1.2 Hadoop概述
小肥柴的Hadoop之旅 1.2 Hadoop概述
)
目录
1.2 Hadoop概述
1.2.1 回归问题
通过前一篇帖子的介绍,特别是问题思考部分的说明,我们大致能够感受到为何需要新的技术体系来解决大数据问题,接下来咱们继续梳理细节。
step_0 传统方案既贵又搞不定大数据问题。
(1)传统数据的处理模式:用户+集中式系统+关系型数据库
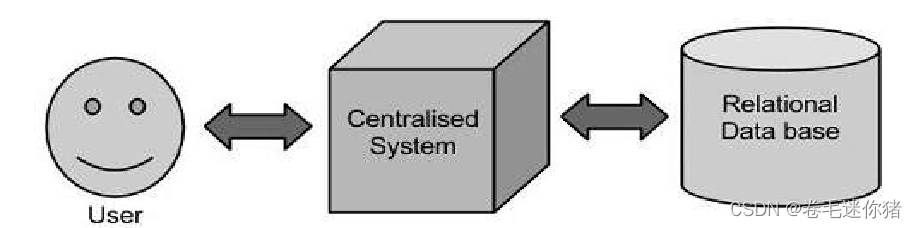
优点是架构相对简单,但缺陷也十分明显:
1)集中式的存储,集中式的计算,中心系统的工作十分繁忙。
2)随着数据和业务的不断增长,往往需要购置更高配置的设备来满足这些需求。
关键在于:高配置的机器好贵的!!!配套设施好贵的!!!维护人工好贵的!!!
正如《潜伏》中的名角“谢若林”的金句,很多事情,“嘴上全是主义,那心里都是生意”!!!
诚然,从技术的角度讨论大数据问题那就是一套一套的理论,容易把人绕的云里雾里的,实际上从资本的角度看待这个问题非常清晰:如何花5块钱把10块钱的事情给办咯,而且还给办得舒坦。
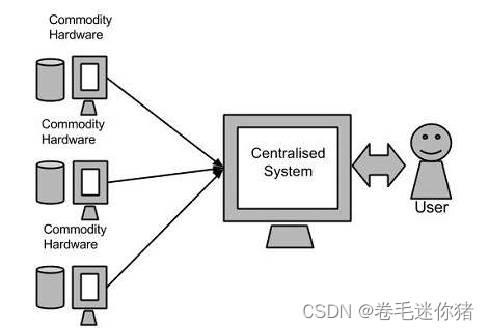
step_1 鸡贼的Google工程师们降成本
(1)不使用超级计算机。
(2)不使用昂贵的集中存储。
(3)甚至大量使用普通的pc做服务器,提供有冗余的集群服务。
即:靠堆大量的、廉价的低性能设备,去完成原来必须依靠昂贵高性能设备才能完成的计算任务。
这点非常像《星际争霸》或者《魔兽争霸》里爆低级兵rush的战术,配上高端的操作一样能rush成功(各种软件设计,譬如Hadoop这一套生态),下面盗个图:

step_2 回顾上贴讨论的内容,海量数据的存储和计算,大数据的核心任务,考虑到相关周边问题,就能和google工程师们的想法对上了。
(1)分布式的文件存储 => GFS(Google File System),分布式文件系统。
(2)分布式的数据库 => BigTable,基于GFS的数据存储系统。
(3)分布式计算框架 => MapReduce,分布式计算框架。
但凡你打开一篇网上系列教程或者一本教材,必然会提及以上三个术语,理解了之前我们讨论的思路和内容,它们就不再是冷冰冰的概念了。
1.2.2 Google的三篇论文
要了解Hadoop的核心组件,就不得不从google的3篇论文开讲,咱们也不免俗套;但在讨论前读者需要具备一定的linux/操作系统/分布式基础知识,否则跟听天书没什么区别。(此处挺直腰杆谴责一下那些前置课程,老师上的水,学生学得拉…)
(1)第一篇: The Google File System (2003)
核心思想:
1)设备挂掉是需要应对的常态;
2)文件数据体量大;
3)绝大部分文件的修改是采用在文件尾部追加数据,而不是覆盖原有数据的方式;
4)应用程序和文件系统 API 的协同设计提高了整个系统的灵活性。
跟着下面这张核心原理图体会一下(假定数据是分布式存储的,等学完HDFS再回头看这个图会有更深的理解):
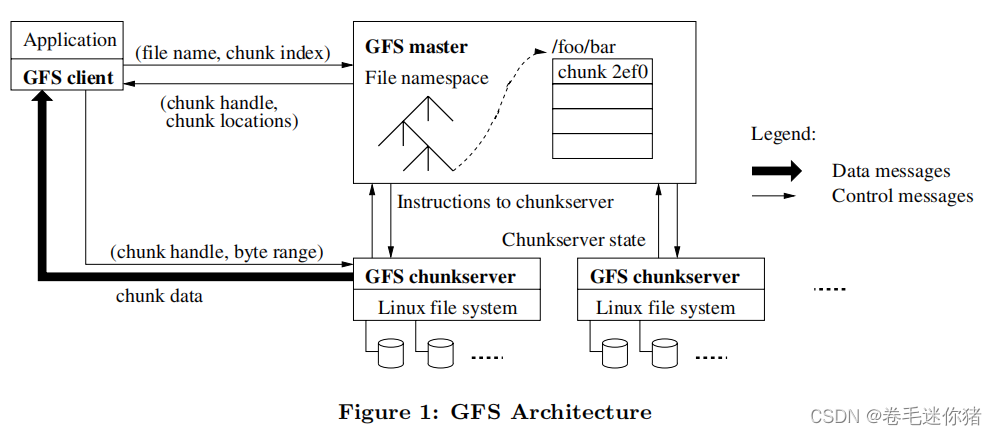
1)client向master查询chunk index的元数据:handle和replica location;根据chunksize,client可以计算出chunk index。
2)client用元数据(meta)直接指向chunkserver要数据,其中 chunk server 是真正存储数据的服务器,以下可以简称为CS。
3)GFS client 使用非POSIX接口交互,仅缓存meta,不缓存data。
4)(主节点)master的内存中有元数据:
i. namespace of file and chunk,文件和数据块的命名空间,方便索引。
ii. mapping files to chunks,文件被拆分为数据块的映射方式。
iii. replica location ,副本位置,通过定期与CS通信获得。
vi. operation log,记录改动元数据的操作,且namespace 和mapping会定期更新,并log化后存储在本地。
v. 数据按照chunk存储,有linux的FS本身的buffer cache做缓存处理,不需要额外缓存机制。
【注】第v点在论文中还有专门的讨论,本质就是为了简化设计。



(以上翻译版本请读者自助)
第二篇:MapReduce: Simplified Data Processing on Large Clusters(2004)
核心思想:
(1)MapReduce 是一个编程模型,也是一个处理和生成超大数据集的算法模型的相关实现。
1)用户首先创建一个 Map 函数处理一个基于 key/value pair 的数据集合,输出中间的基于 key/value pair 的数据集合;
2)然后再创建一个 Reduce 函数用来合并所有的具有相同中间 key 值的中间 value 值。
(2)MapReduce 架构的程序能够在大量的普通配置的计算机上实现并行化处理。
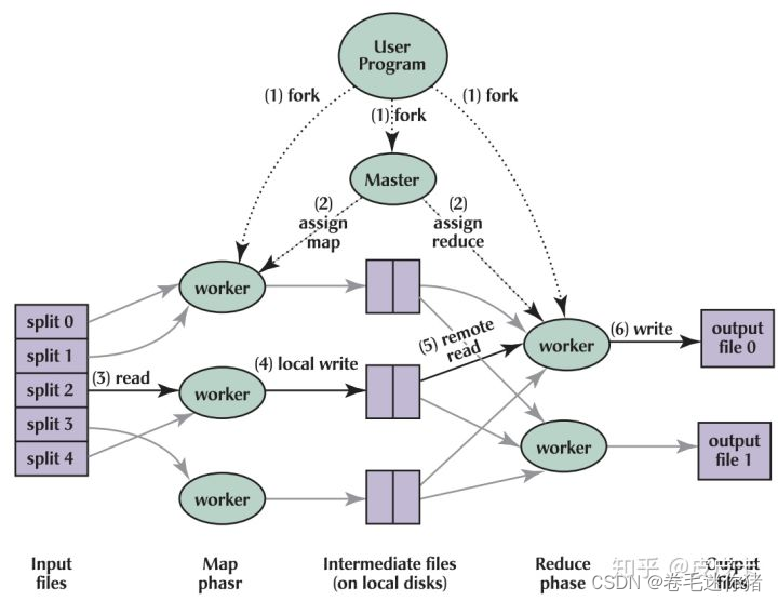
(3)大致执行过程:
1)通过将 Map 调用的输入数据自动分割为 M 个数据片段的集合,Map 调用被分布到多台机器上执行。
2)输入的数据片段能够在不同的机器上并行处理。使用分区函数将 Map 调用产生的中间 key 值分成 R 个不同分区(例如,hash(key) mod R),Reduce 调用也被分布到多台机器上执行,分区数量(R)和分区函数由用户来指定。
【注】以上3点保证了计算模型的通用性,模式化编程能允许没有并行计算和分布式处理系统开发经验的程序员能够有效利用分布式系统的丰富资源去完成数据分析与计算任务。
两句话总结:分而治之 + 计算向数据移动;其中分治是常规策略,但“计算向数据移动”确实是一个当年较为新颖的想法,或许它不是第一次被提出,但确在Hadoop上实现并得到不错的效果。
配两张图方便大家理解上面的文字(盗图):
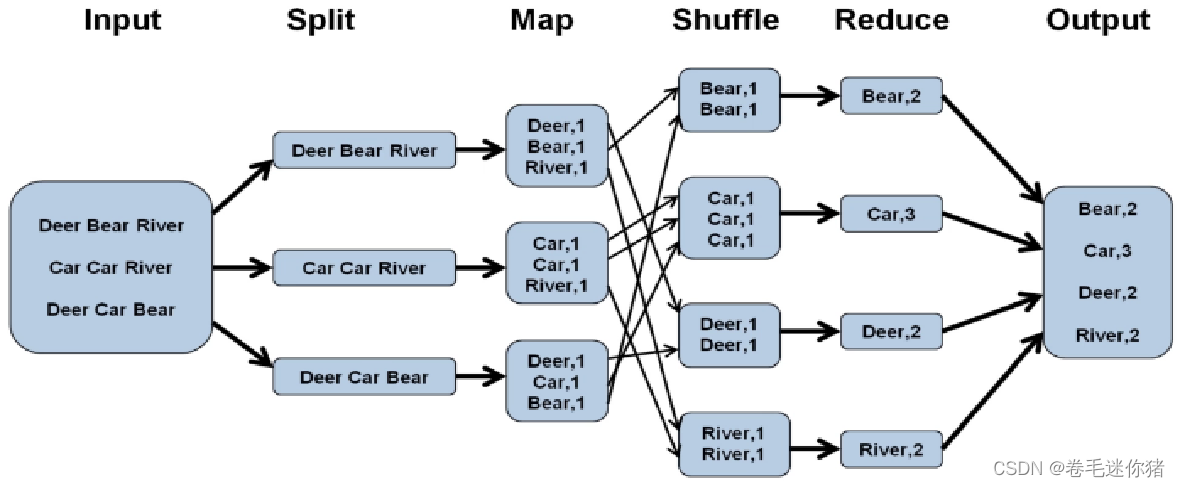
第三篇:Bigtable: A Distributed Storage System for Structured Data(2006)
【注】这块内容其实水很深,需要花一定的时间在实践中慢慢去理解,毕竟会有一门专门的课程《分布式数据库》去讨论整套理论体系和技术栈。
核心思想:
(1)不同于传统的关系型数据库采用行式存储,Bigtable采用了列式存储模式,且是Schema Less的,即“无预定数据模式”,给与用户更多的自定义权利,让数据存储更加灵活自由。
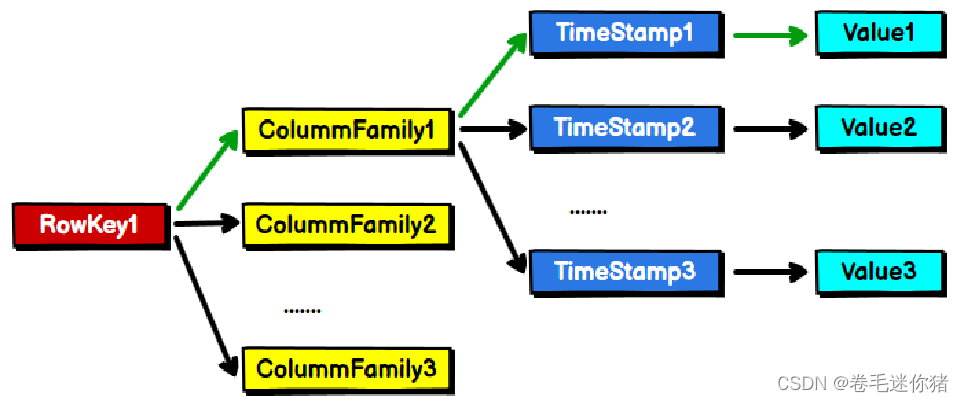
(2)若采用这种方式存储数据,那么原来的K-V形式要做一些改动:
1)Key = Row key + Column key + Timestamp
2)Value都被存储为String形式
3)时间戳Timestamp可以帮助维护历史版本信息
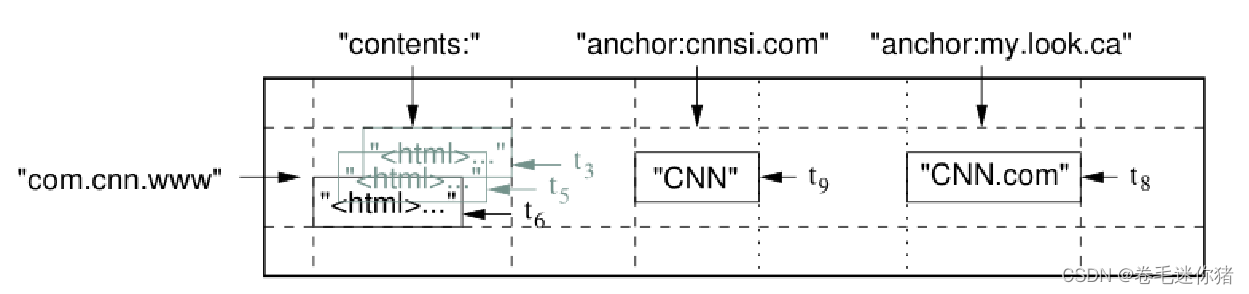
(3)相关术语
1)Tablet:Bigtable 数据分布和负载均衡的基本单位,与子表(table)相关
2)Column Key 与 Column Family:
<1> Column Key 一般都表示一种数据类型,Column Key 的集合称作 Column Family(列族)。
<2> 存储在同一 Column Family 下的数据属于同一种类型,Column Family 下的数据被压缩在一起保存。
<3> Column Family 是 access control(访问控制)、disk and memory accounting(磁盘和内存计算)的基本单元。
【注】以上内容涉及到分区分表细节,将在HBase中详细讲解。
(4)使用列式存储,本质就是方便Range分区。Range 分区能够很好的保证数据在底层存储上与 Row Key 的顺序是一致的(方便排序),对 Scan 类型查询比较友好。
<1> 优点:利用Row Key的局部性(群组),能够提升查询效率。
<2> 缺陷:对用户 Row Key 的设计提出了非常高的要求、容易导致数据不均匀。
(5)BigTable的本质需求就是为了适应大数据分布式场景下,如何正确有效的管理数据库超级大表的问题:
超级大表 --> 大表 --> 小表–> 小小表
对应的两个子问题是:逻辑结构(分区分表,列式存储)要如何设计? 物理映射(基于GFS,数据库最终还是要落盘的)要如何实现?
1.2.3 Hadoop的诞生过程

step_0 明确Hadoop是什么?
Hadoop根据是基于Google三篇论文实现的一种分布式系统基础
Google: GFS、MapReduce、Bigtable
Hadoop: HDFS、MapReduce、HBase
三句话:
(1)Hadoop是Apache基金会的开源项目(本课程仅讨论Apache开源版本)
(2)主要任务是解决 海量数据的存储 和海量数据的分析计算 问题
(3)广义上Hadoop其实是指一个软件生态圈
对,咱们入门学习Hadoop,其实就是学一个软件生态中最核心最基础的一部分而已;具体参考链接[1]。
step_1 发展历程,看看即可
(1)Hadoop最初是由Apache Lucene项目的创始人Doug Cutting开发的文本搜索库。
(2)Hadoop源自始于2002年的Apache Nutch项目(一个开源的网络搜索引擎并且也是Lucene项目的一部分)。
(3)2004年,Nutch项目也模仿GFS开发了自己的分布式文件系统NDFS(Nutch Distributed File System),也就是HDFS的前身。
(4)2005年,Nutch开源实现了谷歌的MapReduce(2003 GFS, 2004 MapReduce)。
(5)2006年2月,Nutch中的NFS和MapReduce开始独立出来,成为Lucene项目的一个子项目,称为Hadoop,同时Doug Cutting加盟雅虎。
(6)2008年1月,Hadoop正式成为Apache顶级项目,Hadoop也逐渐开始被雅虎之外的其他公司使用。
(7)2008年4月,Hadoop打破世界纪录,成为最快排序1TB数据的系统,它采用一个由910个节点构成的集群进行运算,排序时间只用了209秒。
(8)2009年5月,Hadoop更是把1TB数据排序时间缩短到62秒。
(9)Hadoop从此名声大震,迅速发展成为大数据时代最具影响力的开源分布式开发平台,并成为事实上的大数据处理标准。
step_2 技术演变
主要分为1.x、2.x和3.x时代,具体细节参考官网,等讲完MapReduce之后再回头看这个问题基本不是问题,没有必要强行记忆。

1.2.4 Hadoop特点简介
简单了解即可,后续讨论的内容会反复设计这些特点。
(1)优势(4高)
1)高可靠性: 底层维护多个数据副本,及时某个计算元素或者存储出现 故障,也不会丢失数据。
2)高扩展性:在集群中分配数据,方便的扩展节点。
3)高效性:在MapReduce思想下,Hadoop并行工作,加快任务处理速度。
4)高容错性:若任务失败,能够自动重新分配。
(2)适合场景:大数据分析、离线分析
(3)不适合场景:少量数据、复杂数据、在线分析
(4)最痛苦的事情:海量的小文件数据…
参考文献和资料
[1] 国内外企业在用的大数据技术架构
[2] The Google File System
[3] MapReduce: Simplified Data Processing on Large Clusters
[4] Bigtable: A Distributed Storage System for Structured Data
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!