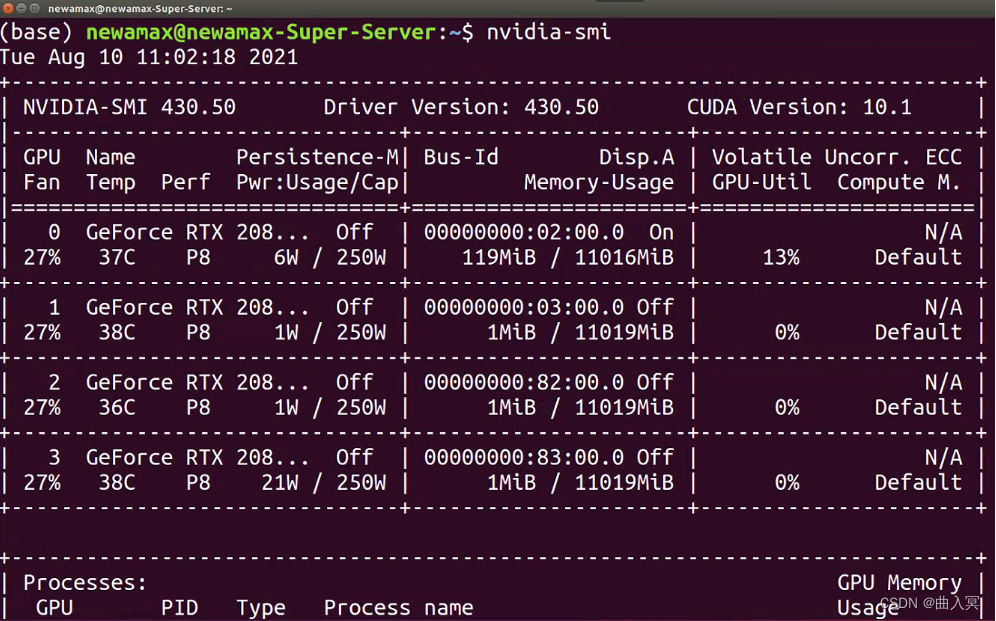
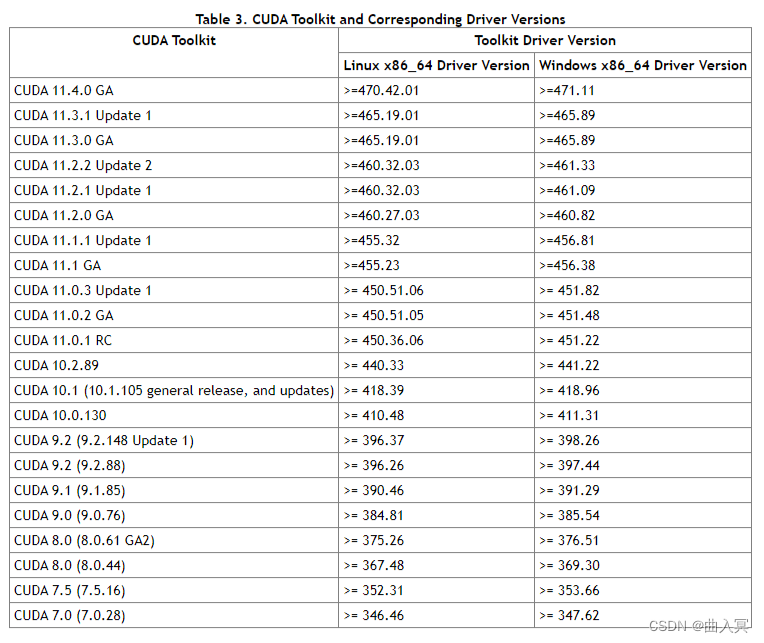
需要看下版本号,看自己可以兼容的CUDA版本,等会安装PyTorch时是可以向下兼容的。具体适配表如下图所示。
安装PyTorch
Step 1:登录PyTorch官网
Step 2:Install
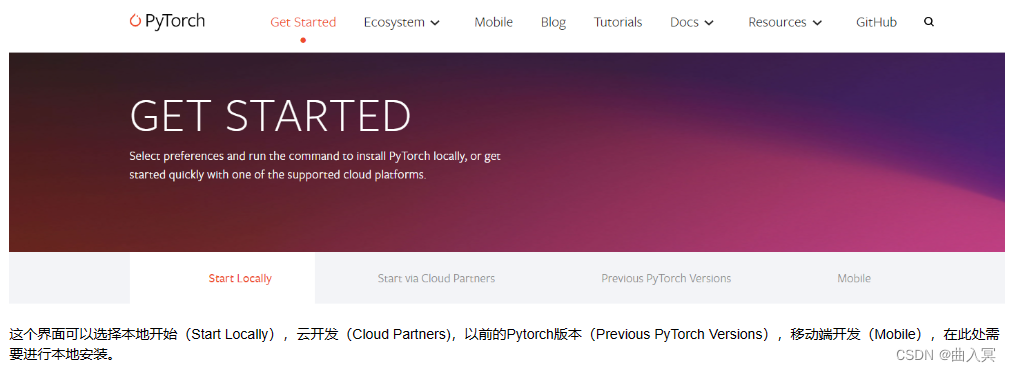
这个界面可以选择本地开始(Start Locally),云开发(Cloud Partners),以前的Pytorch版本(Previous PyTorch Versions),移动端开发(Mobile),在此处需要进行本地安装。
Step 3:选择命令
需要结合自己电脑的实际情况选择命令并复制下来,然后使用conda下载或者pip下载(建议conda安装)
打开Terminal,输入conda activate env_name(env_name 为你对应的环境名称),切换到对应的环境下面,就可以进行PyTorch的安装了。
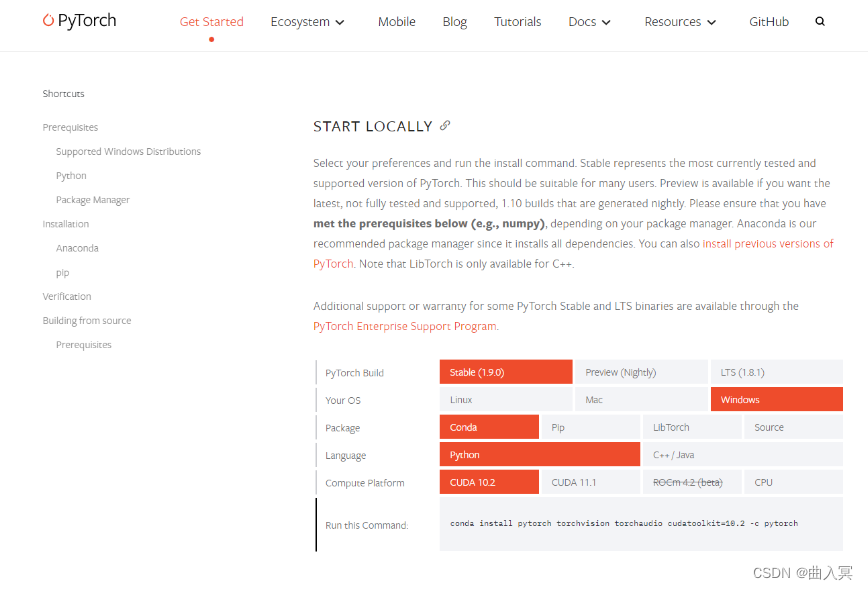
注:
-
Stable代表的是稳定版本,Preview代表的是先行版本
-
可以结合电脑是否有显卡,选择CPU版本还是CUDA版本,CUDA版本需要拥有独显且是NVIDIA的GPU
-
官方建议使用Anaconda/miniconda来进行管理
-
关于安装的系统要求
- Windows:
- Windows 7及更高版本;建议使用Windows 10或者更高的版本
- Windows Server 2008 r2 及更高版本
- Linux:以常见的CentOS和Ubuntu为例
- CentOS, 最低版本7.3-1611
- Ubuntu, 最低版本 13.04,这里会导致cuda安装的最大版本不同
- macOS:
- macOS 10.10及其以上
- Windows:
-
有些电脑所支持的cuda版本<10.2,此时需要进行手动降级,即就是cudatoolkit = 你所适合的版本,但是这里需要注意下一定要保持PyTorch和cudatoolkit的版本适配。查看Previous PyTorch Versions | PyTorch
Step 4:在线下载
如果使用的Anaconda Prompt进行下载的话,需要先通过conda activate env_name,激活的虚拟环境中去,再输入命令。
注: 需要要把下载指令后面的 -c pytorch 去掉以保证使用清华源下载,否则还是默认从官网下载。
Step 5:离线下载
Windows:
在安装的过程中,可能会出现一些奇奇怪怪的问题,导致在线下载不成功,也可以使用离线下载的方法进行。
下载地址:https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/
通过上面下载地址,需要下载好对应版本的pytorch和 torchvision 包,然后打开Anaconda Prompt/Terminal中,进入安装的路径下。
cd package_location
conda activate env_name
接下来输入以下命令安装两个包
conda install --offline pytorch压缩包的全称(后缀都不能忘记)
conda install --offline torchvision压缩包的全称(后缀都不能忘记)
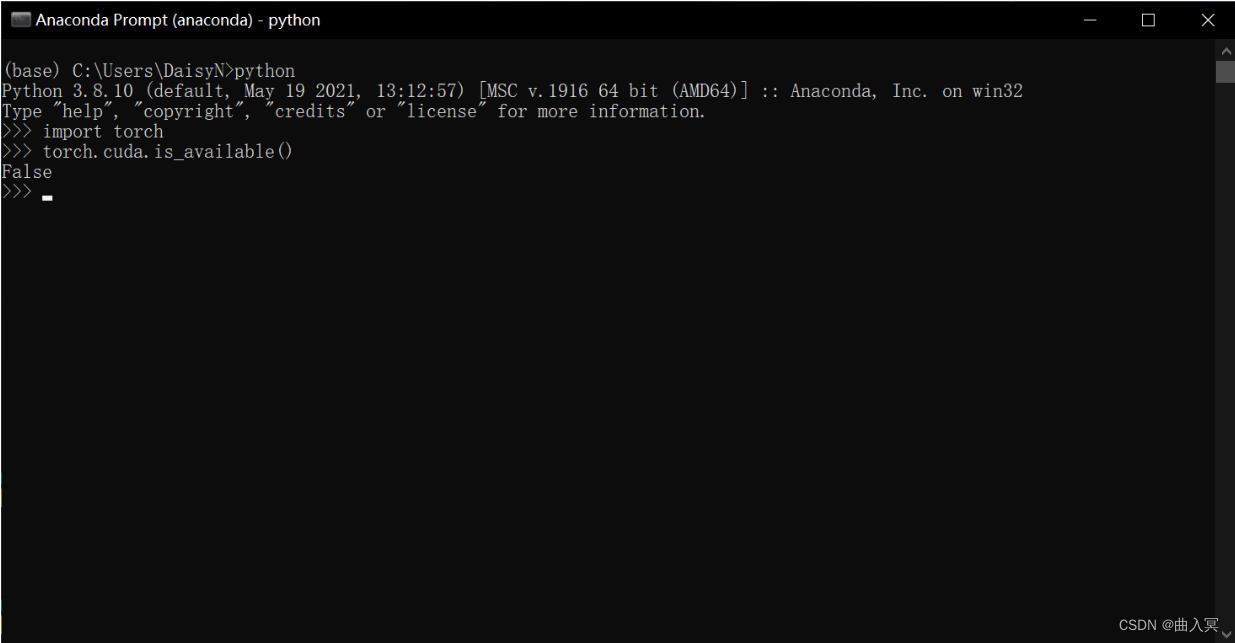
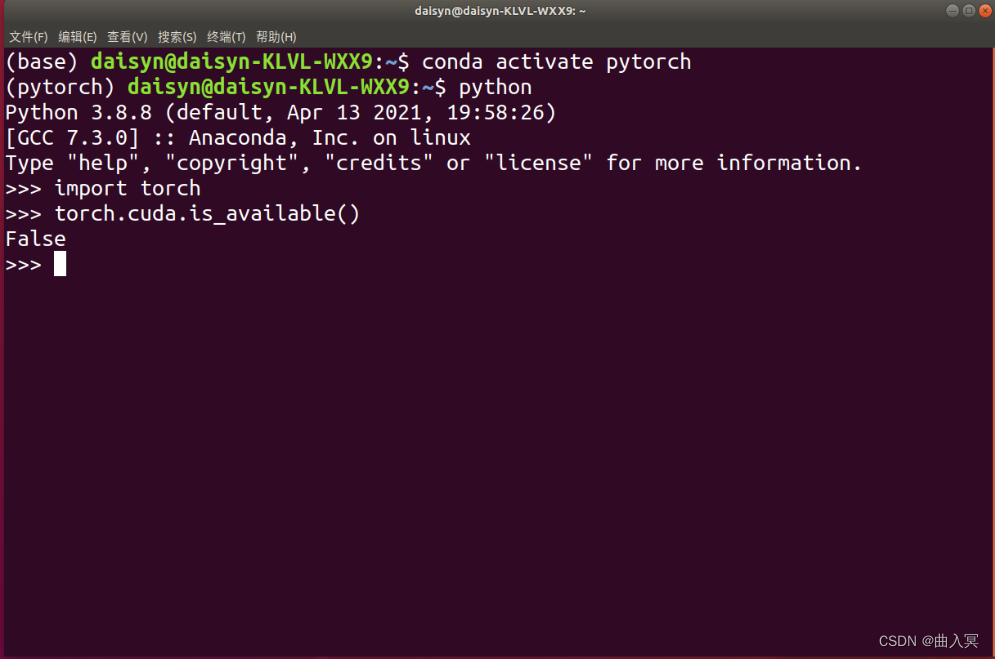
Step 6:检验是否安装成功
进入所在的虚拟环境,紧接着输入python,在输入下面的代码。
import torch
torch.cuda.is_available()
False
这条命令意思是检验是否可以调用cuda,如果安装的是CPU版本的话会返回False,能够调用GPU的会返回True。一般这个命令不报错的话就证明安装成功。
- Windows系统
- Linux系统
PyTorch的安装绝对是一个容易上火的过程,而且网络上的教程很可能对应早期的版本,或是会出现一些奇奇怪怪的问题,但是别担心,多装几次多遇到点奇奇怪怪的问题就好了!
PyCharm安装
VSCode这些也可以进行代码调戏,安装PyCharm非必须操作。
Linux,Windows此处操作相同,建议Windows的同学安装Pycharm即可,因为在Linux上pycharm并不是主流IDE。
Step 1:进入官网下载
如果是学生的话可以使用学生邮箱注册并下载Professional版本,Community版本也基本能满足的日常需求。
Step 2:配置环境
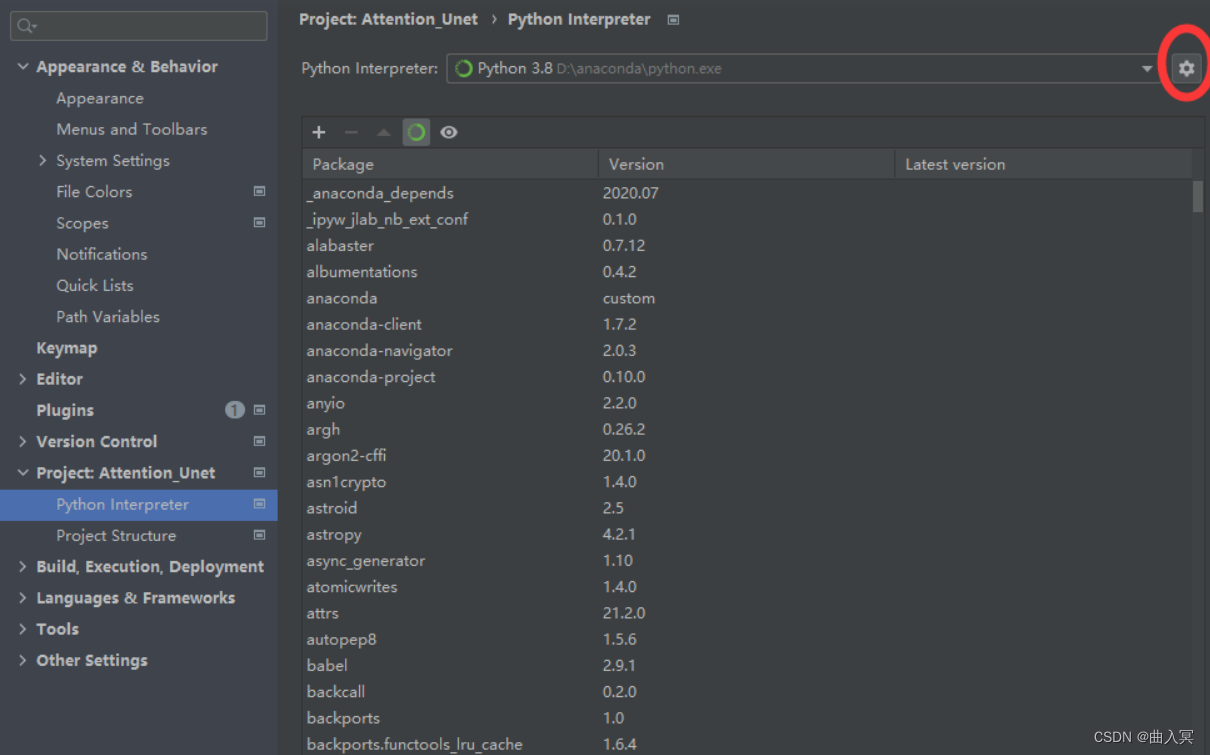
需要将虚拟环境设为的编译器,具体操作:File --> Settings --> Project:你的项目名称–> Python Interpreter
进去后,可以看见他使用的是默认的base环境,现在需要将这个环境设置成的test环境,点击齿轮,选择Add
点击Conda Environment ,选择Existing environment,将Interpreter设置为test环境下的python.exe
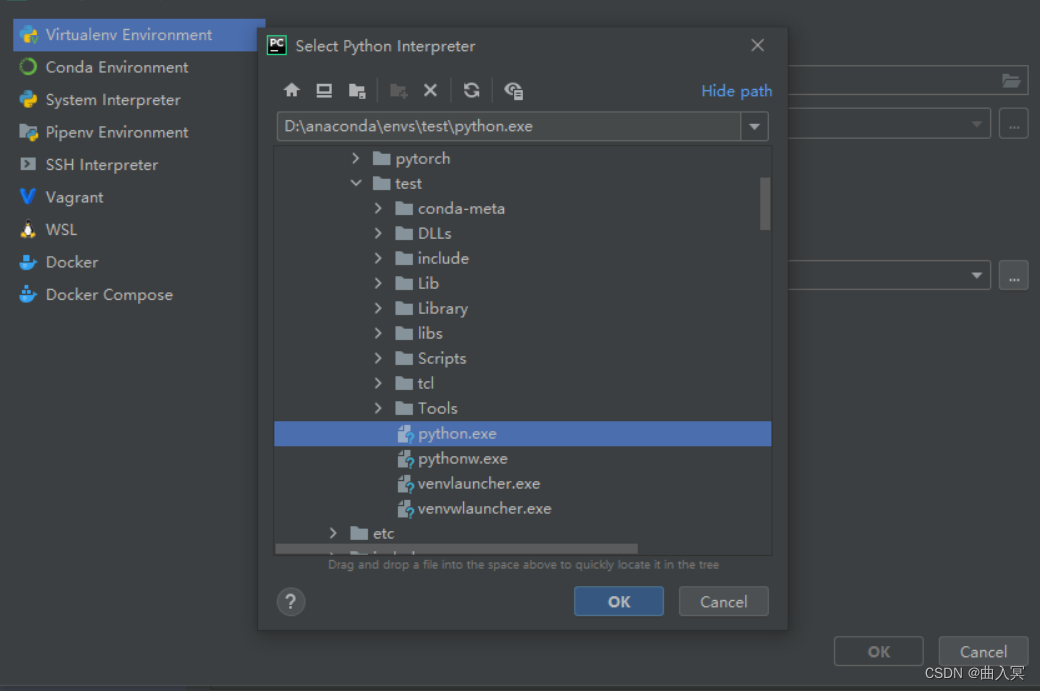
注:如果在pycharm的环境时,想进入的虚拟环境,要使用conda activate 名称
PyTorch相关资源
PyTorch之所以被越来越多的人使用,不仅在于其完备的教程,还受益于许多相关的资源和完善的论坛。
- Awesome-pytorch-list:目前已获12K Star,包含了NLP,CV,常见库,论文实现以及Pytorch的其他项目。
- PyTorch官方文档:官方发布的文档,十分丰富。
- Pytorch-handbook:GitHub上已经收获14.8K,pytorch手中书。
- PyTorch官方社区:PyTorch拥有一个活跃的社区,在这里你可以和开发pytorch的人们进行交流。
- PyTorch官方tutorials:官方编写的tutorials,可以结合colab边动手边学习
- 动手学深度学习:动手学深度学习是由李沐老师主讲的一门深度学习入门课,拥有成熟的书籍资源和课程资源,在B站,Youtube均有回放。
- Awesome-PyTorch-Chinese:常见的中文优质PyTorch资源
- labml.ai Deep Learning Paper Implementations:手把手实现经典网络代码
- YSDA course in Natural Language Processing:YSDA course in Natural Language Processing
- huggingface:hugging face
- ModelScope: 魔搭社区
除此之外,还有很多学习pytorch的资源在b站,stackoverflow,知乎等。
张量
本节介绍张量,以帮助大家建立起对数据的描述,随后再介绍张量的运算,最后再讲PyTorch中所有神经网络的核心包 autograd ,也就是自动微分,了解完这些内容就可以较好地理解PyTorch代码了。在深度学习中,通常将数据以张量的形式进行表示,比如用三维张量表示一个RGB图像,四维张量表示视频。
本节内容:
- 张量的简介
- PyTorch如何创建张量
- PyTorch中张量的操作
- PyTorch中张量的广播机制
简介
几何代数中定义的张量是基于向量和矩阵的推广,比如可以将标量视为零阶张量,矢量可以视为一阶张量,矩阵就是二阶张量。
| 张量维度 | 代表含义 |
|---|---|
| 0维张量 | 代表的是标量(数字) |
| 1维张量 | 代表的是向量 |
| 2维张量 | 代表的是矩阵 |
| 3维张量 | 时间序列数据 股价 文本数据 单张彩色图片(RGB) |
张量是现代机器学习的基础。它的核心是一个数据容器,多数情况下,它包含数字,有时候它也包含字符串,但这种情况比较少。因此可以把它想象成一个数字的水桶。
这里有一些存储在各种类型张量的公用数据集类型:
- 3维 = 时间序列
- 4维 = 图像
- 5维 = 视频
例子:一个图像可以用三个字段表示:
(width, height, channel) = 3D
但是,在机器学习工作中,经常要处理不止一张图片或一篇文档——要处理一个集合。可能有10,000张郁金香的图片,这意味着,将用到4D张量:
(batch_size, width, height, channel) = 4D
在PyTorch中, torch.Tensor 是存储和变换数据的主要工具。如果你之前用过NumPy,你会发现 Tensor 和NumPy的多维数组非常类似。然而,Tensor 提供GPU计算和自动求梯度等更多功能,这些使 Tensor 这一数据类型更加适合深度学习。
创建tensor
在接下来的内容中,将介绍几种常见的创建tensor的方法。
- 随机初始化矩阵
可以通过torch.rand()的方法,构造一个随机初始化的矩阵:
import torch
x = torch.rand(4, 3)
print(x)
运行结果:
tensor([[0.4808, 0.8716, 0.9836],
[0.9629, 0.8222, 0.8431],
[0.1086, 0.0721, 0.9835],
[0.4140, 0.5783, 0.6901]])
- 全0矩阵的构建
可以通过torch.zeros()构造一个矩阵全为 0,并且通过dtype设置数据类型为 long。除此以外,还可以通过torch.zero_()和torch.zeros_like()将现有矩阵转换为全0矩阵。
import torch
x = torch.zeros(4, 3, dtype=torch.long)
print(x)
输出结果:
tensor([[0, 0, 0],
[0, 0, 0],
[0, 0, 0],
[0, 0, 0]])
- 张量的构建
可以通过torch.tensor()直接使用数据,构造一个张量:
import torch
x = torch.tensor([5.5, 3])
print(x)
输出结果:
tensor([5.5000, 3.0000])
- 基于已经存在的 tensor,创建一个 tensor :
x = x.new_ones(4, 3, dtype=torch.double)
## 创建一个新的全1矩阵tensor,返回的tensor默认具有相同的torch.dtype和torch.device
## 也可以像之前的写法 x = torch.ones(4, 3, dtype=torch.double)
print(x)
x = torch.randn_like(x, dtype=torch.float)
## 重置数据类型
print(x)
## 结果会有一样的size
## 获取它的维度信息
print(x.size())
print(x.shape)
输出结果:
tensor([[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.]], dtype=torch.float64)
tensor([[-0.2951, 1.4532, 0.8202],
[-0.1885, -0.7012, -2.1650],
[ 1.7449, 0.4209, -0.1335],
[-1.4856, -0.4916, 0.5472]])
torch.Size([4, 3])
torch.Size([4, 3])
返回的torch.Size其实是一个tuple,?持所有tuple的操作。可以使用索引操作取得张量的长、宽等数据维度。
- 常见的构造Tensor的方法:
| 函数 | 功能 |
|---|---|
| Tensor(sizes) | 基础构造函数 |
| tensor(data) | 类似于np.array |
| ones(sizes) | 全1 |
| zeros(sizes) | 全0 |
| eye(sizes) | 对角为1,其余为0 |
| arange(s,e,step) | 从s到e,步长为step |
| linspace(s,e,steps) | 从s到e,均匀分成step份 |
| rand/randn(sizes) | rand是[0,1)均匀分布;randn是服从N(0,1)的正态分布 |
| normal(mean,std) | 正态分布(均值为mean,标准差是std) |
| randperm(m) | 随机排列 |
张量的操作
在接下来的内容中,将介绍几种常见的张量的操作方法:
- 加法操作:
import torch
## 方式1
y = torch.rand(4, 3)
print(x + y)
## 方式2
print(torch.add(x, y))
## 方式3 in-place,原值修改
y.add_(x)
print(y)
运行结果:
tensor([[-0.1503, 1.6809, 1.0952],
[ 0.1438, 0.2069, -1.3120],
[ 2.0006, 0.7256, 0.2280],
[-0.5697, -0.1095, 1.3083]])
tensor([[-0.1503, 1.6809, 1.0952],
[ 0.1438, 0.2069, -1.3120],
[ 2.0006, 0.7256, 0.2280],
[-0.5697, -0.1095, 1.3083]])
tensor([[-0.1503, 1.6809, 1.0952],
[ 0.1438, 0.2069, -1.3120],
[ 2.0006, 0.7256, 0.2280],
[-0.5697, -0.1095, 1.3083]])
- 索引操作:(类似于numpy)
需要注意的是:索引出来的结果与原数据共享内存,修改一个,另一个会跟着修改。如果不想修改,可以考虑使用copy()等方法
import torch
x = torch.rand(4,3)
## 取第二列
print(x[:, 1])
#运行结果:tensor([0.7538, 0.2988, 0.1604, 0.4605])
y = x[0,:]
y += 1
print(y)
print(x[0, :]) ## 源tensor也被改了了
#运行结果:
#tensor([1.2227, 1.7538, 1.4554])
#tensor([1.2227, 1.7538, 1.4554])
- 维度变换
张量的维度变换常见的方法有torch.view()和torch.reshape(),下面将介绍第一中方法torch.view():
x = torch.randn(4, 4)
y = x.view(16)
z = x.view(-1, 8) ## -1是指这一维的维数由其他维度决定
print(x.size(), y.size(), z.size())
#运行结果:torch.Size([4, 4]) torch.Size([16]) torch.Size([2, 8])
注: torch.view() 返回的新tensor与源tensor共享内存(其实是同一个tensor),更改其中的一个,另外一个也会跟着改变。(顾名思义,view()仅仅是改变了对这个张量的观察角度)
x += 1
print(x)
print(y) ## 也加了了1
运行结果:
tensor([[ 1.0520, -0.8705, -0.4764, 0.6744],
[ 2.2737, 1.6999, 0.7740, 1.8714],
[ 1.8238, 1.1992, 0.7306, 1.0122],
[-0.3027, 1.4095, 0.2391, 1.8313]])
tensor([ 1.0520, -0.8705, -0.4764, 0.6744, 2.2737, 1.6999, 0.7740, 1.8714,
1.8238, 1.1992, 0.7306, 1.0122, -0.3027, 1.4095, 0.2391, 1.8313])
上面说过torch.view()会改变原始张量,但是很多情况下,希望原始张量和变换后的张量互相不影响。为为了使创建的张量和原始张量不共享内存,需要使用第二种方法torch.reshape(), 同样可以改变张量的形状,但是此函数并不能保证返回的是其拷贝值,所以官方不推荐使用。推荐的方法是先用 clone() 创造一个张量副本然后再使用 torch.view()进行函数维度变换 。
注:使用 clone() 还有一个好处是会被记录在计算图中,即梯度回传到副本时也会传到源 Tensor 。
- 取值操作
如果有一个元素tensor,可以使用.item()来获得这个value,而不获得其他性质:
import torch
x = torch.randn(1)
print(type(x))
print(type(x.item()))
PyTorch中的 Tensor 支持超过一百种操作,包括转置、索引、切片、数学运算、线性代数、随机数等等,具体使用方法可参考官方文档。
广播机制
当对两个形状不同的 Tensor 按元素运算时,可能会触发广播(broadcasting)机制:先适当复制元素使这两个 Tensor 形状相同后再按元素运算。
x = torch.arange(1, 3).view(1, 2)
print(x)
y = torch.arange(1, 4).view(3, 1)
print(y)
print(x + y)
运行结果:
tensor([[1, 2]])
tensor([[1],
[2],
[3]])
tensor([[2, 3],
[3, 4],
[4, 5]])
由于x和y分别是1行2列和3行1列的矩阵,如果要计算x+y,那么x中第一行的2个元素被广播 (复制)到了第二行和第三行,?y中第?列的3个元素被广播(复制)到了第二列。如此,就可以对2个3行2列的矩阵按元素相加。
自动求导
PyTorch 中,所有神经网络的核心是 autograd 包。autograd包为张量上的所有操作提供了自动求导机制。它是一个在运行时定义 ( define-by-run )的框架,这意味着反向传播是根据代码如何运行来决定的,并且每次迭代可以是不同的。
本节内容:
- autograd的求导机制
- 梯度的反向传播
Autograd简介
torch.Tensor 是这个包的核心类。如果设置它的属性 .requires_grad 为 True,那么它将会追踪对于该张量的所有操作。当完成计算后可以通过调用 .backward(),来自动计算所有的梯度。这个张量的所有梯度将会自动累加到.grad属性。
注意:在 y.backward() 时,如果 y 是标量,则不需要为 backward() 传入任何参数;否则,需要传入一个与 y 同形的Tensor。
要阻止一个张量被跟踪历史,可以调用.detach()方法将其与计算历史分离,并阻止它未来的计算记录被跟踪。为了防止跟踪历史记录(和使用内存),可以将代码块包装在 with torch.no_grad(): 中。在评估模型时特别有用,因为模型可能具有 requires_grad = True 的可训练的参数,但是不需要在此过程中对他们进行梯度计算。
还有一个类对于autograd的实现非常重要:Function。Tensor 和 Function 互相连接生成了一个无环图 (acyclic graph),它编码了完整的计算历史。每个张量都有一个.grad_fn属性,该属性引用了创建 Tensor 自身的Function(除非这个张量是用户手动创建的,即这个张量的grad_fn是 None )。下面给出的例子中,张量由用户手动创建,因此grad_fn返回结果是None。
from __future__ import print_function
import torch
x = torch.randn(3,3,requires_grad=True)
print(x.grad_fn)
#输出结果:None
如果需要计算导数,可以在 Tensor 上调用 .backward()。如果 Tensor 是一个标量(即它包含一个元素的数据),则不需要为 backward() 指定任何参数,但是如果它有更多的元素,则需要指定一个gradient参数,该参数是形状匹配的张量。
创建一个张量并设置requires_grad=True用来追踪其计算历史
x = torch.ones(2, 2, requires_grad=True)
print(x)
#输出结果:
#tensor([[1., 1.],
#[1., 1.]], requires_grad=True)
对这个张量做一次运算:
y = x**2
print(y)
y是计算的结果,所以它有grad_fn属性。
print(y.grad_fn)
对 y 进行更多操作
z = y * y * 3
out = z.mean()
print(z, out)
.requires_grad_(...) 原地改变了现有张量的requires_grad标志。如果没有指定的话,默认输入的这个标志是 False。
a = torch.randn(2, 2) ## 缺失情况下默认 requires_grad = False
a = ((a * 3) / (a - 1))
print(a.requires_grad)
a.requires_grad_(True)
print(a.requires_grad)
b = (a * a).sum()
print(b.grad_fn)
输出结果:
False
True
<SumBackward0 object at 0x000002C55CC13400>
梯度
现在开始进行反向传播,因为 out 是一个标量,因此out.backward()和 out.backward(torch.tensor(1.)) 等价。
out.backward()
输出导数 d(out)/dx
print(x.grad)
输出结果:tensor([[3., 3.],
[3., 3.]])
数学上,若有向量函数 y ? = f ( x ? ) \vec{y}=f(\vec{x}) y?=f(x),那么 y ? \vec{y} y? 关于 x ? \vec{x} x 的梯度就是一个雅可比矩阵:
J = ( ? y 1 ? x 1 ? ? y 1 ? x n ? ? ? ? y m ? x 1 ? ? y m ? x n ) J=\left(\begin{array}{ccc}\frac{\partial y_{1}}{\partial x_{1}} & \cdots & \frac{\partial y_{1}}{\partial x_{n}} \\ \vdots & \ddots & \vdots \\ \frac{\partial y_{m}}{\partial x_{1}} & \cdots & \frac{\partial y_{m}}{\partial x_{n}}\end{array}\right) J= ??x1??y1????x1??ym????????xn??y1????xn??ym??? ?
而 torch.autograd 这个包就是用来计算一些雅可比矩阵的乘积的。例如,如果
v
v
v 是一个标量函数
l
=
g
(
y
?
)
l = g(\vec{y})
l=g(y?) 的梯度:
v
=
(
?
l
?
y
1
?
?
l
?
y
m
)
v=\left(\begin{array}{lll}\frac{\partial l}{\partial y_{1}} & \cdots & \frac{\partial l}{\partial y_{m}}\end{array}\right)
v=(?y1??l?????ym??l??)
由链式法则,可以得到:
v J = ( ? l ? y 1 ? ? l ? y m ) ( ? y 1 ? x 1 ? ? y 1 ? x n ? ? ? ? y m ? x 1 ? ? y m ? x n ) = ( ? l ? x 1 ? ? l ? x n ) v J=\left(\begin{array}{lll}\frac{\partial l}{\partial y_{1}} & \cdots & \frac{\partial l}{\partial y_{m}}\end{array}\right)\left(\begin{array}{ccc}\frac{\partial y_{1}}{\partial x_{1}} & \cdots & \frac{\partial y_{1}}{\partial x_{n}} \\ \vdots & \ddots & \vdots \\ \frac{\partial y_{m}}{\partial x_{1}} & \cdots & \frac{\partial y_{m}}{\partial x_{n}}\end{array}\right)=\left(\begin{array}{lll}\frac{\partial l}{\partial x_{1}} & \cdots & \frac{\partial l}{\partial x_{n}}\end{array}\right) vJ=(?y1??l?????ym??l??) ??x1??y1????x1??ym????????xn??y1????xn??ym??? ?=(?x1??l?????xn??l??)
注意:grad在反向传播过程中是累加的(accumulated),这意味着每一次运行反向传播,梯度都会累加之前的梯度,所以一般在反向传播之前需把梯度清零。
## 再来反向传播?一次,注意grad是累加的
out2 = x.sum()
out2.backward()
print(x.grad)
out3 = x.sum()
x.grad.data.zero_()
out3.backward()
print(x.grad)
输出结果:
tensor([[4., 4.],
[4., 4.]])
tensor([[1., 1.],
[1., 1.]])
现在来看一个雅可比向量积的例子:
x = torch.randn(3, requires_grad=True)
print(x)
y = x * 2
i = 0
while y.data.norm() < 1000:
y = y * 2
i = i + 1
print(y)
print(i)
输出结果:
tensor([-0.8184, -1.6053, -0.1937], requires_grad=True)
tensor([ -838.0233, -1643.7988, -198.3497], grad_fn=<MulBackward0>)
9
在这种情况下,y 不再是标量。torch.autograd 不能直接计算完整的雅可比矩阵,但是如果只想要雅可比向量积,只需将这个向量作为参数传给 backward:
v = torch.tensor([0.1, 1.0, 0.0001], dtype=torch.float)
y.backward(v)
print(x.grad)
也可以通过将代码块包装在 with torch.no_grad(): 中,来阻止 autograd 跟踪设置了.requires_grad=True的张量的历史记录。
print(x.requires_grad)
print((x ** 2).requires_grad)
with torch.no_grad():
print((x ** 2).requires_grad)
输出结果:
True
True
False
如果想要修改 tensor 的数值,但是又不希望被 autograd 记录(即不会影响反向传播), 那么可以对 tensor.data 进行操作。
x = torch.ones(1,requires_grad=True)
print(x.data) ## 还是一个tensor
print(x.data.requires_grad) ## 但是已经是独立于计算图之外
y = 2 * x
x.data *= 100 ## 只改变了值,不会记录在计算图,所以不会影响梯度传播
y.backward()
print(x) ## 更改data的值也会影响tensor的值
print(x.grad)
输出结果:
tensor([1.])
False
tensor([100.], requires_grad=True)
tensor([2.])
并行计算简介
在利用PyTorch做深度学习的过程中,可能会遇到数据量较大无法在单块GPU上完成,或者需要提升计算速度的场景,这时就需要用到并行计算。
完成本节内容时,需要确保电脑至少安装了一个NVIDIA GPU并安装了相关的驱动。
本节内容:
- 并行计算的简介
- CUDA简介
- 并行计算的三种实现方式
- 使用CUDA加速训练
为什么要做并行计算
深度学习的发展离不开算力的发展,GPU的出现让的模型可以训练的更快,更好。所以,如何充分利用GPU的性能来提高模型学习的效果,这一技能是必须要学习的。这一节,主要讲的就是PyTorch的并行计算。PyTorch可以在编写完模型之后,让多个GPU来参与训练,减少训练时间。你可以在命令行使用nvidia-smi命令来查看你的GPU信息和使用情况。
为什么需要CUDA
CUDA是NVIDIA提供的一种GPU并行计算框架。对于GPU本身的编程,使用的是CUDA语言来实现的。但是,在我们使用PyTorch编写深度学习代码时,使用的CUDA又是另一个意思。在PyTorch使用 CUDA表示要开始要求我们的模型或者数据开始使用GPU了。
在编写程序中,当我们使用了 .cuda() 时,其功能是让我们的模型或者数据从CPU迁移到GPU上(默认是0号GPU)当中,通过GPU开始计算。
注意:
-
我们使用GPU时使用的是
.cuda()而不是使用.gpu()。这是因为当前GPU的编程接口采用CUDA,但是市面上的GPU并不是都支持CUDA,只有部分NVIDIA的GPU才支持,AMD的GPU编程接口采用的是OpenCL,在现阶段PyTorch并不支持。 -
数据在GPU和CPU之间进行传递时会比较耗时,我们应当尽量避免数据的切换。
-
GPU运算很快,但是在使用简单的操作时,我们应该尽量使用CPU去完成。
-
当我们的服务器上有多个GPU,我们应该指明我们使用的GPU是哪一块,如果我们不设置的话,tensor.cuda()方法会默认将tensor保存到第一块GPU上,等价于tensor.cuda(0),这将有可能导致爆出
out of memory的错误。
可以通过以下两种方式继续设置:
-
#设置在文件最开始部分
import os
os.environ[“CUDA_VISIBLE_DEVICE”] = “2” # 设置默认的显卡
2. ```bash
CUDA_VISBLE_DEVICE=0,1 python train.py # 使用0,1两块GPU
常见的并行方法
网络结构分布到不同的设备中(Network partitioning)
在刚开始做模型并行的时候,这个方案使用的比较多。其中主要的思路是,将一个模型的各个部分拆分,然后将不同的部分放入到GPU来做不同任务的计算。其架构如下:
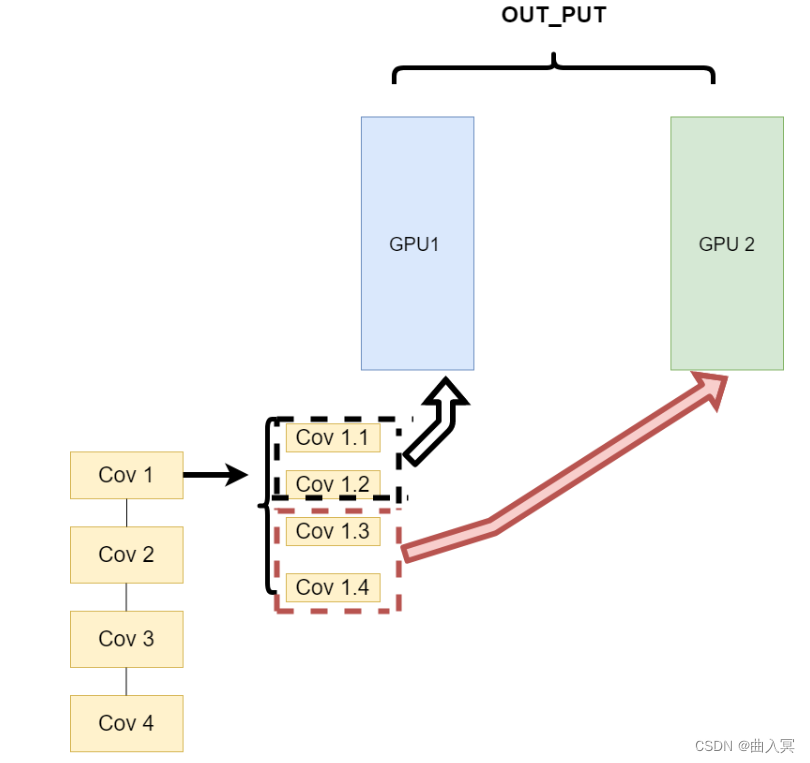
这里遇到的问题就是,不同模型组件在不同的GPU上时,GPU之间的传输就很重要,对于GPU之间的通信是一个考验。但是GPU的通信在这种密集任务中很难办到,所以这个方式慢慢淡出了视野。
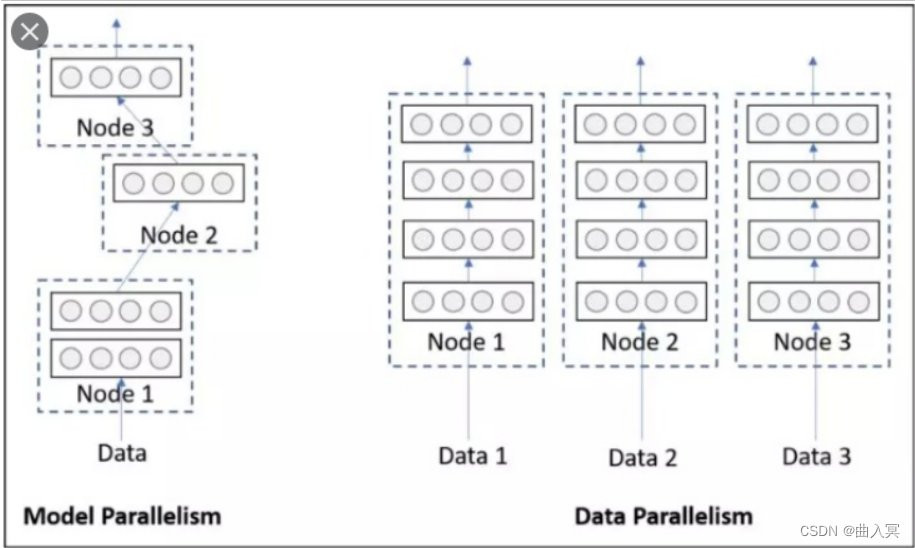
不同的数据分布到不同的设备中,执行相同的任务(Data parallelism)
第三种方式有点不一样,它的逻辑是,我不再拆分模型,我训练的时候模型都是一整个模型。但是我将输入的数据拆分。所谓的拆分数据就是,同一个模型在不同GPU中训练一部分数据,然后再分别计算一部分数据之后,只需要将输出的数据做一个汇总,然后再反传。其架构如下:
这种方式可以解决之前模式遇到的通讯问题。现在的主流方式是数据并行的方式(Data parallelism)
使用CUDA加速训练
单卡训练
在PyTorch框架下,CUDA的使用变得非常简单,我们只需要显式的将数据和模型通过.cuda()方法转移到GPU上就可加速我们的训练。如下:
model = Net()
model.cuda() # 模型显示转移到CUDA上
for image,label in dataloader:
# 图像和标签显示转移到CUDA上
image = image.cuda()
label = label.cuda()
多卡训练
PyTorch提供了两种多卡训练的方式,分别为DataParallel和DistributedDataParallel(以下我们分别简称为DP和DDP)。这两种方法中官方更推荐我们使用DDP,因为它的性能更好。但是DDP的使用比较复杂,而DP经需要改变几行代码既可以实现,所以我们这里先介绍DP,再介绍DDP。
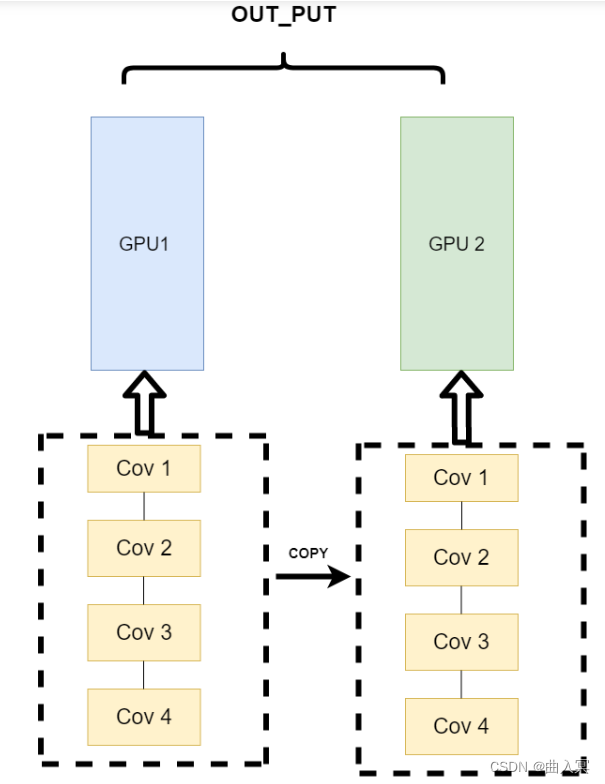
单机多卡DP
首先我们来看单机多卡DP,通常使用一种叫做数据并行 (Data parallelism) 的策略,即将计算任务划分成多个子任务并在多个GPU卡上同时执行这些子任务。主要使用到了nn.DataParallel函数,它的使用非常简单,一般我们只需要加几行代码即可实现
model = Net()
model.cuda() # 模型显示转移到CUDA上
if torch.cuda.device_count() > 1: # 含有多张GPU的卡
model = nn.DataParallel(model) # 单机多卡DP训练
除此之外,我们也可以指定GPU进行并行训练,一般有两种方式
-
nn.DataParallel函数传入device_ids参数,可以指定了使用的GPU编号model = nn.DataParallel(model, device_ids=[0,1]) # 使用第0和第1张卡进行并行训练 -
要手动指定对程序可见的GPU设备
os.environ["CUDA_VISIBLE_DEVICES"] = "1,2"
多机多卡DDP
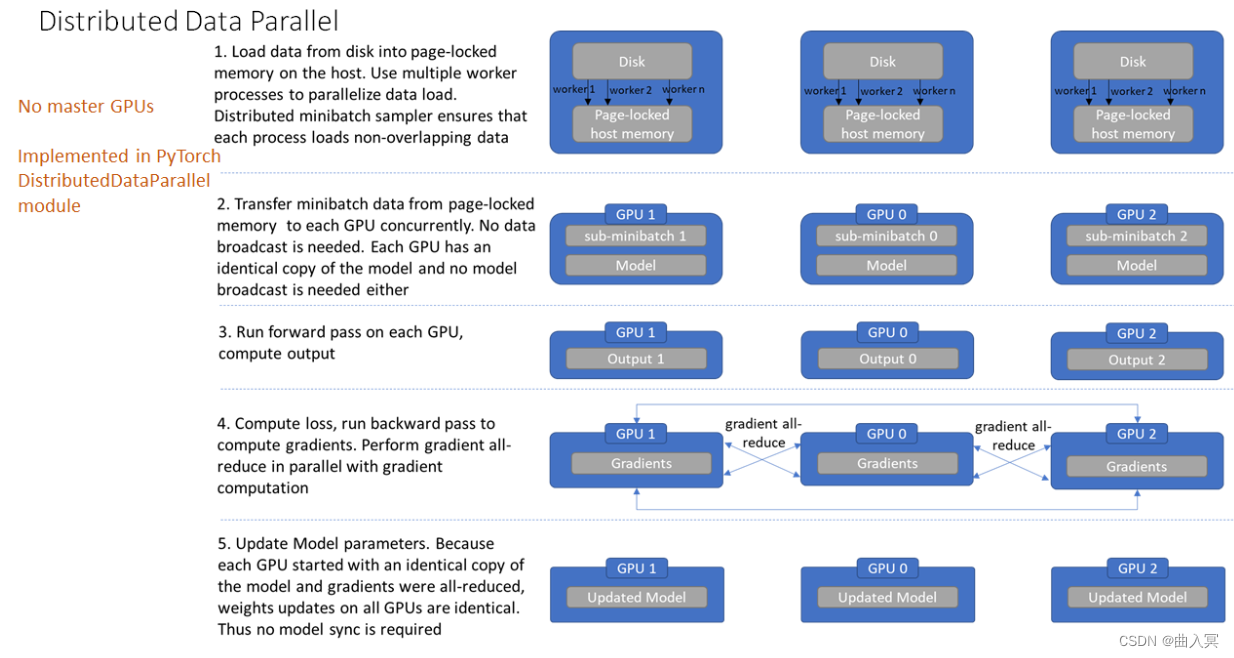
不过通过DP进行分布式多卡训练的方式容易造成负载不均衡,有可能第一块GPU显存占用更多,因为输出默认都会被gather到第一块GPU上。为此Pytorch也提供了torch.nn.parallel.DistributedDataParallel(DDP)方法来解决这个问题。
针对每个GPU,启动一个进程,然后这些进程在最开始的时候会保持一致(模型的初始化参数也一致,每个进程拥有自己的优化器),同时在更新模型的时候,梯度传播也是完全一致的,这样就可以保证任何一个GPU上面的模型参数就是完全一致的,所以这样就不会出现DataParallel那样显存不均衡的问题。不过相对应的,会比较麻烦,接下来介绍一下多机多卡DDP的使用方法。
开始之前需要先熟悉几个概念,这些还是有必要提一下的
进程组的相关概念
- GROUP:进程组,默认情况下,只有一个组,一个 job 即为一个组,也即一个 world。(当需要进行更加精细的通信时,可以通过 new_group 接口,使用 world 的子集,创建新组,用于集体通信等。)
- WORLD_SIZE:表示全局进程个数。如果是多机多卡就表示机器数量,如果是单机多卡就表示 GPU 数量。
- RANK:表示进程序号,用于进程间通讯,表征进程优先级。rank = 0 的主机为 master 节点。 如果是多机多卡就表示对应第几台机器,如果是单机多卡,由于一个进程内就只有一个 GPU,所以 rank 也就表示第几块 GPU。
- LOCAL_RANK:表示进程内,GPU 编号,非显式参数,由 torch.distributed.launch 内部指定。例如,多机多卡中 rank = 3,local_rank = 0 表示第 3 个进程内的第 1 块 GPU。
DDP的基本用法 (代码编写流程)
- 在使用
distributed包的任何其他函数之前,需要使用init_process_group初始化进程组,同时初始化distributed包。 - 使用
torch.nn.parallel.DistributedDataParallel创建 分布式模型DDP(model, device_ids=device_ids) - 使用
torch.utils.data.distributed.DistributedSampler创建 DataLoader - 使用启动工具
torch.distributed.launch在每个主机上执行一次脚本,开始训练
首先是对代码进行修改,添加参数 --local_rank
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("--local_rank", type=int) # 这个参数很重要
args = parser.parse_args()
这里的local_rank参数,可以理解为torch.distributed.launch在给一个GPU创建进程的时候,给这个进程提供的GPU号,这个是程序自动给的,不需要手动在命令行中指定这个参数。
local_rank = int(os.environ["LOCAL_RANK"]) #也可以自动获取
然后在所有和GPU相关代码的前面添加如下代码,如果不写这句代码,所有的进程都默认在你使用CUDA_VISIBLE_DEVICES参数设定的0号GPU上面启动
torch.cuda.set_device(args.local_rank) # 调整计算的位置
接下来我们得初始化backend,也就是俗称的后端,pytorch介绍了以下后端:
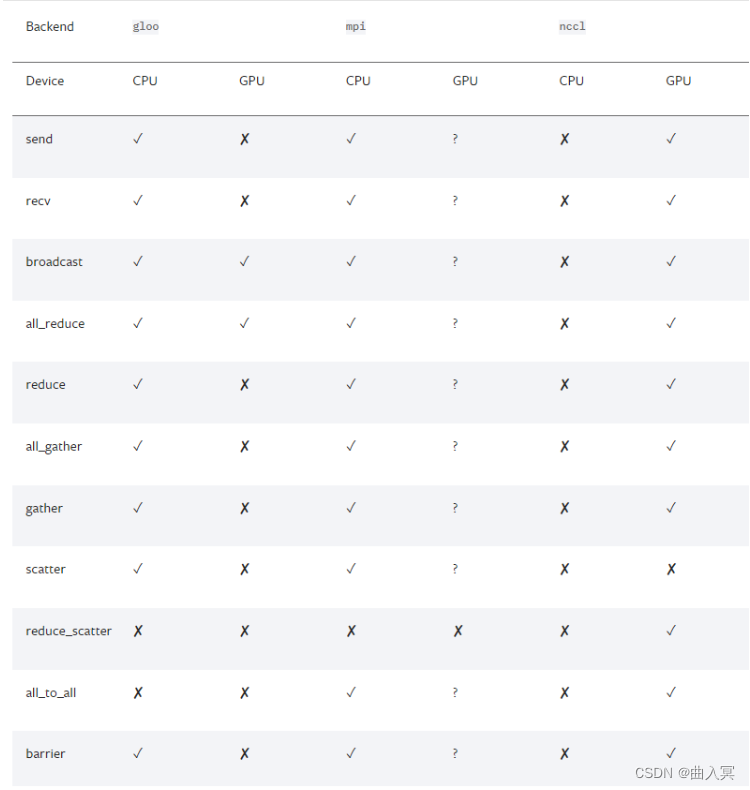
可以看到,提供了gloo,nccl,mpi,那么如何进行选择呢,官网中也给了以下建议
-
经验之谈
- 如果是使用
cpu的分布式计算, 建议使用gloo,因为表中可以看到gloo对cpu的支持是最好的 - 如果使用
gpu进行分布式计算, 建议使用nccl。
- 如果是使用
-
GPU主机
- InfiniBand连接,建议使用
nccl,因为它是目前唯一支持 InfiniBand 和 GPUDirect 的后端。 - Ethernet连接,建议使用
nccl,因为它的分布式GPU训练性能目前是最好的,特别是对于多进程单节点或多节点分布式训练。 如果在使用nccl时遇到任何问题,可以使用gloo作为后备选项。 (不过注意,对于 GPU,gloo目前的运行速度比nccl慢。)
- InfiniBand连接,建议使用
-
CPU主机
- InfiniBand连接,如果启用了IP over IB,那就使用
gloo,否则使用mpi - Ethernet连接,建议使用
gloo,除非有不得已的理由使用mpi。
- InfiniBand连接,如果启用了IP over IB,那就使用
当后端选择好了之后, 我们需要设置一下网络接口, 因为多个主机之间肯定是使用网络进行交换, 那肯定就涉及到IP之类的, 对于nccl和gloo一般会自己寻找网络接口,不过有时候如果网卡比较多的时候,就需要自己设置,可以利用以下代码
import os
# 以下二选一, 第一个是使用gloo后端需要设置的, 第二个是使用nccl需要设置的
os.environ['GLOO_SOCKET_IFNAME'] = 'eth0'
os.environ['NCCL_SOCKET_IFNAME'] = 'eth0'
可以通过以下操作知道自己的网络接口,输入
ifconfig, 然后找到自己IP地址的就是, 一般就是em0,eth0,esp2s0之类的,
从以上介绍我们可以看出, 当使用GPU的时候, nccl的效率是高于gloo的,我们一般还是会选择nccl后端,设置GPU之间通信使用的后端和端口:
# ps 检查nccl是否可用
# torch.distributed.is_nccl_available ()
torch.distributed.init_process_group(backend='nccl') # 选择nccl后端,初始化进程组
之后,使用 DistributedSampler 对数据集进行划分。它能帮助我们将每个 batch 划分成几个 partition,在当前进程中只需要获取和 rank 对应的那个 partition 进行训练:
# 创建Dataloader
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=16, sampler=train_sampler)
注意: testset不用sampler
然后使用torch.nn.parallel.DistributedDataParallel包装模型:
# DDP进行训练
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.local_rank])
如何启动DDP
那么如何启动DDP,这不同于DP的方式,需要使用torch.distributed.launch启动器,对于单机多卡的情况:
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 main.py
# nproc_per_node: 这个参数是指你使用这台服务器上面的几张显卡
有时候虽然说,可以简单使用DP,但是DDP的效率是比DP高的,所以很多时候单机多卡的情况,我们还是会去使用DDP
AI硬件加速设备
在进行模型部署和训练时,有时会受限于CPU和GPU的性能。这时,专用的AI芯片就显得尤为重要。正式开始本节内容之前,先了解一下什么是CPU和GPU。
CPU即Central Processing Unit,中文名为中央处理器,是电脑中的核心配件。它的功能主要是处理指令、执行操作、控制时间、处理数据。
在现代计算机体系结构中,CPU 对计算机的所有硬件资源(如存储器、输入输出单元) 进行控制调配、执行通用运算的核心硬件单元。CPU 是计算机的运算和控制核心。计算机系统中所有软件层的操作,最终都将通过指令集映射为CPU的操作。
GPU即Graphics Processing Unit,中文名为图形处理单元。在传统的冯·诺依曼结构中,CPU 每执行一条指令都需要从存储器中读取数据,根据指令对数据进行相应的操作。从这个特点可以看出,CPU 的主要职责并不只是数据运算,还需要执行存储读取、指令分析、分支跳转等命令。深度学习算法通常需要进行海量的数据处理,用 CPU 执行算法时,CPU 将花费大量的时间在数据/指令的读取分析上,而 CPU的频率、内存的带宽等条件又不可能无限制提高,因此限制了处理器的性能。而 GPU 的控制相对简单,大部分的晶体管可以组成各类专用电路、多条流水线,使得 GPU 的计算速度远高于CPU;同时 GPU 拥有了更加强大的浮点运算能力,可以缓解深度学习算法的训练难题,释放人工智能的潜能。
GPU没有独立工作的能力,必须由CPU进行控制调用才能工作,且GPU的功耗一般比较高。因此,随着人工智能的不断发展,高功耗低效率的GPU不再能满足AI训练的要求,为此,一大批功能相对单一,但速度更快的专用集成电路相继问世。接下来了解一下什么是专用集成电路:
专用集成电路(Application-Specific Integrated Circuit,ASIC)是专用定制芯片,即为实现特定要求而定制的芯片。定制的特性有助于提高 ASIC 的性能功耗比。ASIC的缺点是电路设计需要定制,相对开发周期长,功能难以扩展。但在功耗、可靠性、集成度等方面都有优势,尤其在要求高性能、低功耗的移动应用端体现明显。下文提到的谷歌的TPU,寒武纪的NPU都属于ASIC的范畴。
本节内容:
- 什么是TPU
- 什么是NPU
TPU
TPU即Tensor Processing Unit,中文名为张量处理器。2006年,谷歌开始计划为神经网络构建一个专用的集成电路(ASIC)。随着计算需求和数据量的不断上涨,这个需求在2013年开始变得尤为紧迫。于是,谷歌在2015年6月的IO开发者大会上推出了为优化自身的TensorFlow框架而设计打造的一款计算神经网络专用芯片。它主要用于进行搜索,图像,语音等模型和技术的处理。
截至目前,谷歌已经发行了四代TPU芯片。
芯片架构设计
TPU的设计架构如下图
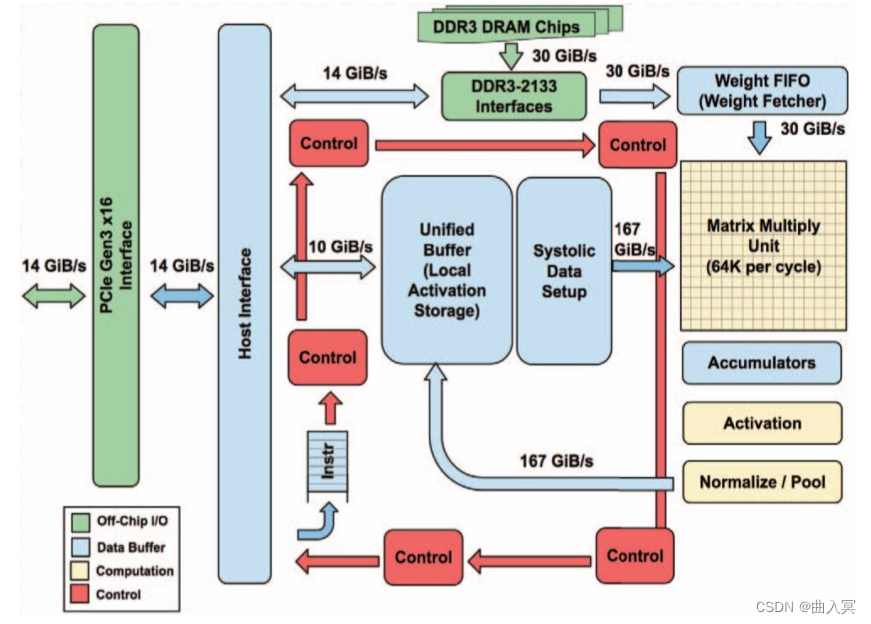
上图:In-datacenter performance analysis of a tensor processing unit,figure 1
由上图可见,整个TPU中最重要的计算单元是右上角黄色的矩阵乘单元“Matrix Multiply Unit”,它包含256x256个MAC部件,每一个能够执行有符号或者无符号的8位乘加操作。它的输入为权重数据队列FIFO和统一缓冲Unified Buffer,即图中指向它的两个蓝色部分。在计算结束后,16位结果被收集并传递到位于矩阵单元下方的4MiB 32位蓝色累加器Accumulators中,之后由黄色的激活单元在累加后执行非线性函数,并最终将数据返回给统一缓冲。
Matrix Multiply Unit矩阵处理器作为TPU的核心部分,它可以在单个时钟周期内处理数十万次矩阵(Matrix)运算。MMU有着与传统CPU、GPU截然不同的架构,称为脉动阵列(systolic array)。之所以叫“脉动”,是因为在这种结构中,数据一波一波地流过芯片,与心脏跳动供血的方式类似。而如下图所示,CPU和GPU在每次运算中都需要从多个寄存器(register)中进行存取,而TPU的脉动阵列将多个运算逻辑单元(ALU)串联在一起,复用从一个寄存器中读取的结果。每个ALU单元结构简单,一般只包含乘法器、加法器以及寄存器三部分,适合大量堆砌。
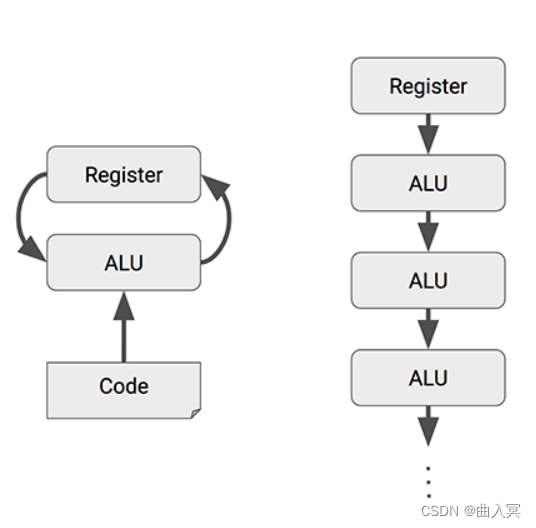
但是,在极大增加数据复用、降低内存带宽压力的同时,脉动阵列也有两个缺点,即数据重排和规模适配。第一,脉动矩阵主要实现向量/矩阵乘法。以CNN计算为例,CNN数据进入脉动阵列需要调整好形式,并且严格遵循时钟节拍和空间顺序输入。数据重排的额外操作增加了复杂性。第二,在数据流经整个阵列后,才能输出结果。当计算的向量中元素过少,脉动阵列规模过大时,不仅难以将阵列中的每个单元都利用起来,数据的导入和导出延时也随着尺寸扩大而增加,降低了计算效率。因此在确定脉动阵列的规模时,在考虑面积、能耗、峰值计算能力的同时,还要考虑典型应用下的效率。
技术特点
AI加速专用
TPU的架构属于Domain-specific Architecture,也就是特定领域架构。它的定位准确,架构简单,单线程控制,定制指令集使得它在深度学习运算方面效率极高,且容易扩展。相比之下,传统诸如CPU、GPU等通用处理器必须考虑灵活性和兼容性,有太重的包袱。但TPU这种特点也决定它只能被限制用于深度学习加速场景。
脉动阵列设计
TPU采用了与传统CPU和GPU截然不同的脉动阵列(systolic array)结构来加速AI运算,脉动阵列能够在一个时钟周期内处理数十万次矩阵运算,在每次运算过程中,TPU能够将多个运算逻辑单元(ALU)串联在一起,并复用从一个寄存器中取得的结果。这种设计,不仅能够将数据复用实现最大化,减少芯片在运算过程中的内存访问次数,提高AI计算效率,同时也降低了内存带宽压力,进而降低内存访问的能耗。
MMU的脉动阵列包含256 × 256 = 65,536个ALU,也就是说TPU每个周期可以处理65,536次8位整数的乘法和加法。
TPU以700兆赫兹的功率运行,也就是说,它每秒可以运行65,536 × 700,000,000 = 46 × 1012次乘法和加法运算,或每秒92万亿(92 × 1012)次矩阵单元中的运算。

上图:In-datacenter performance analysis of a tensor processing unit,figure 4
NPU
NPU即Neural-network Processing Unit,中文名为神经网络处理器,它采用“数据驱动并行计算”的架构,特别擅长处理视频、图像类的海量多媒体数据。
长期以来,应用需求一直牵动着嵌入式技术的发展方向。随着深度学习神经网络的兴起,人工智能、大数据时代的来临,CPU和GPU渐渐难以满足深度学习的需要,面对日渐旺盛的需求和广大的预期市场,设计一款专门用于神经网络深度学习的高效智能处理器显得十分必要,因此NPU应运而生。
从技术角度看,深度学习实际上是一类多层大规模人工神经网络。它模仿生物神经网络而构建,由若干人工神经元结点互联而成。神经元之间通过突触两两连接,突触记录了神经元间联系的权值强弱。由于深度学习的基本操作是神经元和突触的处理,神经网络中存储和处理是一体化的,都是通过突触权重来体现,而冯·诺伊曼结构中,存储和处理是分离的,分别由存储器和运算器来实现,二者之间存在巨大的差异。当用现有的基于冯·诺伊曼结构的经典计算机(如X86处理器和英伟达GPU)运行神经网络应用时,就不可避免地受到存储和处理分离式结构的制约,因而影响效率。因此,专门针对人工智能的专业芯片NPU更有研发的必要和需求。
在NPU的设计上,中国走在了世界前列。下面将以寒武纪的DianNao系列架构为例,来简要介绍NPU。
DianNao
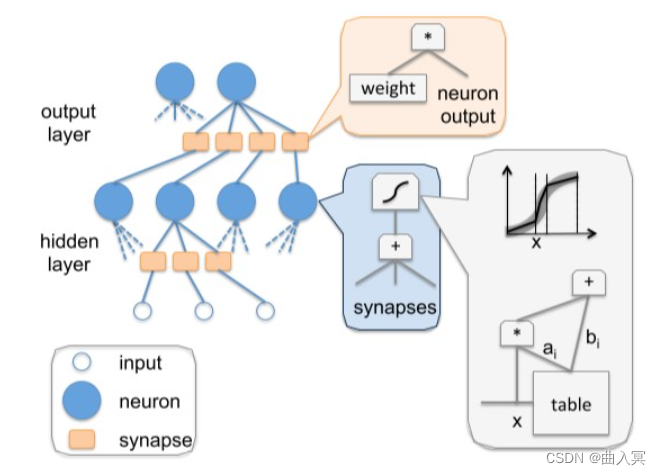
上图:DianNao: a small-footprint high-throughput accelerator for ubiquitous machine-learning,figure 9
基于神经网络的人工智能算法,是模拟人类大脑内部神经元的结构。上图中的neuron代表的就是单个神经元,synapse代表神经元的突触。这个模型的工作模式,就要结合高中生物课的知识了。
一个神经元,有许多突触,给别的神经元传递信息。同样,这个神经元,也会接收来自许多其他神经元的信息。这个神经元所有接受到的信息累加,会有一个强烈程度,在生物上是以化学成分的形式存在,当这些信息达到一定的强烈程度,就会使整个神经元处于兴奋状态(激活),否则就是不兴奋(不激活)。如果兴奋了,就给其他神经元传递信息,如果不兴奋,就不传递。这就是单独一个神经元的工作模式。那么有成千上万个这样的神经元组合起来,就是一个神经网络模型。
那么DianNao是如何模拟神经元进行工作的呢,可以看看它的内部结构图:
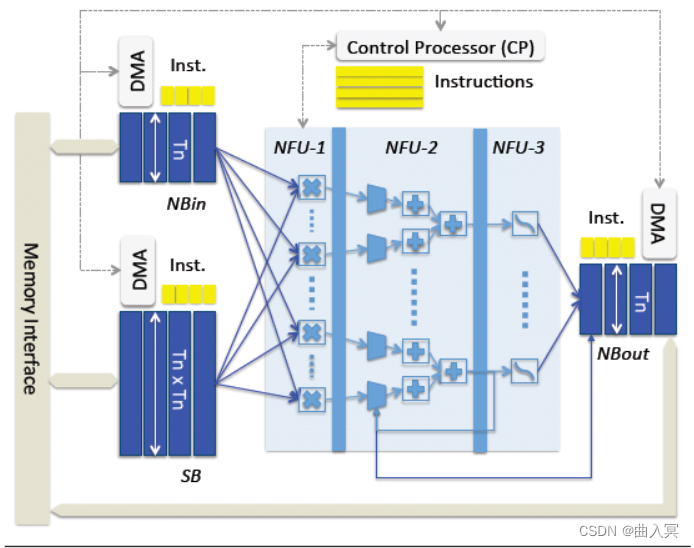
上图:DianNao: a small-footprint high-throughput accelerator for ubiquitous machine-learning,figure 11
如图所示,上图中浅蓝色的部分就是用硬件逻辑模拟的神经网络架构,称为NFU(Neural Functional Units)。它可以被细分为三个部分,即途中的NFU-1,NFU-2,和NFU-3。
NFU-1是乘法单元,它采用16bit定点数乘法器,1位符号位,5位整数位,10位小数位。该部分总计有256个乘法器。这些乘法器的计算是同时的,也就是说,在一个周期内可以执行256次乘法。
NFU-2是加法树,总计16个,每一个加法树都是8-4-2-1这样的组成结构,即就是每一个加法树中都有15个加法器。
NFU-3是非线性激活函数,该部分由分段线性近似实现非线性函数,根据前面两个单元计算得到的刺激量,从而判断是否需要激活操作。
当需要实现向量相乘和卷积运算时,使用NFU-1完成对应位置元素相乘,NFU-2完成相乘结果相加,最后由NFU-3完成激活函数映射。完成池化运算时,使用NFU-2完成多个元素取最大值或取平均值运算。由此分析,尽管该运算模块非常简单,也覆盖了神经网络所需要的大部分运算。
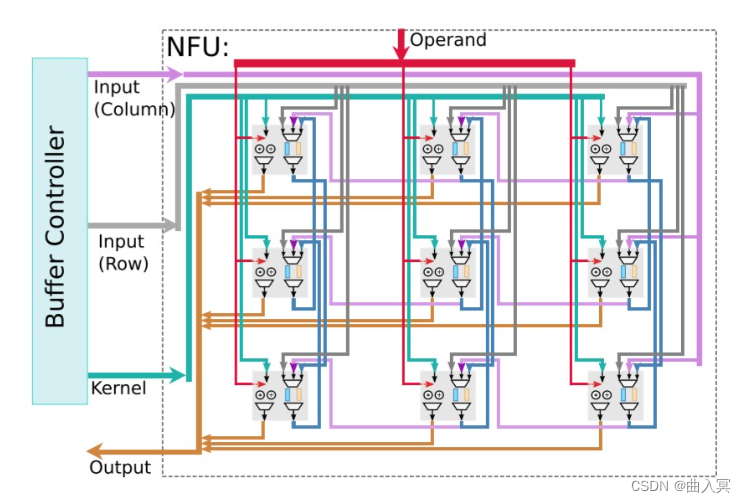
DaDianNao
作为DianNao的多核升级版本,DaDianNao的运算单元NFU与DianNao基本相同,最大的区别是为了完成训练任务多加了几条数据通路,且配置更加灵活。NFU的尺寸为16x16,即16个输出神经元,每个输出神经元有16个输入(输入端需要一次提供256个数据)。同时,NFU可以可选的跳过一些步骤以达到灵活可配置的功能。DaDianNao的NFU结构如下所示:
上图:DaDianNao: A Machine-Learning Supercomputer,figure 6
ShiDianNao
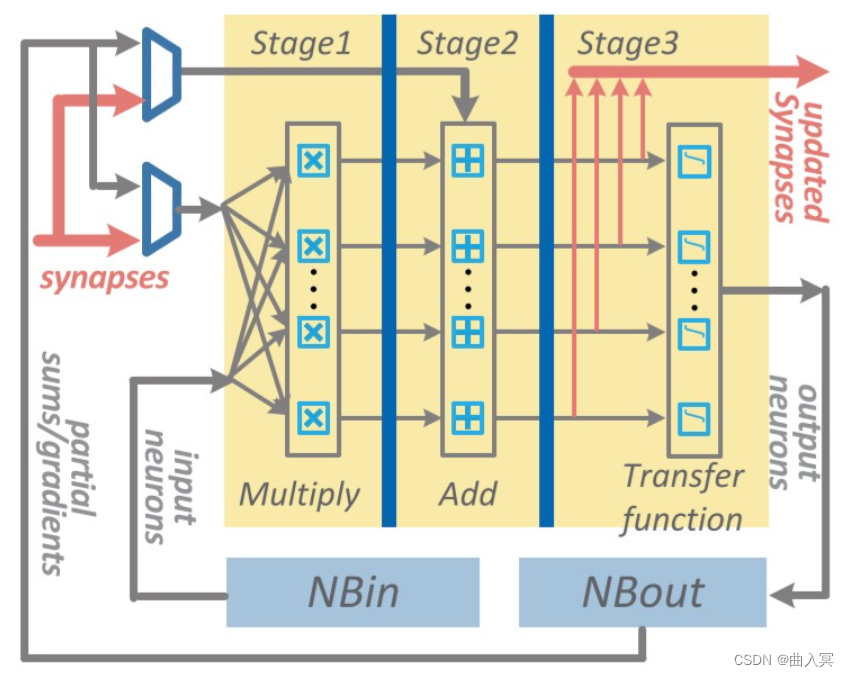
ShiDianNao是机器视觉专用加速器,集成了视频处理的部分,它也是DianNao系列中唯一一个考虑运算单元级数据重用的加速器,也是唯一使用二维运算阵列的加速器,其加速器的运算阵列结构如下所示:
上图:ShiDianNao: Shifting vision processing closer to the sensor,figure 5
ShiDianNao的运算阵列为2D格点结构,对于每一个运算单元(节点)而言,运算所使用的参数统一来源于Kernel,而参与运算的数据则可能来自于:数据缓存NBin,下方的节点,右侧的节点。
下图为每个运算单元的结构:
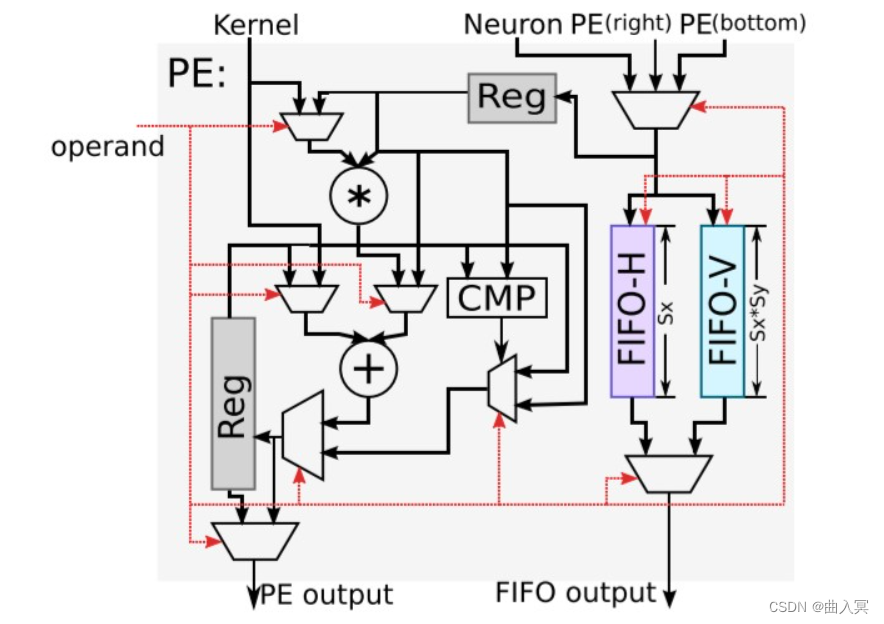
上图:ShiDianNao: Shifting vision processing closer to the sensor,figure 6
该计算节点的功能包括转发数据和进行计算:
转发数据:每个数据可来源于右侧节点,下方节点和NBin,根据控制信号选择其中一个存储到输入寄存器中,且根据控制信号可选的将其存储到FIFO-H和FIFO-V中。同时根据控制信号选择FIFO-H和FIFO-V中的信号从FIFO output端口输出
进行计算:根据控制信号进行计算,包括相加,累加,乘加和比较等,并将结果存储到输出寄存器中,并根据控制信号选择寄存器或计算结果输出到PE output端口。
对于计算功能,根据上文的结构图,可以发现,PE支持的运算有:kernel和输入数据相乘并与输出寄存器数据相加(乘加),输入数据与输出寄存器数据取最大或最小(应用于池化),kernel与输入数据相加(向量加法),输入数据与输出寄存器数据相加(累加)等。
PuDianNao
作为DianNao系列的收山之作,PuDianNao的运算单元是电脑系列中唯一一个异构的,除了有MLU(机器学习单元)外,还有一个ALU用于处理通用运算和MLU无法处理的运算,其运算单元(上)和MLU(下)结构如下图所示:
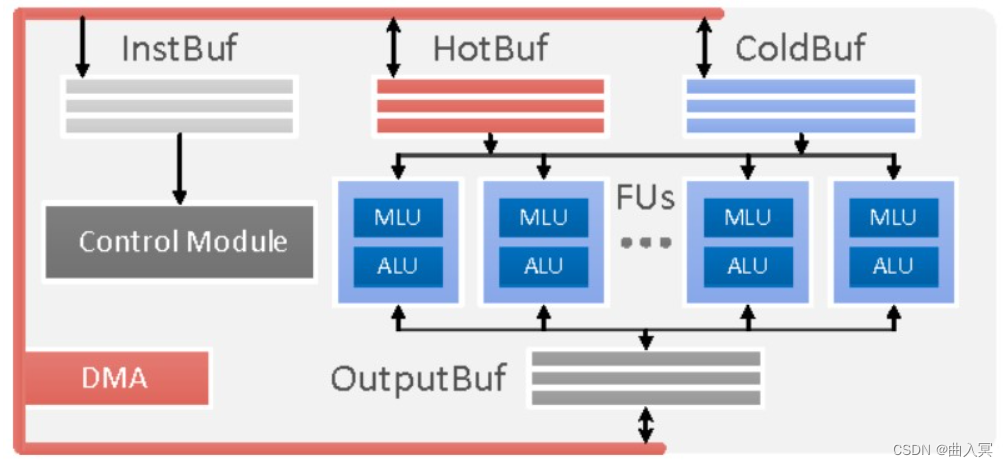
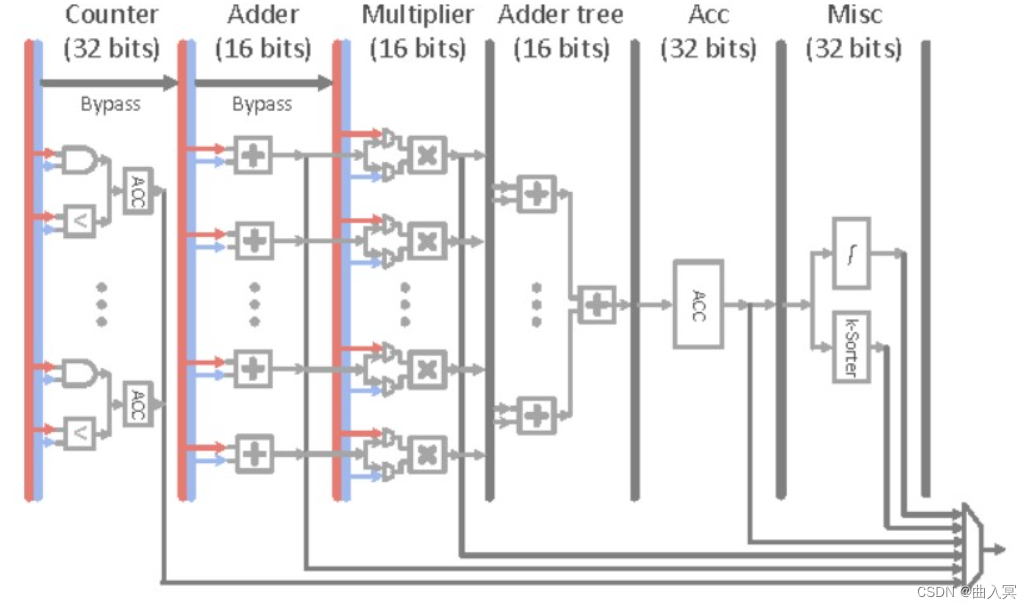
上图:PuDianNao: A Polyvalent Machine Learning Accelerator,figure 11&12
该MLU共分为6层:
计数层/比较层:这一层的处理为两个数按位与或比较大小,结果将被累加,这一层可以单独输出且可以被bypass
加法层:这一层为两个输入对应相加,这一层可以单独输出且可以被bypass
乘法层:这一层为两个输入或上一层(加法层)结果对应位置相乘,可以单独输出
加法树层:将乘法层的结果累加
累加层:将上一层(加法树层)的结果累加,可以单独输出
特殊处理层:由一个分段线性逼近实现的非线性函数和k排序器(输出上一层输出中最小的输出)组成
该运算单元是DianNao系列中功能最多的单元,配置非常灵活。例如实现向量相乘(对应位置相乘后累加)时,弃用计数层,加法层,将数据从乘法层,加法树层和累加层流过即可实现。
PuDianNao支持7种机器学习算法:神经网络,线性模型,支持向量机,决策树,朴素贝叶斯,K临近和K类聚,所需要支持的运算较多,因此PuDianNao的运算分析主要集中在存储方面,其运算核心的设计中说明PuDianNao支持的运算主要有:向量点乘,距离计算,计数,排序和非线性函数。其他未覆盖的计算使用ALU实现。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!