SimCLR损失函数详解
图片来源:Self-Supervised Learning 超详细解读 (二):SimCLR系列
1. 数据增强
有一批batchsize为N的样本,论文中N=8192,下图以N=2为例;
对一个batch中的每个样本都进行2次随机的数据增强(随机裁剪之后再resize成原来的大小、随机色彩失真、随机高斯模糊3种方式)
对每张图片 x i x_i xi?得到2个不同的数据增强结果( x i 1 和 x i 2 x_i^1和x_i^2 xi1?和xi2?),所以1个Batch 一共有 N*2 个增强样本图片。
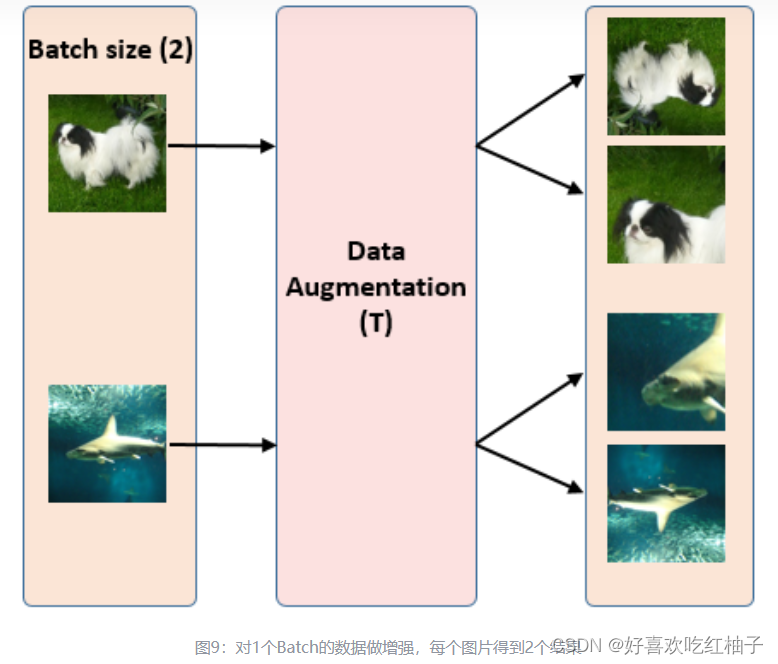
2. 获得图片表征
经过resnet网络提取特征+预测头,提取到了最终的visual representation。

3. 正样本和负样本构建
对于一个batch中,由同一张图片数据增强过的两张图片(
x
i
1
和
x
i
2
x_i^1和x_i^2
xi1?和xi2?)组成一个positive pair,他们互为正样本;
其余任意两两图片之间的组合组成的图片对即为负样本。即N组pair中有一对positive和N-1对negative样本。

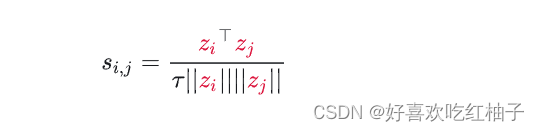
4. 计算相似度
使用余弦相似度衡量两两向量之间的相似度,公式如下所示:
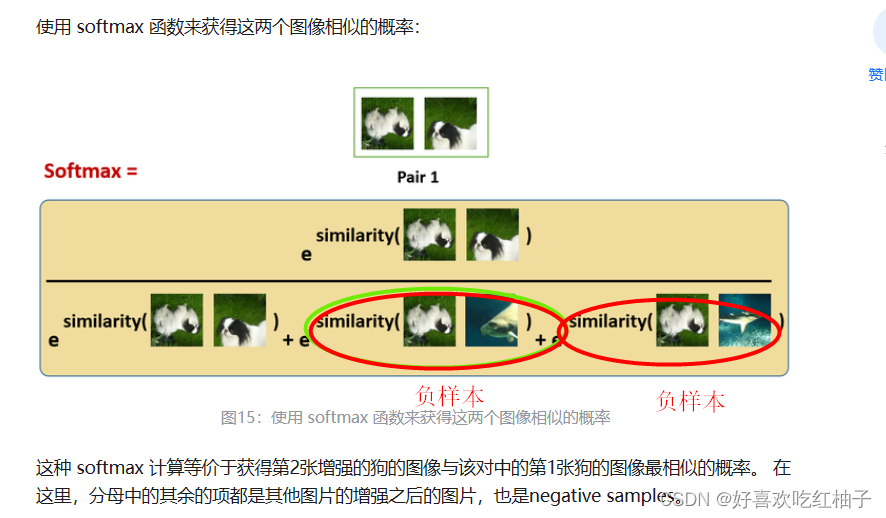
5. 计算图片之间相似的概率
使用softmax计算概率:
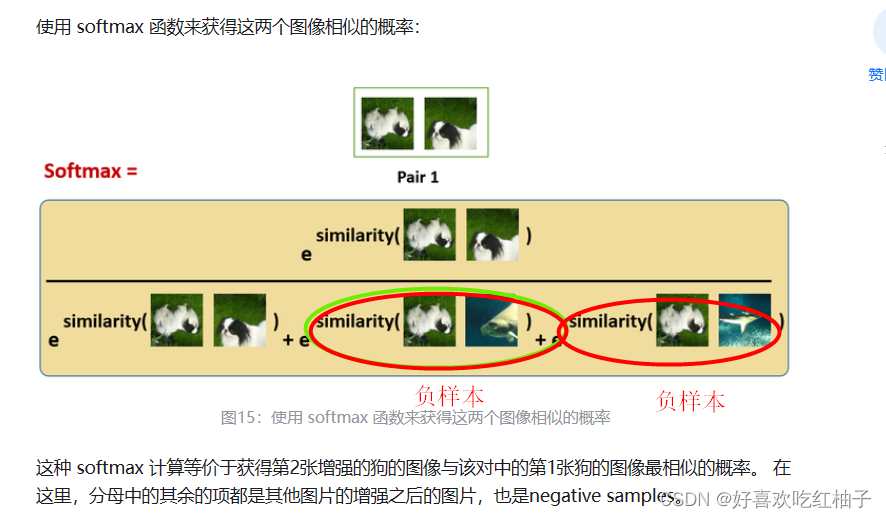
该计算表达的是 x i 1 x_i^1 xi1?与 x i 2 x_i^2 xi2?最相似的概率,即第一张图片作为参考,计算另外三张图片,哪个最像
分子为 x i 1 x_i^1 xi1?与 x i 2 x_i^2 xi2?的相似性取对数,分母为 x i 1 x_i^1 xi1?与一个batch中另外 2 N ? 1 2N-1 2N?1张图片的相似性求对数的和。故分子为1对的相似性,分母为2N-1对图片的相似性的和
6. 损失函数
我们希望上面的softmax的结果尽量大(同一张图片增强出来的两张图片互为正样本,相似度越大越好),所以损失函数取了softmax的负对数:

接下来再计算是
x
i
2
x_i^2
xi2?与
x
i
1
x_i^1
xi1?最相似的概率然后取-log, 即对第一对的计算交换顺序再计算一遍;

最后,计算每个Batch里面的所有Pair(共有N个图片对,2N个交换顺序之后的pair) 的损失之和取平均:

为什么需要大规模的batchsize?
更大的训练批量和训练轮数,可以提供更多的负样本,促进模型收敛。
可以增加负样本的数量,在计算概率的时候,计算公式的分母中就包含了负样本的计算
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!