分布式数据库事务故障恢复的原理与实践
关系数据库中的事务故障恢复并不是一个新问题,自70年代关系数据库诞生之后就一直伴随着数据库技术的发展,并且在分布式数据库的场景下又遇到了一些新的问题。本文将会就事务故障恢复这个问题,分别讲述单机数据库、分布式数据库中遇到的问题和几种典型的解决方案,以及 OceanBase 在事务故障恢复方面的相关实践。
一、从单机数据库说起
大家都知道,数据库中事务具有四大属性:ACID,其中和事务故障恢复相关的属性是 A 和 D:
- 原子性(Atomicity):事务内的修改要么都生效,要么都不生效;
- 持久性(Durability):如果数据库宕机,已经完成提交的事务结果不应该丢失
例如在如下图所示的两个事务执行过程中:
?

在数据库出现宕机时,Trx1 还没有执行完成,而 Trx2 已经完成提交,原子性和持久性要求在宕机恢复后,Trx1 的所有修改都不生效,且 Trx2 的所有修改都必须被持久化。为了达到这个要求,数据库必须在宕机重启后执行两个动作:
- 回滚:移除所有未完成以及回滚事务的修改;
- 重做:重新执行已经完成提交的事务的修改,确保持久性;
1.1 Shadow Paging
一种比较简单的保证事务原子性和持久性的方法是 Shadow Paging。这个方法非常容易理解,数据库维护两个独立的数据“版本”,分别称为 master 和 shadow 版本,写事务的所有修改操作写入在 shadow 版本上(其他事务读取仅读取 master 版本,shadow 版本对读取不可见),当写事务提交时,需要在完成提交前将 shadow 版本切换为 master 版本。
?
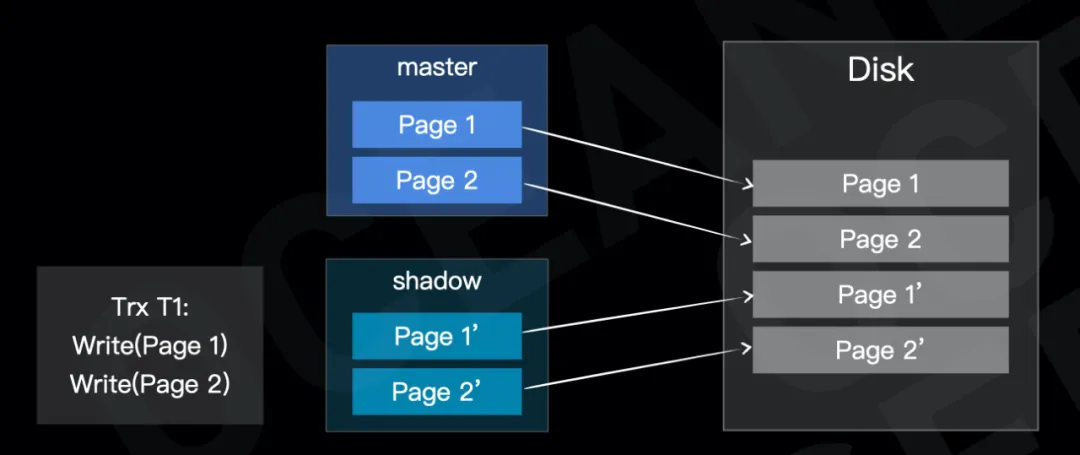
当数据库发生宕机重启时,并不需要做对应的回滚和重做操作(仅回收可能残留的 shadow 版本数据即可)。
LMDB(Lightning Memory-Mapped Database) 就是一个真正应用了 Shadow Paging 方法的数据库例子。LMDB 是一个基于内存文件映射的 KV 数据库,事务修改时采用 Copy-on-write 的方式对 B+tree 索引结构进行修改,当写事务在修改数据时,会对修改部分 Copy 出新的 B+tree,并在事务提交前,将新的根节点落盘,读取事务总是从当前生效的最新根节点开始执行。
?

?
1.2 数据落盘策略
回顾前文,在宕机重启时,必须要执行回滚和重做两个操作。回滚的目的是消除磁盘上存在的未提交事务的修改,但 Shadow Paging 方法在事务提交前并不会修改 master 版本,所以无需执行回滚操作;重做的目的是将已经提交但是没有完成落盘的事务修改恢复出来,但 Shadow Paging 方法在事务提交前一定已经将所有修改完成落盘并修改 master 版本,所以也无需执行重做操作。
由此可以看出,事务故障恢复所需要执行的操作和事务执行过程中数据落盘的策略是相关的。
?

数据库领域中将事务执行过程中数据落盘的策略归纳描述为两点:
- Steal/No-Steal:指事务在执行过程中是否允许未提交的事务修改磁盘上的最新数据;
- Force/No-Force:指事务在提交前是否要求将所有修改落盘;
实现了 Steal 属性的数据库系统,需要在宕机重启后做回滚操作以消除未提交事务的修改;实现 No-Force 的数据库系统,需要宕机重启对已提交事务做重做操作来恢复出未落盘的修改。
Shadow Paging 属于 No-Steal & Force 的系统,所以宕机恢复的过程非常简单。但是宕机恢复过程的简单是以运行时的复杂为代价的,No-Steal 要求事务在提交前都不能落盘,对大事务不友好;Force 在事务提交时增加了写盘压力和延时。通常来说,Steal & No-Force 对注重运行时表现的系统是比较理想的。
1.3 Logging
那么如何实现一个满足 Steal & No-Force 的数据库系统呢?接下来我们分析几种基于日志的实现方法。
1.3.1 Redo 日志
如果在事务修改过程中生成 Redo(记录修改后的新值)日志,则在宕机重启后,系统可以通过回放 Redo 日志进行已提交事务的重做过程,但是无法做到未提交事务的回滚,因此,采用 Redo 日志的系统规则如下:
- 对于每一次修改,产生 Redo 日志记录(包含修改后的新值);
- 事务 Commit 前(Commit 日志落盘),事务的所有修改不能落盘(No-Steal);
- 事务提交成功前,事务的所有日志记录(非数据)必须先落盘 (No-Force);
RocksDB 是一个典型的使用 Redo 日志的例子(暂不讨论 WriteUnprepared),事务的写入在提交前不能落盘,缓存在内存中事务专属的 WriteBatch中,当事务确定提交时,首先生成所有修改的 Redo 日志并落盘,然后才能将 WriteBatch 中的数据写入到 memtable 中。
?

Redo 日志属于 No-Steal & No-Force 的系统,如前文所述,No-Steal 意味着对大事务运行不友好。
1.3.2 Undo/Redo 日志
如果在事务修改过程中同时记录修改前的旧值作为 Undo 日志(实现中并不一定采用日志形式),在宕机重启后,系统就拥有了回滚未提交事务的能力,这种做法称为 Undo/Redo 日志:
- 对每一次修改,产生日志同时记录旧值和新值;
- 未提交事务允许落盘,在修改落盘之前,对应的日志记录必须先落盘(Steal);
- 事务提交成功前,事务的所有日志记录(非数据)必须先落盘 (No-Force);
大名鼎鼎的 Oracle 数据库就是采用这种模式,事务的每一次修改都会产生对应的 undo record(记录在 undo block 中)和 redo record,并且在刷脏页之前,保证脏页上对应的未落盘事务日志必须先落盘;在事务 commit 前,要保证事务的所有日志落盘完成。
?
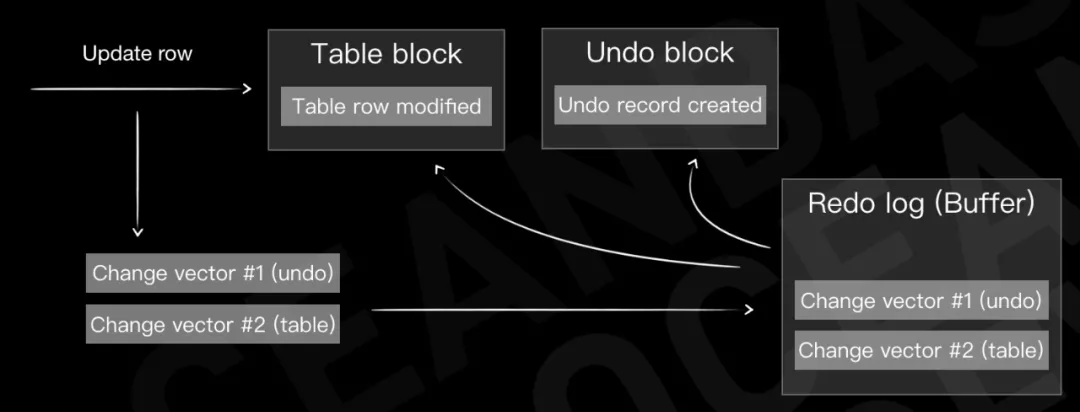
Undo/Redo 日志属于 Steal & No-Force 系统,目前绝大多数流行的关系数据库系统都采用了这样的思路,例如 Oracle、MySQL、PostgreSQL 等。
1.3.3 日志回收
任何基于日志的系统都会遇到日志回收的问题。虽然我们可以保留所有日志来满足事务故障恢复的需求,但是日志空间不能无限的膨胀下去,并且如果在宕机重启时总是从整个数据库的第一条日志开始重做,宕机恢复的速度也无法满足系统要求。因此,我们需要一种手段来尽可能的减少宕机恢复依赖的日志数量,这个手段就是Checkpoint。
一种最为简单的 Checkpoint 方法流程如下:
- 停止所有事务执行(暂停新开启事务并结束运行中的事务);
- 将当前内存中所有未落盘的修改落盘;
- 记录当前点为一次生效的 checkpoint;
- 恢复事务执行;
这个方法的正确性也很容易理解,因为在第二步之后,磁盘上已经有了完整的数据,不再需要任何日志。但这个方法的问题也很明显,就是要停止所有事务执行,这几乎是无法接受的。
有很多不同的 Checkpoint 方法可以避免这个问题,我们以 Oracle 中的 Media recovery checkpoint 举例,其过程为:
- 取当前 SCN(Redo point);
- 通知 dbwr 将当前所有脏页落盘;
- 完成后将 SCN 作为 checkpoint 点更新到元信息中;
?

整个过程中不影响正常事务的执行,其正确性的关键在于完成脏页落盘后,Redo point 前日志对应的修改都完全落盘了,不再需要依赖日志回放来进行故障恢复。
二、分布式数据库带来的问题
在分布式数据库中,事务故障恢复的目的仍然是要保证事务的原子性和持久性。和单机数据库的不同在于,在分布式数据库中,数据的修改位于不同的节点。
?
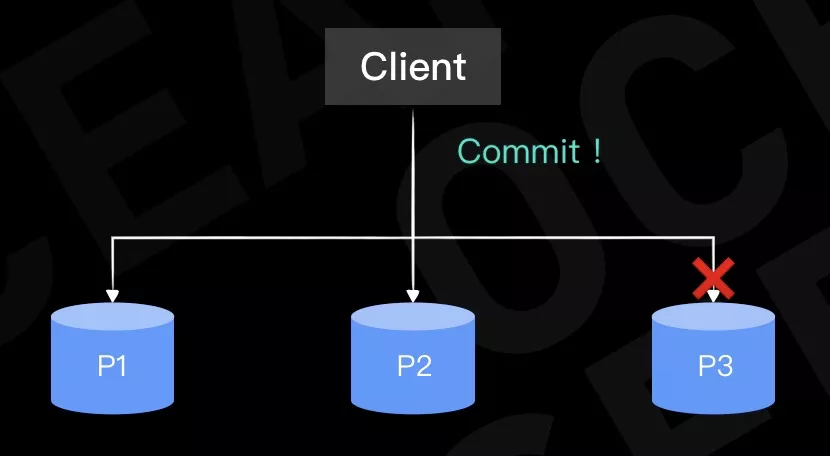
比如在这个例子中,事务的修改涉及到3个不同的节点,当事务要提交时,必须保证3个节点上的数据同时提交,而不能部分提交、部分回滚。
2.1 Saga
Saga 是1887年提出的一种把长事务拆小并保证整体事务原子性的方法,也可以用来解决分布式事务的问题。其核心思路是对每个子事务产生对应的“补偿事务”,当分布式事务整体提交时,依次提交各个节点上的子事务,如果过程中遭遇失败,则对已经提交的节点上的子事务执行补偿事务回滚已提交的修改。
?

如上图例中,事务在3个节点上各自产生一个子事务,在分布式事务提交时提交各个子事务,在第3个节点上提交子事务失败,需要对另外两个成功提交的子事务执行补偿事务完成回滚操作。
这种方法的优点在于正常提交流程处理简单,而缺点在于补偿回滚过程逻辑处理复杂。
2.2 两阶段提交
两阶段提交可能是最为知名的分布式事务原子性解决方案了。两阶段提交,顾名思义,整个事务提交流程分为两阶段来执行:
- Prepare:协调者通知参与者 Prepare,参与者写 Prepare 日志成功后回复协调者 Prepare ok;
- Commit:协调者收到所有参与者 Prepare 成功应答后通知参与者 Commit;
每个节点都需要将每个阶段的结果记录在持久化的日志中,用以恢复自身状态。
?

协议流程本身很简单,两阶段提交协议的核心在于协议应对宕机时的处理:当参与者发生宕机时,如果参与者还没有回复过协调者 Prepare ok,则协调者假定参与者决定回滚;当协调者发生宕机时,参与者会按照自己的状态决定下一步动作。
?

上图是两阶段提交参与者的状态机,如果参与者已经回复过 Prepare ok(处于 Prepared 状态),则参与者必须依赖协调者的消息通知才能决定最终事务状态,我们称参与者的这个状态为“事务未决”。如果此时协调者发生宕机,则两阶段提交流程会阻塞。这也是所有应用两阶段提交协议的系统所必须要解决的问题。
应用两阶段提交协议的系统很多,我们以 PG-XC 为例,PG-XC 的数据存储在不同的 Data Node 上,在分布式事务提交时,通过 Coordinator 执行两阶段提交协议保证多个 Data Node 上事务修改的原子性。
?

另外,近几年比较流行的 Percolator 协议,可以看做是两阶段提交协议的变种(Percolator 包含了一套完整的分布式事务解决方案,本文聚焦在其中事务原子性的部分)。Percolator 是 Google 提出的,在仅支持行级事务的Bigtable 基础上将单行事务“组合”成多行事务的方案。
当多行事务发起提交时:
- 选定其中一行作为"Primary record",将该行写入到 Bigtable 中,Primary record 上会记录整个事务的状态,此时为未提交状态;
- 将其他行作为“Secondary record”分别写入到 Bigtable 中,其中都包含了 Primary record 的位置信息,通过查询 Primary record 上的事务状态来决定自身状态;
- 修改 Primary record 上的事务状态为已提交;
- 异步清理 Secondary record 上的状态;
?

从两阶段提交协议的角度分析 Percolator,其每行上的事务都是整个分布式事务的参与者,Primary record 相当于协调者,当所有参与者都持久化成功后,修改 Primary record 上事务状态的过程也就等价于协调者写的 commit 日志。
三、OceanBase 事务故障恢复
OceanBase 采用 share-nothing 架构,数据按照分片规则分布在各个节点上,每个节点均有自己的存储引擎,各自管理不同的数据分区,每个分区通过 Paxos 同步日志实现高可用,当事务操作一个单独的数据分片时,执行的是单机事务,当事务操作不同数据分片时,执行的是分布式事务,会遇到分布式事务的原子性问题。
3.1 单机事务故障恢复
OceanBase 采用基于 MVCC 的事务并发控制,这意味着事务修改会保留多个数据版本,并且单个数据分片上的存储引擎基于 LSM-tree 结构,会定期进行转储(compaction)操作。
如下图所示,事务的修改会以新版本数据的形式写入到内存中最新的活跃 memtable 上,当 memtable 内存使用达到一定量时,memtable 冻结并生成新的活跃 memtable,被冻结的 memtable 会执行转储转变为磁盘上的 sstable。数据的读取通过读取所有的 sstable 和 memtable 上的多版本进行合并来得到所需要的版本数据。
?

单机事务故障恢复采用了 Undo/Redo 日志的思路实现。事务在写入时会生成 Redo 日志,借助 MVCC 机制的旧版本数据作为 Undo 信息,实现了 Steal & No-Force 的数据落盘策略。在事务宕机恢复过程中,通过 Redo日志进行重做恢复出已提交未落盘的事务,并通过恢复保存的旧版本数据来回滚已经落盘的未提交事务修改。
3.2 分布式事务故障恢复
当事务操作多个数据分片时,OceanBase 通过两阶段提交来保证分布式事务的原子性。
?

如上图所示,当分布式事务提交时,会选择其中的一个数据分片作为协调者在所有数据分片上执行两阶段提交协议。还记得前文提到过的协调者宕机问题么?在 OceanBase 中,由于所有数据分片都是通过 Paxos 复制日志实现多副本高可用的,当主副本发生宕机后,会由同一数据分片的备副本转换为新的主副本继续提供服务,所以可以认为在 OceanBase 中,参与者和协调者都是保证高可用不宕机的(多数派存活),绕开了协调者宕机的问题。
在参与者高可用的实现前提下,OceanBase 对协调者进行了“无状态”的优化。在标准的两阶段提交中,协调者要通过记录日志的方法持久化自己的状态,否则如果协调者和参与者同时宕机,协调者恢复后可能会导致事务提交状态不一致。但是如果我们认为参与者不会宕机,那么协调者并不需要写日志记录自己的状态。
?
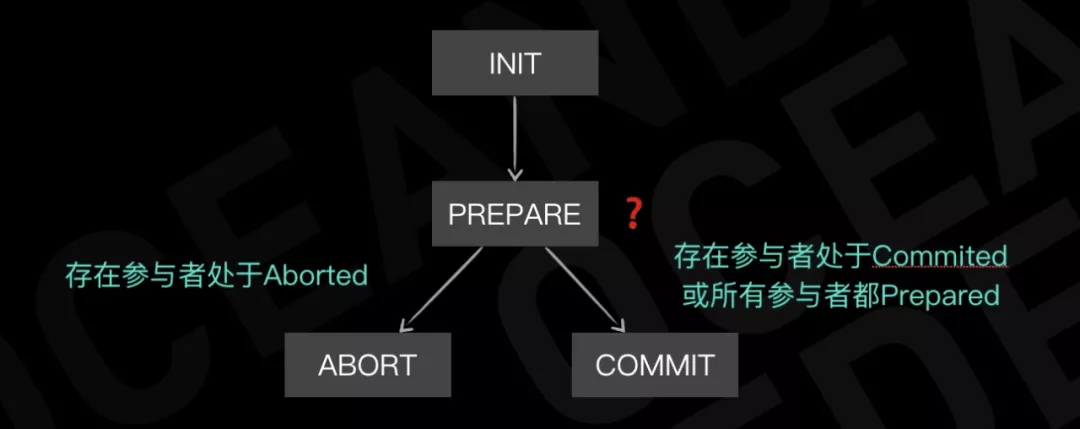
上图是两阶段提交协议协调者的状态机,在协调者不写日志的前提下,协调者如果发生切主或宕机恢复,它并不知道自己之前的状态是 Abort 还是 Commit。那么,协调者可以通过询问参与者来恢复自己的状态,因为参与者是高可用的,所以一定可以恢复出整个分布式事务的状态。
除此之外,OceanBase 还对两阶段提交协议的时延进行了优化,将事务提交回应客户端的时机提前到 Prepare 阶段完成后(标准两阶段提交协议中为 Commit 阶段完成后)。
?
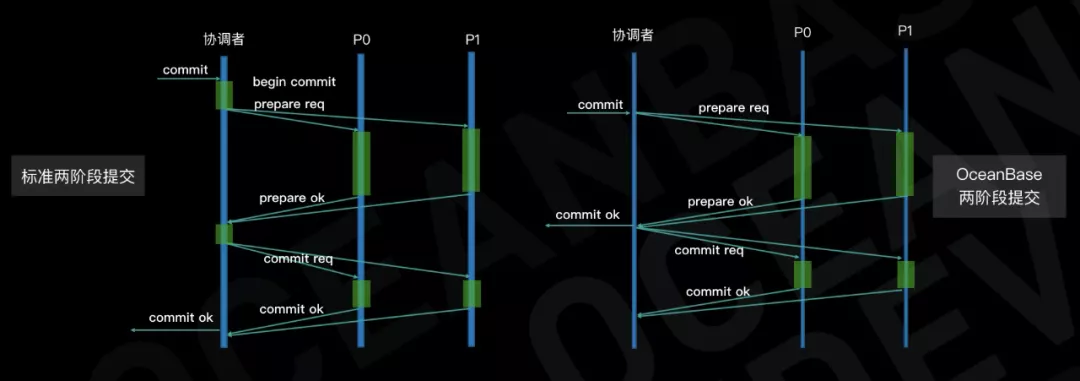
在上图中(绿色部分表示写日志的动作),左侧为标准两阶段提交协议,用户感知到的提交时延是4次写日志耗时以及2次 RPC 的往返耗时;右侧图中 OceanBase 的两阶段提交实现,由于少了协调者的写日志耗时以及提前了应答客户端的时机,用户感知到的提交时延是1次写日志耗时以及1次 RPC 的往返耗时。
四、总结
关系数据库领域虽然历史悠久,但是仍然充满了活力。这些年来,随着硬件的发展,新的技术和思路也不断的涌现出来,从本文描述的单机数据库到分布式数据库中事务故障恢复的的方案,相信大家也都能感受到这些年来数据库技术的发展是如何一步步适应着硬件的发展趋势。未来又会怎样?更大的内存、更快速的网络、更廉价的硬盘、甚至是非易失性内存的普及,这些变化会给数据库技术带来怎样的可能性?让我们一起拭目以待。(迫不及待的同学,欢迎加入 OceanBase 团队,一起创造数据库技术的未来!)
?
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!