我的隐私计算学习——联邦学习(1)
笔记内容来自多本书籍、学术资料、白皮书及ChatGPT等工具,经由自己阅读后整理而成。
六、联邦学习
笔记分享 | 组队学习密码学 —— 密码学在联邦学习中的应用
? 根据前文已经知道,隐私计算与联邦学习的结合是当前的一个热点,联邦学习原本是机器学习领域里的一个概念,但常常把它当作单独一个板块。想要深入学习隐私计算,务必先学会如何应用联邦学习。联邦学习,可以理解为大数据、分布式计算、网络空间信息安全与机器学习的一个交叉领域,其目的是采用分布式机器学习的模型训练方式,通过隐私计算的方法来确保训练过程中大数据的隐私性。
(一)联邦学习的分类
根据各方数据集的贡献方式不同,可以将联邦学习具体分为:
-
横向联邦学习
适用于各数据持有方的业务类型相似、所获得的用户特征多而用户空间只有较少重叠或基本无重叠的场景。例如,各地区不同的商场拥有客户的购物信息大多类似,但是用户人群不同。横向联邦学习以数据的特征维度为导向,取出参与方特征相同而用户不完全相同的部分进行联合训练。在此过程中,通过各参与方之间的样本联合,扩大了训练的样本空间,从而提升了模型的准确度和泛化能力。

-
纵向联邦学习
适用于各参与方之间用户空间重叠较多,而特征空间重叠较少或没有重叠的场景。例如,某区域内的银行和商场,由于地理位置类似,用户空间交叉较多。在联合训练时,需要先对各参与方数据进行样本对齐,获得用户重叠的数据,然后各自在被选出的数据集上进行训练。此外,为了保证非交叉部分数据的安全性,在系统级进行样本对齐操作,每个参与方只有基于本地数据训练的模型。

-
联邦迁移学习
适用于各参与方用户空间和特征空间都重叠较少的场景。例如,不同地区的银行和商场之间,用户空间交叉较少,并且特征空间基本无重叠。在该场景下,采用横向联邦学习可能会产生比单独训练更差的模型,采用纵向联邦学习可能会产生负迁移的情况。联邦迁移学习基于各参与方数据或模型之间的相似性,将在源域中学习的模型迁移到目标域中。大多采用源域中的标签来预测目标域中的标签准确性。
(二)与隐私计算结合的前景
? 为什么需要隐私计算?因为传统的机器学习系统在应对攻击时,常常因为其健壮性不足容易出现各种各样的问题。而通过联邦学习的分布性和隐私计算技术的融合,联邦学习在应对一些传统攻击方式时可以更好地保护数据。以下是一些典型的攻击方式:(模型更新中毒攻击和逃避攻击都属于“对抗性攻击”,其主要方式为对模型的训练及推理过程进行一些更改,从而降低模型性能。)
| 模型更新中毒攻击 | 数据中毒攻击 | 逃避攻击 |
|---|---|---|
| 模型训练与部署中 | 数据预处理过程中 | 修改恶意样本的特征值 |
? 在抵御模型更新中毒攻击方面,中央服务器可以通过对客户端模型更新进行约束;约束任何本地客户端对整个模型的更新,然后汇总本地的模型更新集合并将高斯噪声添加到集合中。Geyer 等人对联邦学习中的差分隐私进行了研究,并提出一种保护客户端差分隐私的联邦优化算法,在隐私损失和模型性能之间取得平衡。
? 联邦学习目前与隐私计算紧密结合,先来说说联邦学习的计算环境,在没有 TEE 的时候,通常采用无可信第三方情况下的安全多方计算(Secure Multi-party Computing,MPC)方案。MPC 是一套纯软件解决方案,主要通过加密算法保障数据安全。MPC 的实现大致可归为两类:一类是基于噪声的,另一类是不基于噪声的。两大计算环境如下:
(1)基于噪声的安全计算方法
? 这类方法的主要代表是差分隐私(Differential Privacy),其主要思想是用噪声对计算过程进行干扰,其核心目的是隐藏模型参数等数据信息,进而使参与者无法根据得到的结果反推出原始数据。基于噪声的安全计算方法,由于可以只生成服从特定分布的随机数,因此计算效率较高。不过,这也会导致最后的输出结果不够准确,特别是对于复杂的计算任务,其结果会与无噪声的结果相差很大而无法使用。
(2)非噪声的安全计算方法
? 这一类方法主要包括茫然传输、混淆电路、同态加密和密钥分享。这些方法一般在源头上就对数据进行加密或编码,计算的操作方看到的都是密文,因此只要满足特定的假设条件,这类方法在计算过程中是不会泄露信息的。相比于基于噪声的方法,非噪声的安全计算方法的优点是不对计算过程加干扰,因此我们最终得到的是准确值,且有密码学理论加持,安全性有保障;缺点则是由于使用了很多密码学方法,整个过程中无论是计算量还是通信量都非常庞大,对于一些复杂的任务,短时间内可能无法完成。
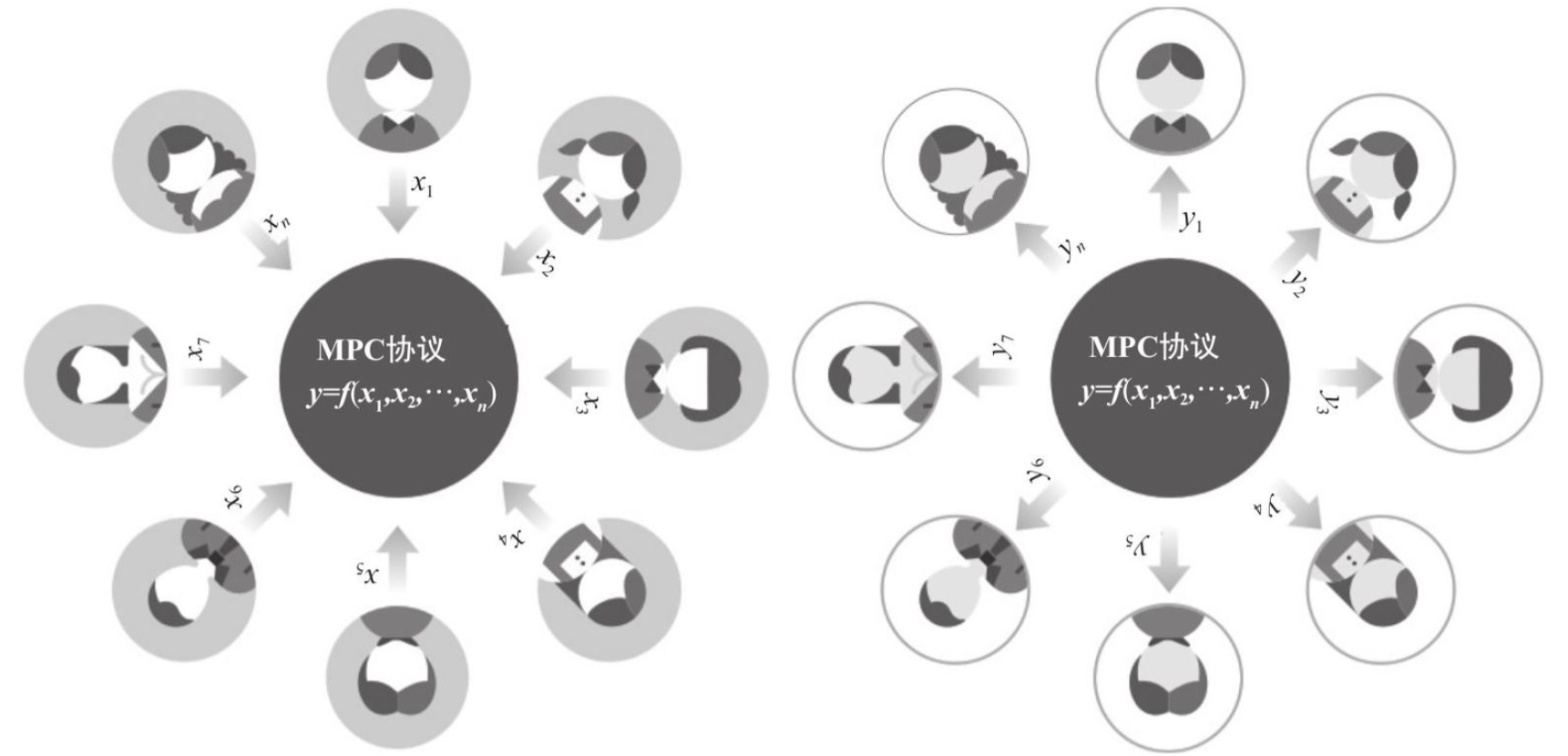
? 联邦学习强调将数据一开始就保存在参与方本地,并且在训练过程中加入隐私保护技术,拥有更好的隐私保护特性。各参与方的数据一直保存在本地,在建模过程中,各方的数据库依然独立存在,而联合训练时进行的参数交互也是经过加密的,各方通信时采用严格的加密算法,难以泄露原始数据的相关信息。此外,联邦学习技术可使分布式训练获得的模型效果与传统中心式训练效果相差无几,训练出的全局模型几乎是无损的,各参与方能够共同获益。
? 联邦学习可用于在海量数据集下的模型训练,实现部门、企业及组织之间的联动。例如,在智慧金融领域中,可以根据多方数据建立更准确的业务模型,从而实现合理定价、定向业务推广、企业风控评定等;在智慧城市中,实现各政府机构之间、企业与政府之间的联合,实现更准确的实时交通预测,更简化的机关办事步骤,更高效的信息内容查询,更全面的安全防控检测等;在智慧医疗中,联邦学习可以综合各医院之间的数据,提高医疗影像诊断的准确性,预警病人的身体情况等。当然,未来它将覆盖更广阔的应用场景。
10月份新开了一个GitHub账号,里面已放了一些密码学,隐私计算电子书资料了,之后会整理一些我做过的、或是我觉得不错的论文复现、代码项目也放上去,欢迎一起交流!Ataraxia-github
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!