kubernetes 集群 oom 导致集群无法访问
2023-12-29 13:54:50

现象
执行kubectl get node 无法获取集群状态。日志截图:

查看 message日志,发现报错存在OOM,并与应用测试的容器相关,截图如下:
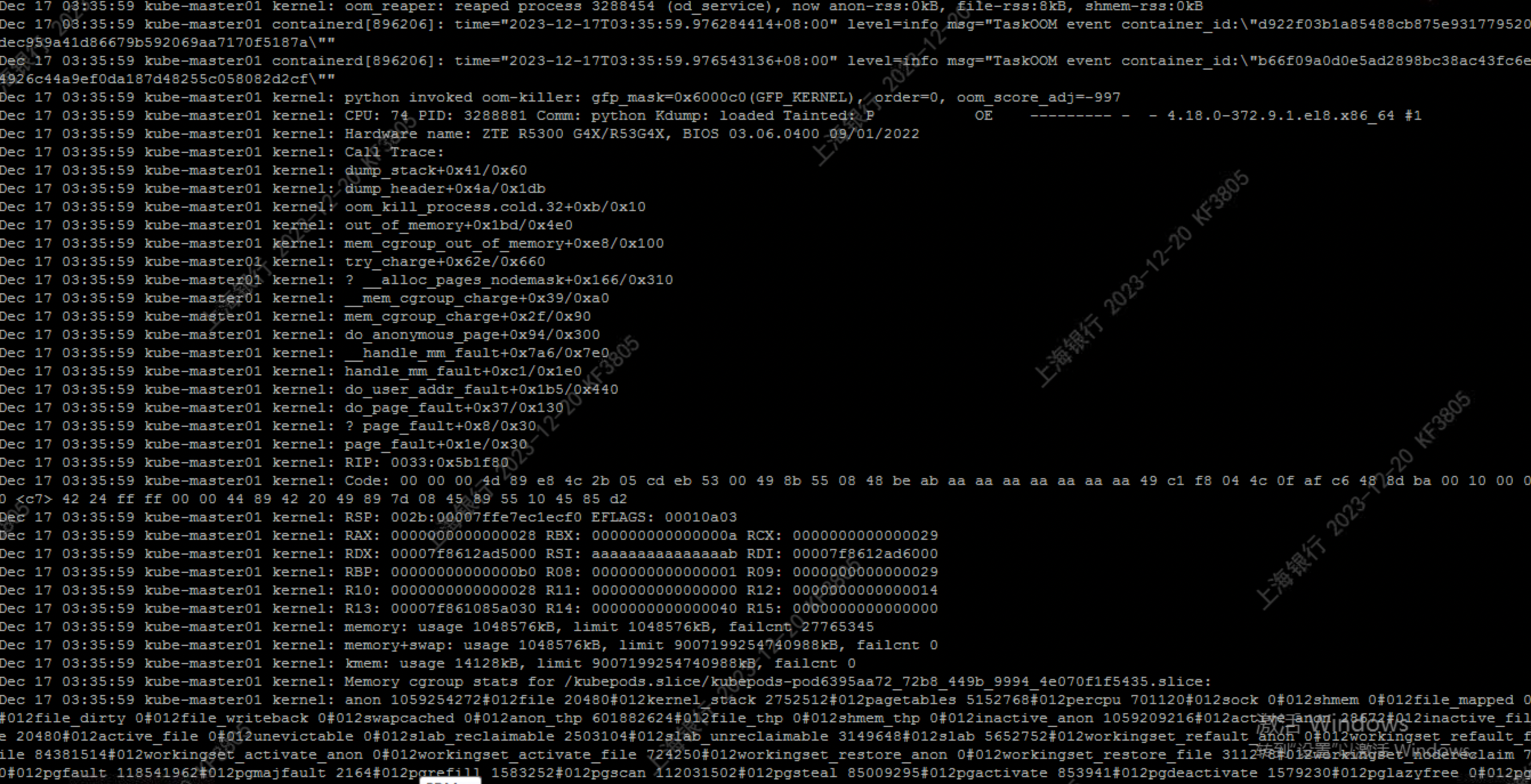
分析
首先,定位最初的oom发生的时间点,是2023年12月15日,如图
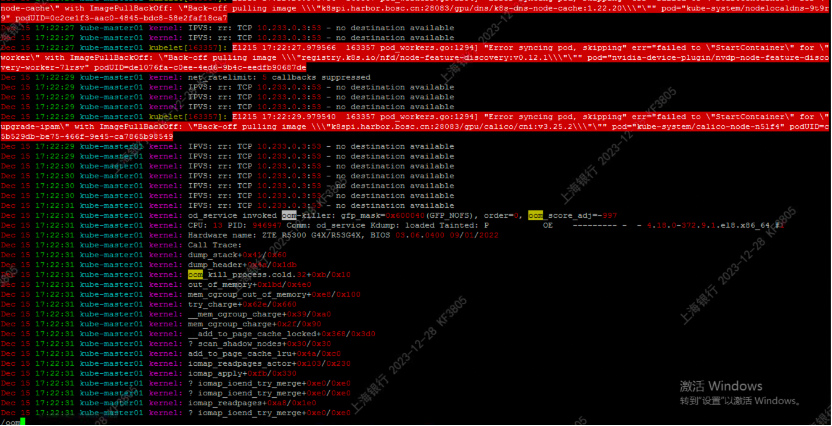
按照正常逻辑来讲,应用实例做了 limit 限制,如果应用超出内存限制,应该被杀掉并且进行重新调度。
进一步发现,集群的 kube-apiserver 在2023年12月17日是挂掉了。当kube-apiserver挂掉时,Kubernetes的调度器和控制器无法与API服务器通信,这并不会导致Pod使用内存超出限制而被终止。
kubelet会采取以下行动之一:
l OOM(Out of Memory)Killing:如果容器无法分配更多的内存,并且超出了限制,kubelet可能会触发OOM Killer,终止该容器。这是Linux内核中的一项功能,用于防止系统内存耗尽。
l 重启容器:kubelet也可以选择重启超出内存限制的容器,以尝试解决内存问题。重启容器可以释放内存并清除可能导致内存泄漏或过度消耗的状态。
Kube-apiserver 挂掉的原因在日志中也明显可以看到是由于镜像没有正常拉取。
跟踪到最初镜像没有正常被拉取的时间。
综合分析,由于containerd 更改了存储目录和镜像仓库访问认证,镜像仓库的访问认证错误修改,导致集群无法正常拉取镜像。Kube-apiserver启动异常。导致当应用实例占用内存超出限制时,并没有被杀掉,kubelet触发OOM Killer。
参考:
文章来源:https://blog.csdn.net/xixihahalelehehe/article/details/135287013
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!