【LeetCode】修炼之路-0001-Two Sum(两数之和)【python】【简单】
前言
?计算机科学作为一门实践性极强的学科,代码能力的培养尤为重要。当前网络上有非常多优秀的前辈分享了LeetCode的最佳算法题解,这对于我们这些初学者来说提供了莫大的帮助,但对于我这种缺乏编程直觉的学习者而言,这往往难以消化吸收。(为什么别人就能想出这么优雅,高级的实现!我就只会暴力呢)我浅薄地认为,只有理解算法设计的思路,才能真正掌握编程技巧。鉴于此,本系列试图呈现另一种LeetCode修炼之路——从基本原理出发,一步步拓展思路,逐级深化难度。我将带您逐步经历算法设计的整个思考过程,不仅呈现最终成果,更重要的是共同经历这场求知的长征!
?笔者才疏学浅,难免疏漏错误。衷心希望聪明的您可以批评指正,大胆留下您的评论,让我们不断完善这套题解体系。
题目
Given an array of integers numsand an integer target, return indices of the two numbers such that they add up to target.
You may assume that each input would have exactly one solution, and you may not use the same element twice.
You can return the answer in any order.
Example 1:
Input: nums = [2,7,11,15], target = 9
Output: [0,1]
Explanation: Because nums[0] + nums[1] == 9, we return [0, 1].
Example 2:
Input: nums = [3,2,4], target = 6
Output: [1,2]
Example 3:
Input: nums = [3,3], target = 6
Output: [0,1]
题目译文
给定一个整数数组nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。
你可以假设每种输入只会对应一个答案。但是,数组中同一个元素在答案里不能重复出现。
你可以按任意顺序返回答案。
知识点
Python 中的 range() 函数用于生成一系列数字。它通常用于 for 循环中,以便遍历一系列数字。这个函数可以接受一个、两个或三个参数:
Start(开始):序列的起始值。这个参数是可选的,如果不填,默认从 0 开始。
Stop(结束):序列的结束值。range 生成的序列会一直到这个数,但不包括这个数。这个参数是必须的。
Step(步长):序列中每个数字之间的差值。这个参数是可选的,如果不填,默认步长为 1。
下面是一些使用 range() 的例子:
range(5) 生成从 0 到 4 的序列(即 [0, 1, 2, 3, 4])。
range(1, 5) 生成从 1 到 4 的序列(即 [1, 2, 3, 4])。
range(0, 10, 2) 生成从 0 到 8 的偶数序列(即 [0, 2, 4, 6, 8])。
range() 函数生成数字是惰性的,这意味着它按需一次生成一个数字,而不是一次性生成所有数字。这在处理大范围时非常有益,因为它有助于节省内存。
嵌套循环常用于处理多维数据,如二维表格、多维数组等。外层循环控制行,内层循环控制列。还可以用于全排列、组合等场景。
嵌套循环可以多层嵌套,实现多重控制。需要注意循环变量不要重名,内层循环会影响外层循环变量。
在示例代码中 程序先执行外层循环,将外层变量i从0迭代到9。在每轮外层循环中,内层循环会重新从0开始执行,将内层变量j迭代到9。内层循环完整地执行完毕后,外层循环才会进行下一轮迭代。
for i in range(10): # 外层循环
for j in range(10): # 内层循环
print(f"{i}{j}") #语句体
?哈希表可以快速实现判断一个元素是否出现在数组中。 通过直接访问存储位置、避免顺序比较、分布均匀等特性,哈希表实现了 O(1) 的优秀查找时间复杂度。遍历数组时,需要快速查找目标值减去当前元素的值是否存在,哈希表的查找时间复杂度为O(1),可以快速判断。
?哈希表是一种基础的数据结构,你能想到的编程语言基本都原生支持哈希表:
?Python:字典(dict)类型就是基于哈希表实现的。
?Java: HashMap和HashSet等基于哈希的集合都是原生支持的。
?C++:STL库提供了unordered_map和unordered_set作为哈希表的实现。
?C#: Dictionary 和 HashSet 类型原生支持哈希表。
?JavaScript:对象可以看作哈希表,ES6新增了Map数据结构。
?Go: Go语言通过map和set内置地支持了哈希表。
?Ruby:Hash类提供了字典实现,基于哈希表。
?Swift:字典(Dictionary)类型基于哈希表。
?PHP:关联数组(associative array)依赖哈希表实现。
?Rust: std::collections提供了HashMap和HashSet结构。
?Scala:原生支持HashMap和HashSet类。
思路分析(入门)
初出茅庐
首先我们要计算两个数的和是否等于target,那么我们肯定需要两个变量。var1,var2。
大家肯定不难想到最直接的实现,令var1=target[i],即target里的第i个元素。var2从下一个元素开始,通过全排列组合出所有可能,然后最后测试是否满足target。
class Solution:
def twoSum(self, nums: List[int], target: int) -> List[int]:
for i in range(len(nums)):
for j in range(i+1, len(nums)):
if nums[i] + nums[j] == target:
return [i, j]

??这种方法被称"暴力破解“(Brute Force),这是一种通过尝试所有可能性来获取问题解决方案的方法,它一定能通过,但是成本极高,通过暴力实现的算法,可以认为没有进行程序设计。让我们看看我们的算法有什么问题,我们如何来改进。
我们现在的实现是,通过全排列列出了所有的可能,并一个一个尝试,直到通过。
??想象一下,我们的实现就好比是,我们在一场冒险里,就是这个沉默的巨像接收你给他的两个下标,他再来判断是否通过这场考验。我们像无头苍蝇一样,一直尝试,直到通过。"暴力破解"一般遗漏了题目里隐含的信息,所以导致我们的算法实现是低效的。

(powered by DALL-E-3)
筑基初期
回头看一下题目,我们是知道两数和的,也就是说我拿到第一个数后,其实我就知道我要找的第二个数是什么了,因为使等式target成立的另一个解即var2=target-var1,那么现在我们要做的,就是如何快速如何快速判断var2是否出现在数组中,啊哈!没错!使用哈希表,
python里基于hash的实现有
set()和dict{},set更多的能判断某个值是否存在这个集合,而dict可以实现key-value两个值都可以获取,这里我们要解决的问题是返回的是下标,而不是整数数组nums是否存在target解的结论。因此我们的数据结构要使用dict,key用来存储数组里的值,value用来存储下标。如果题目要求为只返回是否存在解,我们会考虑使用set()。
那么我们需要执行这个操作,先构建这个hashmap,这样我们就能随心所欲的查询var2了!让我们来构建如下。
# 定义twoSum函数,输入为数组nums和目标值target,这是leetcode系统为你写好的
class Solution:
def twoSum(self, nums: List[int], target: int) -> List[int]:
# 创建空字典,用于存储数组元素值到索引的映射
hashmap = {}
# 遍历数组,将每个元素值与索引存入字典
for i in range(len(nums)):
hashmap[nums[i]] = i
然后我们有了 一个强大的哈希表,它存储了所有元素还有下标,我们遍历它岂不是更好,我们先通过对数组进行“编码”(这里抽象为对信息或者特征的提取)得到了哈希表,然后基于这个哈希表完成我们的任务。太好了,感觉思维也很干净(隐隐闪过一丝不安),我们实现代码如下:
先用你聪明的脑袋想想,这样的实现有没有逻辑问题,思考一下!
# 定义twoSum函数,输入为数组nums和目标值target
class Solution:
def twoSum(self, nums: List[int], target: int) -> List[int]:
# 创建空字典,用于存储数组元素值到索引的映射
hashmap = {}
# 遍历数组,将每个元素值与索引存入字典
for i in range(len(nums)):
hashmap[nums[i]] = i
# 遍历字典
for key in hashmap:
# 计算当前键对应元素的补数
var2 = target - key
# 如果var2存在于字典中,且不是key本身
if var2 in hashmap and hashmap[var2] != hashmap[key]: # 题目要求不能使用同一元素两次,所有有这个and的限制条件
# 返回当前键值对应的索引,和var2对应的索引
return [hashmap[key], hashmap[var2]]
折戟沉沙
提交!嗯?错误答案,分析分析
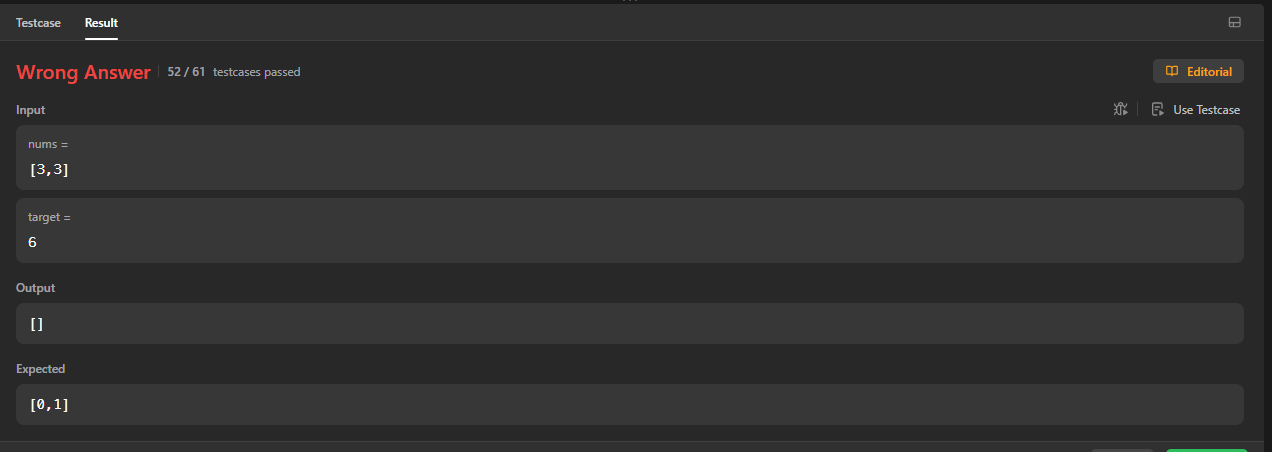
对于[3,3]测试用例,我们返回的是空,找不到,因为我们第二次遍历的是哈希表,而不是原始数组,通过“编码”得到的信息回导致失真,它的数据密度更高,但是会丢掉一些信息,自己要注意进行数据处理时,会导致的相关影响,例如我们在把数组转换成哈希表的时候,实际上会进行去重,[3,3]的数组转换成哈希表后,只留下了{3:1}这个结果,第二个3的下标会覆盖第一个,所以我们进行哈希表查询就返回为空了。
风云再起
好的,让我们再接再厉,这次我们遍历我们的数组,然后去哈希表里去找答案试试
class Solution:
def twoSum(self, nums: List[int], target: int) -> List[int]:
# 创建空字典,用于存储数组元素值到索引的映射
hashmap = {}
# 遍历数组,将每个元素值与索引存入字典
for i in range(len(nums)):
hashmap[nums[i]] = i
# 遍历数组
for i in range(len(nums)):
# 计算当前键对应元素的var2
var2= target - nums[i]
# 如果var2存在于字典中,且不是key本身
if var2 in hashmap and hashmap[var2] != i:
# 返回当前键值对应的索引,和var2对应的索引
return [i, hashmap[var2]]
提交!nice,总算是accepted了
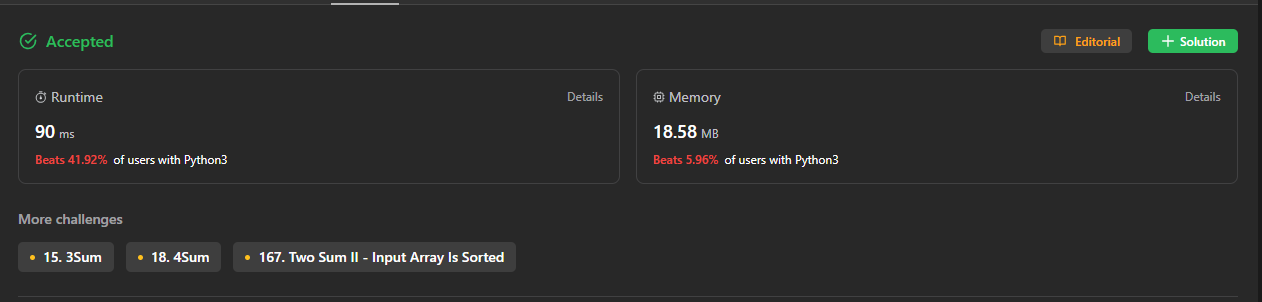
雄霸天下
看我们提交的结果,只击败了41.92%,啧啧啧,这可不行,再看看我们的代码有没有优化的地方,


可恶!同样的代码,我们竟然写了两次,今天我们学习一个咒语(加州口音让你更强大):Don’t Repeat Yourself!
DRY (Don’t Repeat Yourself) 原则:
原则的核心思想包括:
- 避免代码重复 - 对于相同或类似的代码,抽象成函数、模块等进行重用
- 将变化点抽象成参数、配置等,使代码更灵活
- 优先使用组合而非继承来重用代码
- 对所有重复实现进行提取、抽象、封装
- 重复的代码往往表示设计需要优化
想象一下在我们这里抽象成函数的话,只是换汤不换药,还是走了两次遍历,我们这里需要的是优化,比如我们看一下两次循环做的事情,第一次遍历数组建立hash表,第二次遍历数组找哈希表,我们能不能把这两次业务操作合并在一次循环里呢,流程改成遍历数组,拿到var1,计算var2的值,查找var2,如果存在则返回下标,如果不存在则添加到字典里,完美!让我们来试试这个全球最强代码,完美,优雅,除了变量命名和没有使用enumerate(),其他都是满分!
class Solution:
def twoSum(self, nums: List[int], target: int) -> List[int]:
# 创建空字典,用于存储数组元素值到索引的映射
hashmap = {}
# 遍历数组,将每个元素值与索引存入字典
for i in range(len(nums)):
# 计算当前键对应元素的var2
var2= target - nums[i]
# 如果var2存在于字典中,且不是key本身
if var2 in hashmap and hashmap[var2] != i:
# 返回当前键值对应的索引,和var2对应的索引
return [i, hashmap[var2]]
hashmap[nums[i]] = i
试试!


**41.66%???!**这咋还往下掉了呢,我倒要看看,是谁的代码超过了我们。
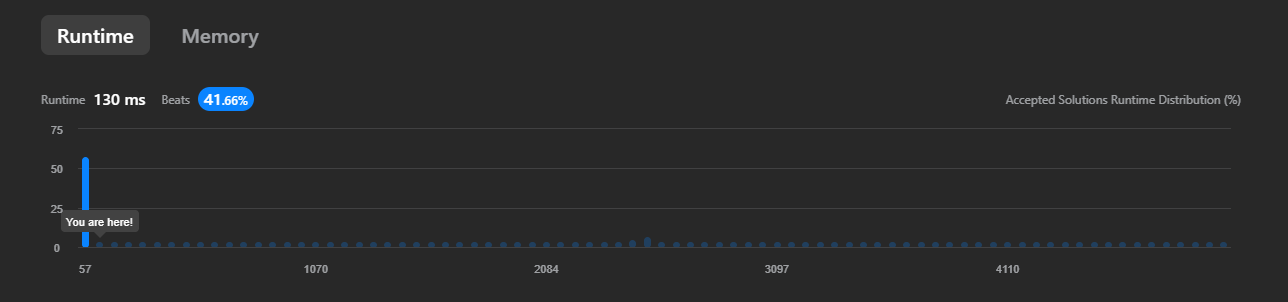
可以看到我们排名第二,什么!竟然还有比我们更强的存在,让老夫看看。
啊?竟然通过创建一个文件输出流f,指向user.out文件,然后使用print语句输出所有结果答案到该文件中,然后头也不回地调用exit(0)退出程序,这样当代码被运行测试的时候,它会直接把事先准备好的答案打印到输出文件中,从而通过测试。宛如学霸上场考数学B卷,直接写满B卷答案的同时,还把A卷和C卷的答案也写上了,裁判直呼卧槽!满分,必须满分!但是同学们,咱们不要学他噢,思维还是按我们的来,咱们的实现才是全球地表最强!这葵花宝典,不练也罢。【这段准确性有误,关于这个hack实现是如何通过验证的,还请网友批评指正】
# 逆练心法的最优解,因为leetcode会增加测试用例,所以现在leetcode里提供的这个性能最佳的代码已经无法通过测试了。
class Solution:
def twoSum(self, nums: List[int], target: int) -> List[int]:
f = open('user.out', 'w')
print('''[1, 0]
[2, 1]
[1, 0]
[2, 0]
[2, 1]
[3, 0]
[2, 0]
[4, 2]
[2, 1]
[1, 0]
[3, 2]
[2, 1]
[2, 0]
[4, 0]
[1, 0]
[3, 2]
[4, 2]
[5, 2]
[3, 0]
[4, 3]
[1, 0]
[1, 0]
[1, 0]
[1, 0]
[1, 0]
[1, 0]
[1, 0]
[1, 0]
[1, 0]
[1, 0]
[1, 0]
[1, 0]
[1, 0]
[1, 0]
[1, 0]
[1, 0]
[1, 0]
[1, 0]
[1, 0]
[1, 0]
[1, 0]
[1, 0]
[1, 0]
[1, 0]
[1, 0]
[1, 0]
[1, 0]
[1, 0]
[1, 0]
[1, 0]
[1, 0]
[1, 0]
[4, 0]
[11, 5]
[1, 0]
[9999, 9998]
[6,8]
[6,9]
[12,25]
[16,17]''',file=f)
exit(0)
代码纯享版
class Solution:
def twoSum(self, nums: List[int], target: int) -> List[int]:
hashmap = {}
for i, num in enumerate(nums):
if target - num in hashmap and hashmap[target - num] != i:
return [i, hashmap[target - num]]
hashmap[num] = i
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!