Python实战:获取瑞幸咖啡全国门店和职能部门,竟有接近1.2万个门店
Python实战:获取瑞幸咖啡全国门店和职能部门,竟有接近1.2万个门店
前段时间通过 Python 实战,获取了 全国 6947 个星巴克门店的信息。
详见: python 实战:爬取全国星巴克门店信息,上海竟有 1115 个门店!
今天,就有读者在公众号后台问到能不能爬取一下瑞幸的门店,这也激起了我的好奇心,说干就干。
打开瑞信咖啡挂网,https://lkcoffee.com/,并没有发现可以找到门店的入口,出师不利。

继续随便浏览下官网的其他页面,来到了“关于我们”——“加入我们”——“门店招聘”这个页面,直觉告诉我这里可能会有数据。
点击“门店招聘”,跳转到招聘页面。(本文首发在“程序员coding”公众号)
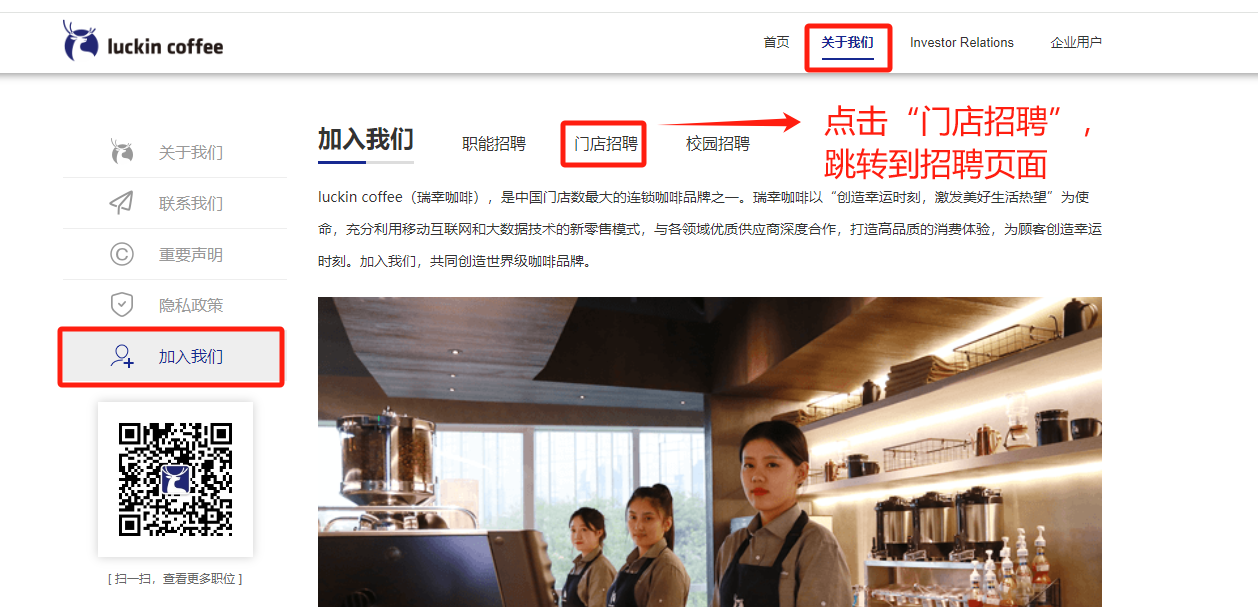
在招聘页面,分析可以发现这个页面是瑞幸全国所有门店和分公司发布招聘信息的总页面,数据更新日期也是最新的。
在“所属部门”这个输入框内,可以从网页源代码中提取到所有在招聘的门店和部门。以这种餐饮服务行业门店来说,人员流动性较大,门店和部门招聘应该是不间断的,所以可以从这里获取到全国的瑞幸门店。


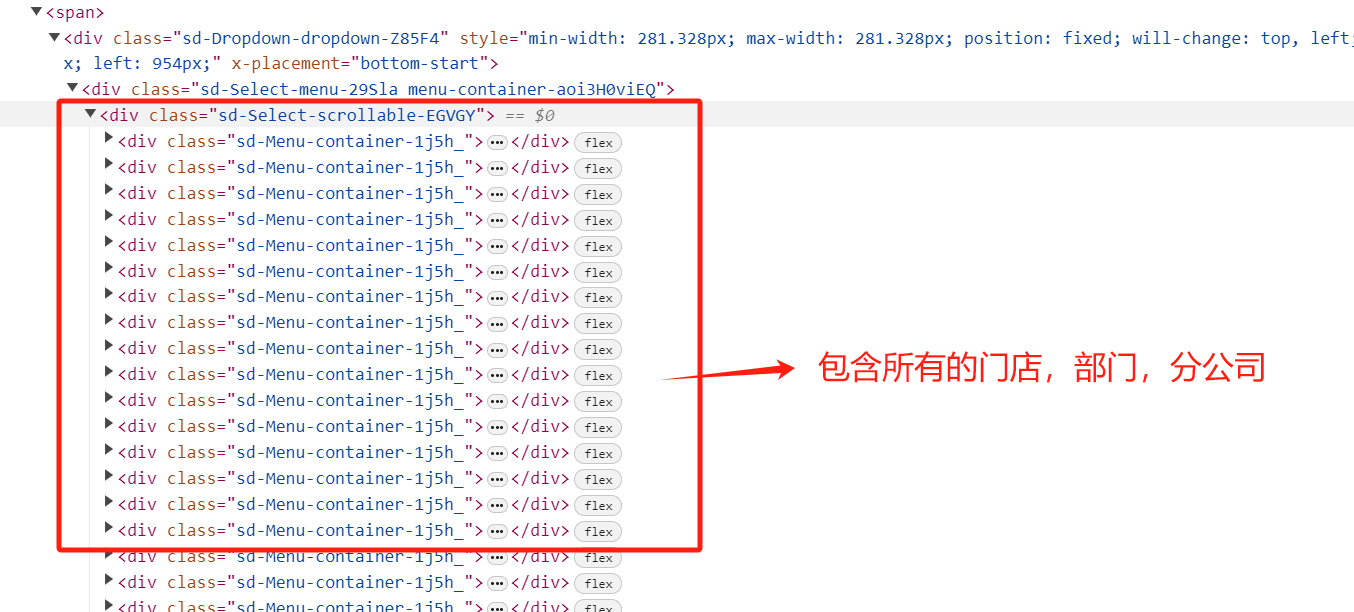
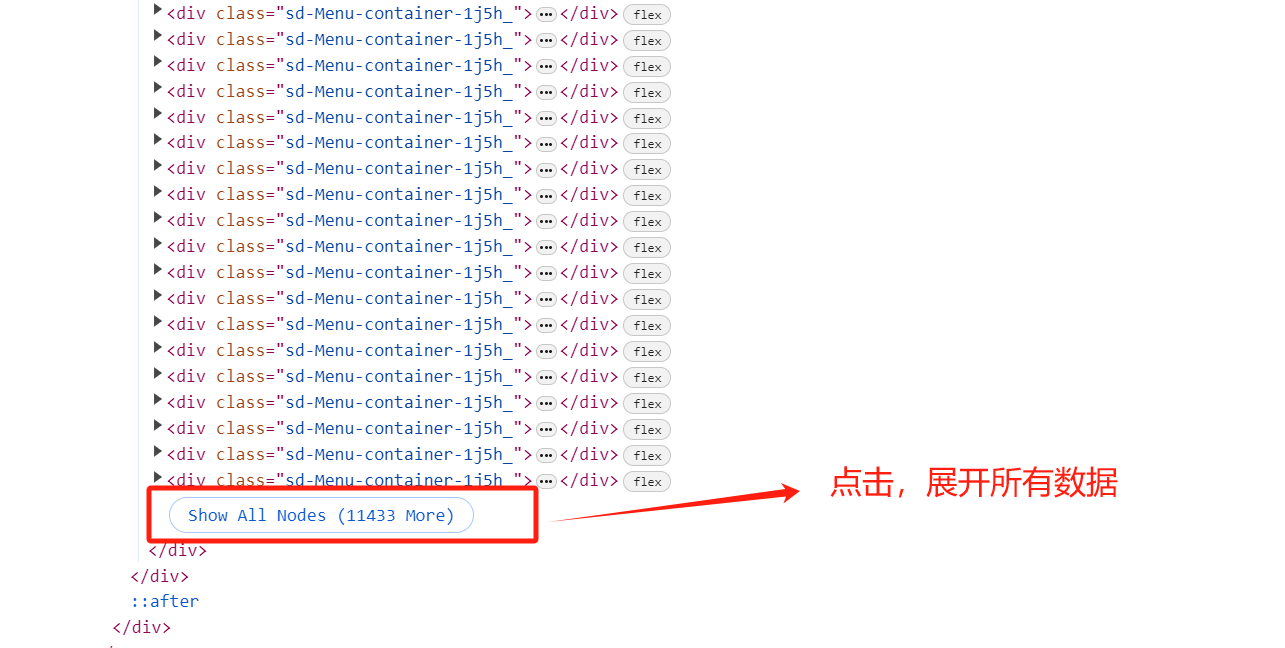
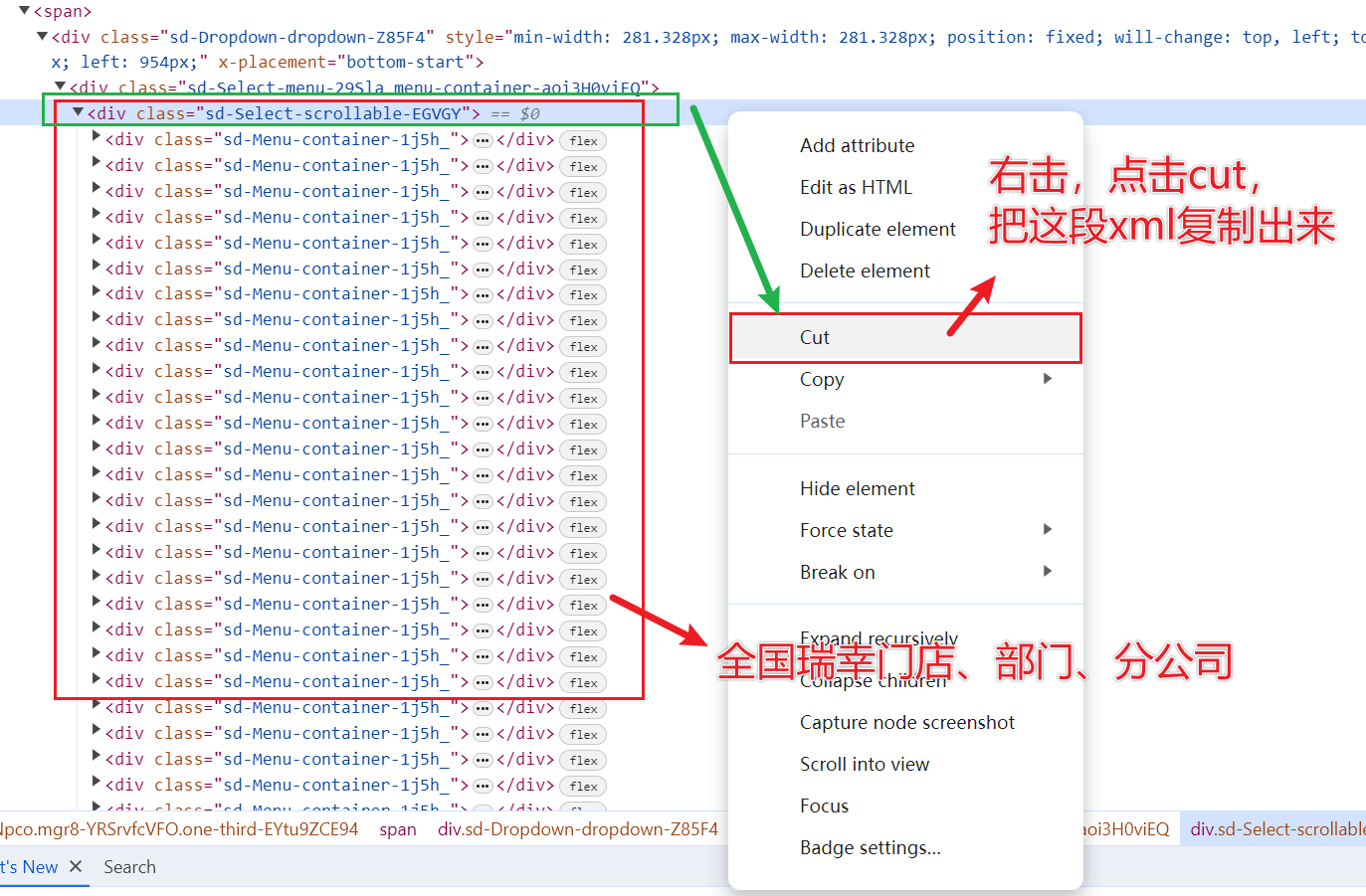
新建一个瑞幸全国门店.html文件,把剪切板中刚这段 xml 粘贴出来,保存,关闭,得到一个 3M 大小的瑞幸全国门店.html文件。(本文首发在“程序员coding”公众号)
由于文件太大,超出 Pycharm 中的限制了,把下面这段代码加到到 Pycharm 自定义配置,修改可以加载的文件大小。
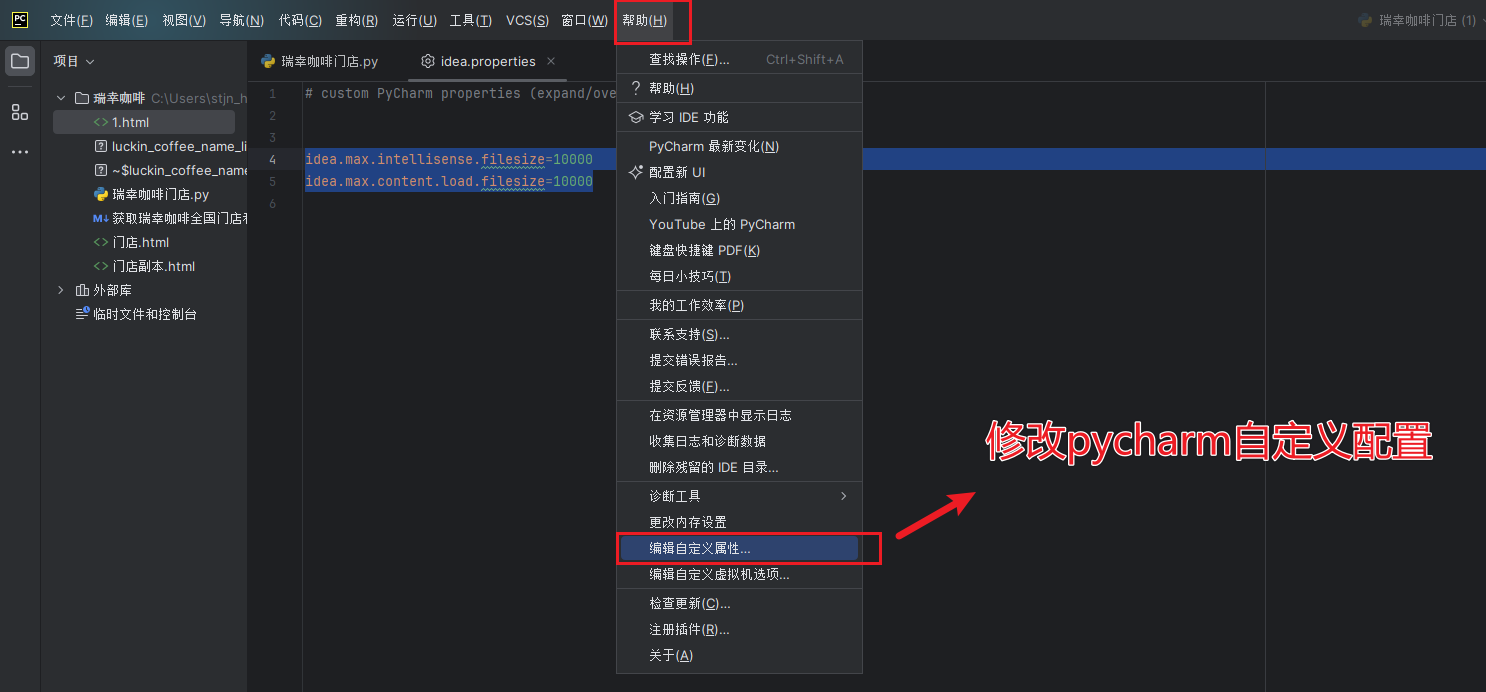
idea.max.intellisense.filesize=10000
idea.max.content.load.filesize=10000
html 文件格式如下,可以看出,门店的名字都在相同的标签内:<div class="sd-Menu-content-item-3-VNQ"><span>环球经贸中心店</span></div>
<div class="sd-Select-scrollable-EGVGY">
<div class="sd-Menu-container-1j5h_"><span style="width: 0px; flex: 0 0 auto;"></span>
<div class="sd-Menu-content-2q4Rk sd-Menu-leftItem-3slI8">
<div class="sd-Menu-content-item-3-VNQ"><span>武汉分公司</span></div>
</div>
</div>
<div class="sd-Menu-container-1j5h_"><span style="width: 0px; flex: 0 0 auto;"></span>
<div class="sd-Menu-content-2q4Rk sd-Menu-leftItem-3slI8">
<div class="sd-Menu-content-item-3-VNQ"><span>广州分公司</span></div>
</div>
</div>
<div class="sd-Menu-container-1j5h_"><span style="width: 0px; flex: 0 0 auto;"></span>
<div class="sd-Menu-content-2q4Rk sd-Menu-leftItem-3slI8">
<div class="sd-Menu-content-item-3-VNQ"><span>环球经贸中心店</span></div>
</div>
</div>
</div>
接下来就可以通过 xpath 技术解析这个本地的 html 文件了,Python 代码如下:
#(本文首发在“程序员coding”公众号)
from lxml import etree
# 解析本地文件使用 etree.parse
tree = etree.parse('瑞幸全国门店.html')
# name_list是个列表,表示所有的公司和门店,有重复值
name_list = tree.xpath('//div[@class="sd-Menu-content-item-3-VNQ"]/span/text()')
print("解析html网页,有", len(name_list), "个门店(有重复值),分别是:", name_list)
# 按原来列表顺序去重
# 第一步,列表name_list包含重复的值,转为集合,去除重复项。再转为列表,unique_name_list的值就是唯一的不重复的
unique_name_list = list(set(name_list))
# 第二步,按照原列表name_list的顺序给unique_name_list排序
unique_name_list.sort(key=name_list.index)
print("去重处理后,剩余", len(unique_name_list), "个门店,分别是:", unique_name_list)
# 在unique_name_list列表中,查找含有“店”的字符
luckin_coffee_store = [s for s in unique_name_list if '店' in s]
print("含有“店”这个字的有", len(luckin_coffee_store), "个门店,分别是:", luckin_coffee_store)
Pycharm 控制台输出如下:解析 html 网页获取到 11934 个门店,去重后剩余 11879 个门店,筛选名字里含有“店”这个字的有 11817 个门店。
瑞幸竟有 11817 个门店在招聘,果然瑞.民族之光.幸牛逼!!!
实际门店数量还要比 11817 多几个,因为还有几个门店名字里没有“店”这个字。

将门店保存到 txt 文件,Python 代码如下:
# 将门店保存到txt文件
f = open(r'瑞幸全国门店.txt', 'w', encoding='utf-8')
for i in luckin_coffee_store:
f.write(str(i) + '\n')
print("成功保存到文件:瑞幸全国门店.txt")
f.close()
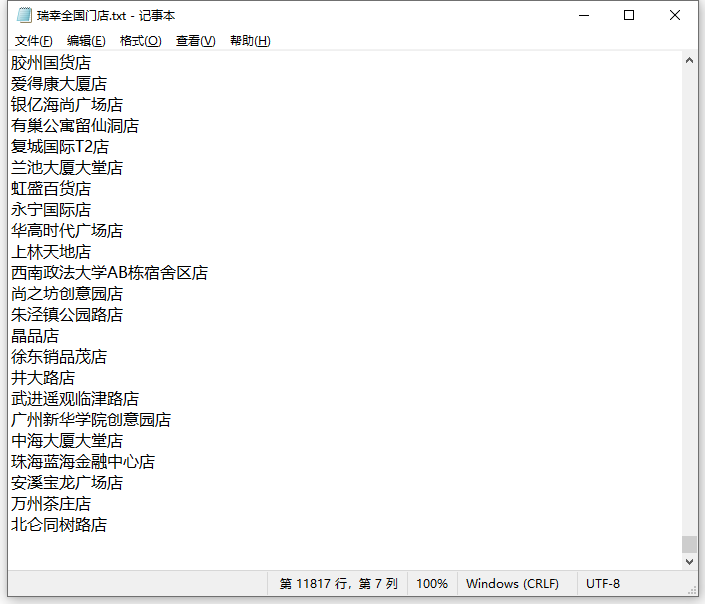
保存的《瑞幸全国门店.txt》如下,共有 11817 行:
将门店保存到 excel 文件,Python 代码如下:
import pandas as pd
# list转dataframe
df = pd.DataFrame(luckin_coffee_store, columns=['company_name'])
# 保存到本地excel
df.to_excel("瑞幸全国门店.xlsx", index=False)
print("成功保存到文件:瑞幸全国门店.xlsx")
保存的《瑞幸全国门店.xlsx》如下,共有 11817 行:

整合代码,构造函数,完整代码:
#(本文首发在“程序员coding”公众号)
from lxml import etree
import pandas as pd
# 解析html文件,得到门店的名字,存到列表里
def luckin_coffee():
# 解析本地文件使用 etree.parse
tree = etree.parse('瑞幸全国门店.html')
# name_list是个列表,表示所有的公司和门店,有重复值
name_list = tree.xpath('//div[@class="sd-Menu-content-item-3-VNQ"]/span/text()')
print("解析html网页,有", len(name_list), "个门店(有重复值),分别是:", name_list)
# 按原来列表顺序去重
# 第一步,列表name_list包含重复的值,转为集合,去除重复项。再转为列表,unique_name_list的值就是唯一的不重复的
unique_name_list = list(set(name_list))
# 第二步,按照原列表name_list的顺序给unique_name_list排序
unique_name_list.sort(key=name_list.index)
print("去重处理后,剩余", len(unique_name_list), "个门店,分别是:", unique_name_list)
# 在unique_name_list列表中,查找含有“店”的字符
luckin_coffee_store = [s for s in unique_name_list if '店' in s]
print("含有“店”这个字的有", len(luckin_coffee_store), "个门店,分别是:", luckin_coffee_store)
return luckin_coffee_store
# 保存列表到txt
def save_list_to_txt(list):
luckin_coffee_name_list = list
# 将门店保存到txt文件
f = open(r'瑞幸全国门店.txt', 'w', encoding='utf-8')
for i in luckin_coffee_name_list:
f.write(str(i) + '\n')
print("成功保存到文件:瑞幸全国门店.txt")
f.close()
# 保存列表到excel
def save_list_to_excel(list):
# 列表
luckin_coffee_name_list = list
# list转dataframe
df = pd.DataFrame(luckin_coffee_name_list, columns=['company_name'])
# 保存到本地excel
df.to_excel("瑞幸全国门店.xlsx", index=False)
print("成功保存到文件:瑞幸全国门店.xlsx")
if __name__ == '__main__':
# 解析html文件,得到门店的名字,存到列表里
luckin_coffee_store = luckin_coffee()
# 调用函数,将列表内容保存到excel文件
save_list_to_excel(luckin_coffee_store)
# 调用函数,将列表内容保存到txt文件
save_list_to_txt(luckin_coffee_store)
Pycharm 控制台输出如下:解析 html 网页获取到 11934 个门店,去重后剩余 11879 个门店,筛选名字里含有“店”这个字的有 11817 个门店,并且保存到 excel 文件和 txt 文件。

彩蛋
一开始,我没有对结果进行筛选,保留下来一些分公司、部门、区域、组这些数据,用 Python 处理一下,得到一些有意思的发现,代码如下:
from lxml import etree
# 解析本地文件使用 etree.parse
tree = etree.parse('瑞幸全国门店.html')
# name_list是个列表,表示所有的公司和门店,有重复值
name_list = tree.xpath('//div[@class="sd-Menu-content-item-3-VNQ"]/span/text()')
print("解析html网页,有", len(name_list), "个门店(有重复值),分别是:", name_list)
# 按原来列表顺序去重
# 第一步,列表name_list包含重复的值,转为集合,去除重复项。再转为列表,unique_name_list的值就是唯一的不重复的
unique_name_list = list(set(name_list))
# 第二步,按照原列表name_list的顺序给unique_name_list排序
unique_name_list.sort(key=name_list.index)
print("去重处理后,剩余", len(unique_name_list), "个门店,分别是:", unique_name_list)
# 在unique_name_list列表中,查找含有“店”的字符
luckin_coffee_store = [s for s in unique_name_list if '店' in s]
luckin_coffee_store.sort()
print("含有“店”这个字的有", len(luckin_coffee_store), "个门店,分别是:", luckin_coffee_store)
# 在unique_name_list列表中,查找含有“公司”的字符
luckin_coffee_company = [s for s in unique_name_list if ('公司' in s and '店' not in s)]
luckin_coffee_company.sort()
print("含有“公司”这个字的有", len(luckin_coffee_company), "个,分别是:", luckin_coffee_company)
# 在unique_name_list列表中,查找含有“部”或“办”的字符
luckin_coffee_department = [s for s in unique_name_list if ('部' in s and '店' not in s) or ('办' in s and '店' not in s)]
luckin_coffee_department.sort()
print("含有“部”或“办”这个字的有", len(luckin_coffee_department), "个,分别是:", luckin_coffee_department)
# 在unique_name_list列表中,查找含有“组”的字符
luckin_coffee_group = [s for s in unique_name_list if ('组' in s and '店' not in s)]
luckin_coffee_group.sort()
print("含有“组”这个字的有", len(luckin_coffee_group), "个,分别是:", luckin_coffee_group)
# 在unique_name_list列表中,查找含有“区域”的字符
luckin_coffee_region = [s for s in unique_name_list if '区域' in s]
# 排序
luckin_coffee_region.sort(key=lambda arr: (arr[:2], int(arr[2:])))
print("含有“区域”这个字的有", len(luckin_coffee_region), "个,分别是:", luckin_coffee_region)
# 在unique_name_list列表中,查找含有“培训”的字符
luckin_coffee_training = [s for s in unique_name_list if '培训' in s]
# 排序
luckin_coffee_training.sort()
print("含有“培训”这个字的有", len(luckin_coffee_training), "个,分别是:", luckin_coffee_training)
Pycharm 控制台输出如下:

瑞幸在全国有上海分公司、北京分公司、南京分公司、天津分公司、宁波分公司、广州分公司、成都分公司、杭州分公司、武汉分公司、沈阳分公司、深圳分公司、福建分公司、苏州分公司、西安分公司、重庆分公司、长沙分公司 16 个分公司在招聘。
有人事行政部、发展 1 部、发展部、总经办、拓展规划部、营建部、设备部、资产管理部、运营管理部、运营部、预算与财务分析部 11 个部门在招聘。
有区域 1、区域 2、区域 3、区域 4、区域 5、区域 6、区域 7、区域 8、区域 9、区域 10、区域 12、区域 13、区域 14、区域 15、区域 18、区域 19、区域 20、区域 21、区域 28 等 19 个区域在招聘。
还有培训教室-天津、培训教室-西安、培训教室-长沙 3 个培训基地在招聘。
瑞.民族之光.幸牛逼!!!
可在“程序员 coding”公众号回复“瑞幸”获取完整代码和数据集。

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!