ClickHouse初级 - 第一章Clickhouse入门
clickHouse是俄罗斯的Yandex于2016年开源的列式存储数据库(DBMS),使用c++语言编写,主要用于在线分析处理查询(OLAP),能够使用SQL查询实时生成分析数据报告。
一、ClickHouse的特点
1.1 列式存储
以下面的表为例:
1)采用行式存储时,数据在磁盘上的组织结构为:
好处是想查询某个人所有的属性时,可以通过一次磁盘查询加顺序读取就可以。但是当想查所有人的年龄时,需要不停的查找,或者全表扫描才行,遍历的很多数据都是不需要的。
2)采用列式存储时,数据在磁盘上的组织结构为:
这时想查所有人的年龄只需把年龄那一列拿出来就可以了
3)列式存储的好处:
– 对于列的聚合、计数、求和等统计操作原因优于行式存储。
– 由于某一列的数据类型都是相同的,针对于数据存储更容易进行数据压缩,每一列选择更优的数据压缩算法,大大提高了数据的压缩比重。
– 由于数据压缩比更好,一方面节省了磁盘空间,另一方面对于cache也有了更大的发挥空间。



1.2 DBMS的功能
几乎覆盖了标准SQL的大部分语法,包括DDL和DML,以及配套的各种函数,用户管理及权限管理,数据的备份与恢复。
1.3 多样化引擎
ClickHouse和Mysql类似,把表级的存储引擎插件化,根据表的不同需求可以设定不同的存储引擎。目前包括合并树、日志、接口和其他四大类20多种引擎。
1.4 高吞吐写入能力
1、ClickHouse采用类LSM Tree的结构,数据写入后定期在后台Compaction。通过类LSM tree的结构,ClickHouse在数据导入时全部是顺序append写,写入后数据段不可更改,在后台compaction时也是多个段merge sort后顺序写回磁盘。顺序写的特性,充分利用了磁盘的吞吐能力,即便在HDD上也有着优异的写入性能。
2、官方公开benchmark测试显示能够达到50MB-200MB/s的写入吞吐能力,按照每行100Byte估算,大约相当于50W-200W条/s的写入速度。
1.5 数据分区与线程级并行
1、ClickHouse 将数据划分为多个 partition,每个 partition 再进一步划分为多个 index granularity(索引粒度),然后通过多个 CPU 核心分别处理其中的一部分来实现并行数据处理。 在这种设计下,单条 Query 就能利用整机所有 CPU。极致的并行处理能力,极大的降低了查 询延时。
2、所以,ClickHouse 即使对于大量数据的查询也能够化整为零平行处理。但是有一个弊端 就是对于单条查询使用多 cpu,就不利于同时并发多条查询。所以对于高 qps 的查询业务, ClickHouse 并不是强项。
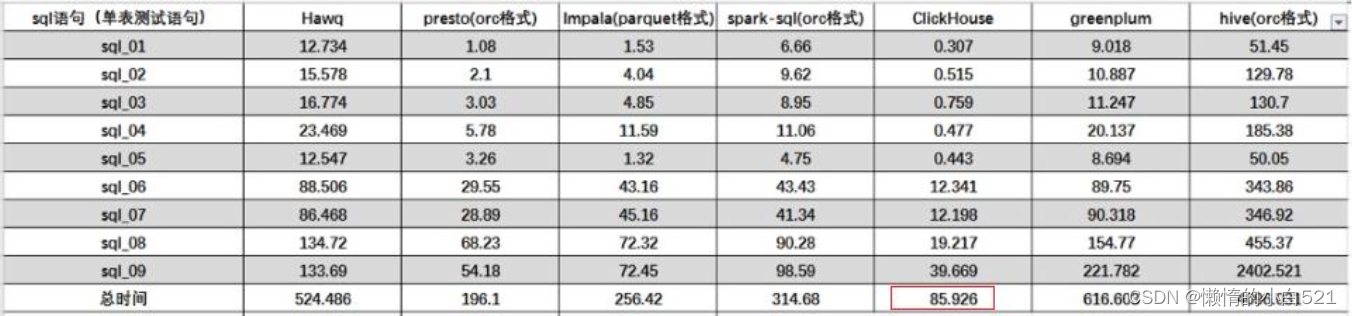
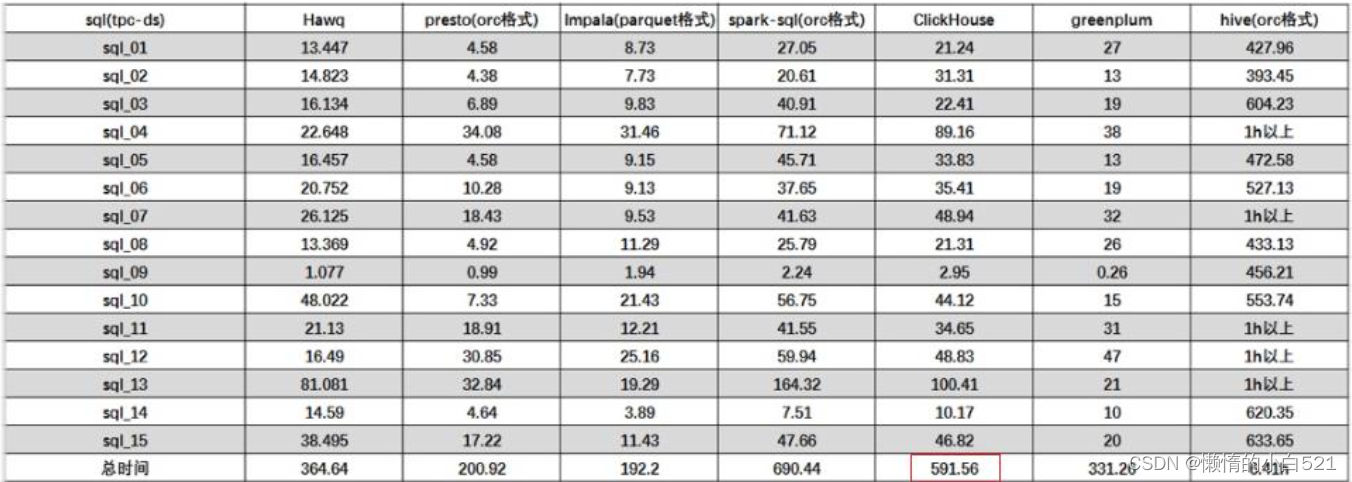
1.6 性能对比
某网站精华帖,中对几款数据库做了性能对比
1、单表查询
2、关联查询
结论:ClickHouse像很多OLAP数据库一样,单表查询速度由于关联查询,而且ClickHouse的两者差距更为明显。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!