视觉问答学习(对比学习-3D点云)
1、基于对比学习的方法
自监督学习,不需要人工标注的类别标签信息,而是利用数据本身提供的监督信息来学习样本数据的特征表达,并用于下游任务。在视觉语言表示学习中,通过对比学习实现图像-文本对齐,这种对齐策略能够获得成功是由于它能够最大化图像和匹配文本之间的互信息(Mutual Information,MI)。互信息是一种衡量变量之间相互依赖的方法,通过区分正样本对和负样本对来衡量图像和问题之间的关系。

Li等提出ALBEF模型,引入图像文本对比学习,利用图像编码器、文本编码器和多模态编码器进行预训练,预训练的目标是使图像文本的互信息最大化、图像文本进行细粒度地交互,以及图像文本配对。
Wang等提出了一个统一的视觉语言预训练模型VLMo,它联合学习一个双编码器和一个共享MoME Transformer网络的融合编码器。MoME引入一个模态专家池来编码模态特定信息,并使用共享的自注意力模块来对齐不同的模态。通过MoME进行统一的预训练,模型参数在图像-文本对比学习、屏蔽语言模型和图像-文本匹配任务中共享。
大多数模型的编码器主要从某些不相关/有噪声的图像块或文本分词中提取信息。
Yang等提出了一种新的视觉语言预训练框架TCL。与以往通过交叉模态对比损失简单地对齐图像和文本表示地研究不同,TCL进一步考虑模态内监督,这反过来有利于交叉模态对齐和联合多模态嵌入学习。为了将局部信息和结构信息结合到表示学习中,TCL进一步引入了局部互信息,最大限度地利用全局表示与图像块或文本词语的局部信息之间的互信息。
对比学习能够使匹配的图像-文本尽可能接近,同时使未匹配的图像-文本对相互远离。对比学习的目的是让融合编码器更容易学习多模态交互。但是,视觉问答中的对比学习还存在一定的局限性,它增强了图像和文本的全局互信息,忽略了输入中的局部信息和结构信息。此外,某些噪声可能会主导MI,导致预测倾向于学习不相关的特征。
2、基于三维点云的方法
3D问答以点云作为输入,在回答与3D场景相关的问题时需要语言处理和3D场景理解:
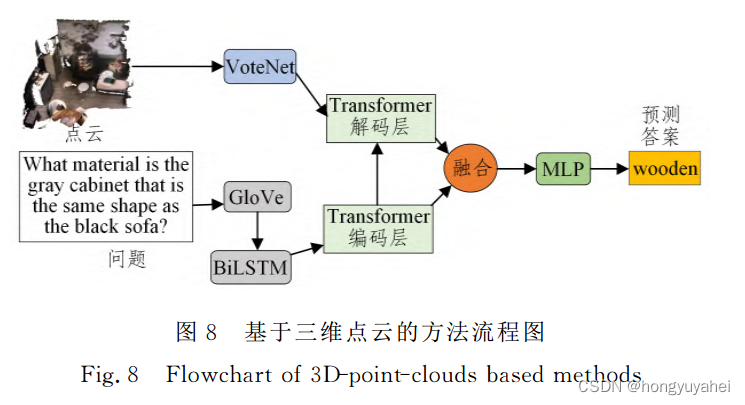

Azuma等提出了一个三维问答的基线模型,称为ScanQA。ScanQA模型包括3D和语言编码器、3D和语言融合模块、物体定位和QA层。3D和语言编码器层将问题转换未特征向量表示,并将点云转换为物体候选框。3D和语言融合层使用基于Transformer的编码器层和解码器层将语言信息引导的多个3D物体特征以及文本信息融合在一起。物体定位和QA层评估目标对象框和对象标签,并预测与问题和场景内容相关的答案。
Ye等提出了一种新的基于Transfomer的3D问答框架3DQA-TR,它利用一个语言分词器来进行问题嵌入,利用两个编码器分别提取外观和几何信息,然后使用3Q-L BERT将外观、几何和语言问题的多模态信息相互关联,以预测目标答案。
Yan等引入3D真实场景中的视觉问答任务,它旨在回答给定的3D场景中所有可能的问题。他们设计了TransVQA3D。TransVQA3D首先使用一个跨模态Transformer来融合问题和物体的特征。然后应用场景图初始化,取场景图的附加边来进行场景图感知注意,从而获得物体之间的关系并推断出答案。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!