Mixtral-8x7B MoE大模型微调实践,超越Llama2-65B
Mixtral-8x7B 在各大榜单中取得了及其优异的表现,本文主要分享我们微调Mixtral-8x7B MoE模型的初步实践。我们使用Firefly项目对其进行微调,在一张V100上,仅使用4.8万条数据对Mixtral-8x7B-v0.1基座模型微调了3000步,取得了非常惊艳的效果。
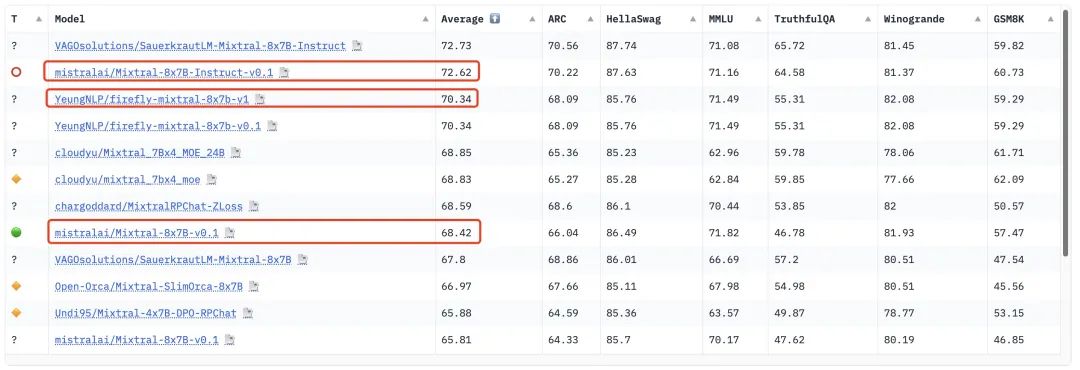
我们的模型在🤗Open LLM Leaderboard上的分数为70.34分,比Mixtral-8x7B-v0.1提升1.92分,比官方的chat模型低2.28分。若对训练数据和流程进行更精细的调整,应该还有较大的提升空间。
注意,Mixtral-8x7B-v0.1为预训练模型,具有非常弱的指令遵从能力,我们在此基础上进行微调,旨在验证方法的有效性。若读者希望在自己的下游任务中进行微调,可基于Mixtral-8x7B-Instruct-v0.1进行微调。
我们也对比了其他主流的开源模型在🤗Open LLM Leaderboard的表现。得益于Mixtral-8x7B强大的基座能力,Firefly微调的模型把Llama2-65B、Yi-34B、Vicuna-33B和Qwen-14B等模型都甩在了身后。
值得注意的是:由于MoE的稀疏性,我们的模型的推理成本与速度,理论上接近于两个7B的模型。这对Llama2-65B无疑是降维打击,该MoE模型不但有着更好的表现,推理速度与成本也大大优于Llama2-65B。
加入方式
建了大模型技术交流群!想要学习、技术交流、获取如下原版资料的同学,可以直接加微信号:dkl88194。加的时候备注一下:研究方向 +学校/公司+CSDN,即可。然后就可以拉你进群了。
方式①、添加微信号:dkl88194,备注:来自CSDN + 技术交流
方式②、微信搜索公众号:Python学习与数据挖掘,后台回复:加群
Firefly项目地址:
https://github.com/yangjianxin1/Firefly
firefly-mixtral-8x7b完整权重:
https://huggingface.co/YeungNLP/firefly-mixtral-8x7b
firefly-mixtral-8x7b LoRA权重:
https://huggingface.co/YeungNLP/firefly-mixtral-8x7b-lora
Mixtral-8x7B简介
近期,Mistral AI发布的Mixtral-8x7B模型,引发了大模型开源社区的剧烈反响。这是一个混合专家模型(Mixture-of-Expert,MoE),参数量约为46.7B,包含8个专家网络。在许多大模型评测榜单上,取得了非常优越的成绩。
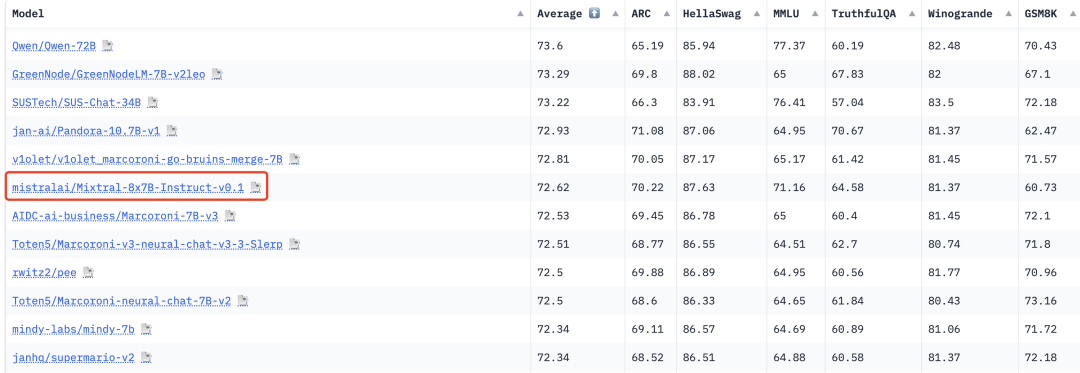
在🤗Open LLM Leaderboard上,Mixtral-8x7B大幅超越LLaMA2-65B。
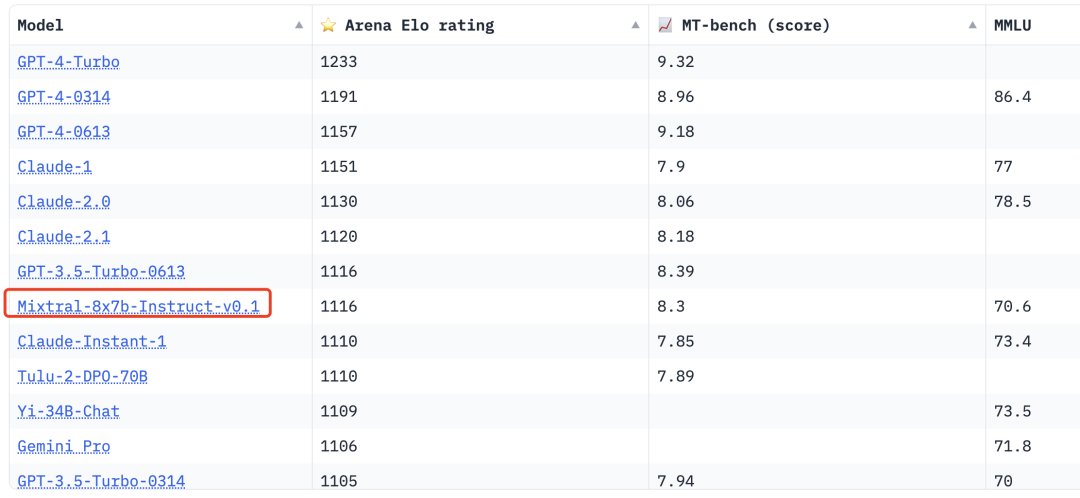
在Chatbot Arena Leaderboard中,Mixtral-8x7B也超越了许多耳熟能详的闭源大模型,例如GPT-3.5-Turbo-0314、Claude-Instant-1、Gemini Pro等,可谓是开源大模型之光。
虽然Mixtral-8x7B模型的参数量巨大,但由于MoE模型具有稀疏性,它的推理成本比同参数量的模型低得多,推理速度也快得多。其稀疏性具体表现为:在训练和推理时,同时只有两个专家网络会被激活,进行前向计算,其它专家网络处于失活状态。更具体地说:模型中存在SparseMoeBlock,在SparseMoeBlock中,每个隐形量只会被分配给两个专家网络进行前向计算,然后加权求和得到输出,其他专家则不参与该隐向量的前向计算。可以将其稀疏性与Dorpout机制进行形象的类比,Dropout是让部分神经元失活,而MoE则是让部分专家网络失活。
在此,我们暂且不对Mixtral-8x7B的MoE原理展开介绍,后续我们将会专门撰写一篇文章对其MoE部分的技术细节进行分析介绍。如想对MOE原理有基本的了解,可以看之前写过的一篇文章:大模型分布式训练并行技术
总而言之,我们可以按照如下方式来理解Mixtral-8x7B:
-
更大的参数量:通过MoE技术将8个Mistral-7B模型进行组合(比较简单粗暴的理解方式),形成了一个具有更大参数量的模型。
-
更快的推理速度,更低的推理成本:同一时刻只有两个专家网络会被激活,可将其推理成本与推理速度视为约等于两个Mistral-7B(实际上速度更快)。
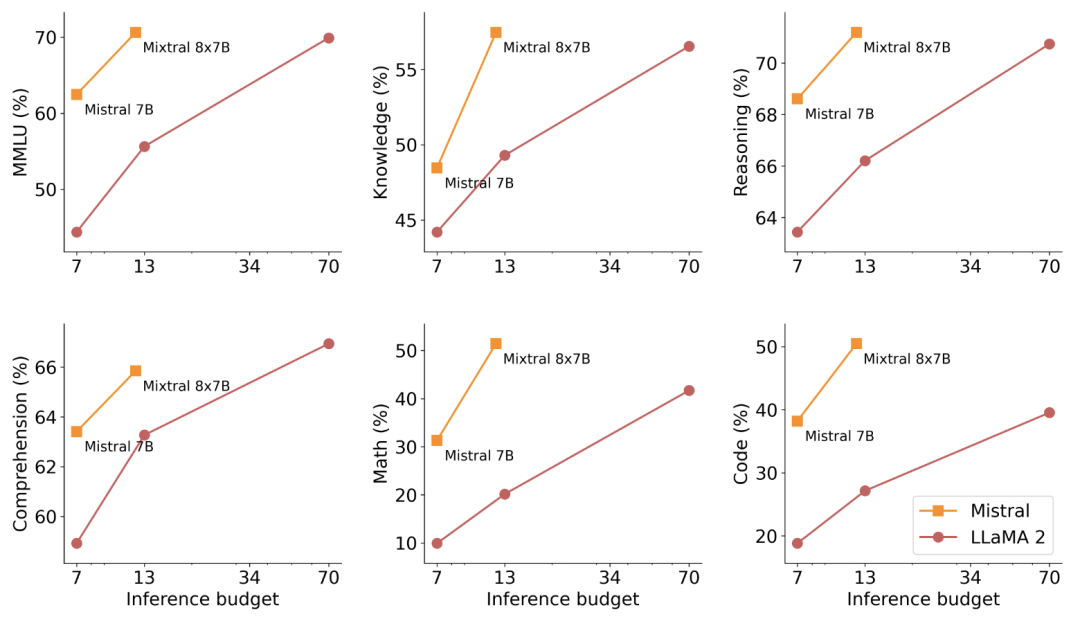
下图中展示了不同模型的评测表现及其推理预算。与LLaMA2系列模型相比,Mistral-7B与Mixtral-8x7B不仅评测表现优秀,且推理预算也很低。
训练策略
我们采用ultrachat数据集进行训练,这是一个英文的多轮对话数据集。我们对其进行过滤筛选,最后参与训练的数据量为48000条。
Mixtral-8x7B-Instruct-v0.1是官方的chat模型,它已经具备优秀的指令遵从能力,不过官方并未公开其训练策略。为了验证Firefly微调MoE模型的策略的有效性,我们并未直接基于Mixtral-8x7B-Instruct-v0.1进行微调,而是选择对指令遵从能力较弱的预训练模型Mixtral-8x7B-v0.1进行微调。
在多轮对话微调时,我们沿用Mistral AI官方的数据拼接方式,且仅计算target部分的loss。数据拼接示例如下:
<s>[INST]你是谁?[/INST]我是Firefly大模型</s>[INST]背诵李白的《静夜思》[/INST]窗前明月光...</s>
我们采用Firefly项目中的QLoRA训练流程,在一张V100上进行训练。为了节省显存,LoRA一般仅在q_proj和v_proj处插入adapter,lora_rank设为8,参与训练的参数量约为百万或千万的量级,训练效果会打折扣。为了弥补量化带来的精度损失,我们参照QLoRA论文的实验设置,在所有layer中均插入adapter,将lora_rank设为16,最终参与训练的参数量约为2.4亿。
若读者的训练显存更大,可适当提升lora_rank至32或64,以提升训练效果。若读者的训练显存更小,产生OOM,可以尝试减小lora_rank至8,或者减少插入adapter的layer,但效果可能会有所降低。
训练时的损失函数包含两部分:常规的语言模型的损失函数 ,负载均衡损失 。最终的损失函数 。其中 为超参数,我们设为0.02。
部分训练的超参数设置如下
per_device_train_batch_size: 1
gradient_accumulation_steps: 16
learning_rate: 1e-4
max_seq_length: 1024
lr_scheduler_type: constant_with_warmup
warmup_steps: 500
lora_rank: 16
lora_alpha: 16
lora_dropout: 0.05
直接执行以下脚本即可在单卡上进行训练。
python train_qlora.py --train_args_file train_args/qlora/mixtral-8x7b-sft-qlora.json
模型效果
得益于基座模型Mixtral-8x7B-v0.1的优秀,模型在函数计算、解方程等数学题的表现让人眼前一亮。


电影评价、旅游博客等开放式生成任务,则更不在话下。

我们从维基百科中摘取了一些关于梅西的长文本片段,询问“梅西的年龄以及在巴塞罗那获取了哪些冠军头衔”。
模型回复完全正确:“梅西现年36岁。 在巴塞罗那效力期间,他赢得了创俱乐部纪录的34座奖杯,其中包括10次西甲冠军、7次国王杯冠军和4次欧洲冠军联赛冠军”。这表明该MoE模型在RAG中的应用也很有前景。

结语
Mixtral-8x7B MoE大模型的开源以及各种“越级”的表现,让开源社区兴奋不已,给MoE技术又注入了一针强心剂。自从Mixtral-8x7B开源后,各大机构和研究者应该也在摩拳擦掌,后续应该也会涌现出更多MoE的开源工作。在🤗Hugging Face社区,已经出现了许多MoE模型,MoE大模型已经展现出成为下一个研究热点的势头。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!