网络通信-Linux 对网络通信的实现
2023-12-27 01:44:29
Linux 网络 IO 模型
同步和异步,阻塞和非阻塞
同步和异步
关注的是调用方是否主动获取结果
????????
同步:同步的意思就是调用方需要主动等待结果的返回
????????异步:异步的意思就是不需要主动等待结果的返回,而是通过其他手段比如,状态通知,
回调函数等。
阻塞和非阻塞
主要关注的是等待结果返回调用方的状态
??????
??阻塞:是指结果返回之前,当前线程被挂起,不做任何事
????????非阻塞:是指结果在返回之前,线程可以做一些其他事,不会被挂起。
两者的组合
????????1
.同步阻塞:同步阻塞基本也是编程中最常见的模型,打个比方你去商店买衣服,你去了
之后发现衣服卖完了,那你就在店里面一直等,期间不做任何事(包括看手机),等着商家进
货,直到有货为止,这个效率很低。
????????2.同步非阻塞:同步非阻塞在编程中可以抽象为一个轮询模式,你去了商店之后,发现衣
服卖完了,这个时候不需要傻傻的等着,你可以去其他地方比如奶茶店,买杯水,但是你还
是需要时不时的去商店问老板新衣服到了吗。
????????3.异步阻塞:异步阻塞这个编程里面用的较少,有点类似你写了个线程池,submit 然后马
上 future.get(),这样线程其实还是挂起的。有点像你去商店买衣服,这个时候发现衣服没有
了,这个时候你就给老板留给电话,说衣服到了就给我打电话,然后你就守着这个电话,一
直等着他响什么事也不做。这样感觉的确有点傻,所以这个模式用得比较少。
????????4.异步非阻塞:异步非阻塞。好比你去商店买衣服,衣服没了,你只需要给老板说这是我
的电话,衣服到了就打。然后你就随心所欲的去玩,也不用操心衣服什么时候到,衣服一到,
电话一响就可以去买衣服了
Linux 下的五种 I/O 模型

????????总的来说,
阻塞 IO 就是 JDK 里的 BIO 编程,IO 复用就是 JDK 里的 NIO 编程,Linux 下异
步 IO 的实现建立在 epoll 之上,是个伪异步实现,而且相比 IO 复用,没有体现出性能优势,
使用不广。
非阻塞 IO 使用轮询模式,会不断检测是否有数据到达,大量的占用 CPU 的时间,
是绝不被推荐的模型。信号驱动 IO 需要在网络通信时额外安装信号处理函数,使用也不广。
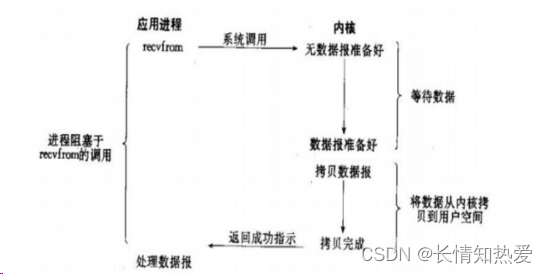
?阻塞 IO 模型

?I/O 复用模型
????????比较上面两张图,IO
复用需要使用两个系统调用
(select
和
recvfrom)
,而
blocking IO
只
调用了一个系统调用
(recvfrom)
。但是,用
select
的优势在于它可以同时处理多个
connection
。
所以,如果处理的连接数不是很高的话,使用
select/epoll
的
web server
不一定比使用
multi-threading + blocking IO
的
web server
性能更好,可能延迟还更大。
select/epoll
的优势
并不是对于单个连接能处理得更快,而是在于能处理更多的连接。
从
Linux
代码结构看网络通信
?
????????
Linux 内核的源码包含的东西很多,在 Linux 的源代码中,网络设备驱动对应的逻辑位于
driver/net/ethernet, 其中 intel 系列网卡的驱动在 driver/net/ethernet/intel 目录下。
协议栈模
块代码位于
kernel
和
net
目录。
????????其中 net
目录中包含
Linux
内核的网络协议栈的代码。子目录
ipv4
和
ipv6
为
TCP/IP
协议
栈的
IPv4
和
IPv6
的实现,主要包含了
TCP
、
UDP
、
IP
协议的代码,还有
ARP
协议、
ICMP
协
议、
IGMP
协议代码实现,以及如
proc
、
ioctl
等控制相关的代码。
????????站在网络通信的角度,源代码组织的表现形式如下:

????????网络协议栈是由若干个层组成的,网络数据的流程主要是指在协议栈的各个层之间的传递。
一个
TCP
服务器的流程按照建立
socket()
函数,绑定地址端口
bind()
函数,侦听端口
listen()
函数,接收连接
accept()
函数,发送数据
send()
函数,接收数据
recv()
函数,关闭
socket()
函
数的顺序来进行。
????????与此对应内核的处理过程也是按照此顺序进行的,网络数据在内核中的处理过程主要是在
网卡和协议栈之间进行
:
从网卡接收数据,交给协议栈处理
;
协议栈将需要发送的数据通过网
络发出去。
????????由下图中可以看出,数据的流向主要有两种。应用层输出数据时,数据按照自上而下的顺
序,依次通过应用
API
层、协议层和接口层
;
当有数据到达的时候,自下而上依次通过接口
层、协议层和应用
API
层的方式,在内核层传递。
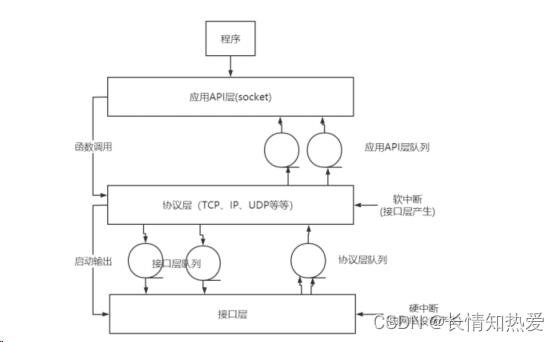
????????应用层 Socket
的初始化、绑定
(bind)
和销毁是通过调用内核层的
socket()
函数进行资源的申
请和销毁的。
????????发送数据的时候,将数据由应用 API
层传递给协议层,协议层在
UDP
层添加
UDP
的首部、
TCP
层添加
TCP
的首部、
IP
层添加
IP
的首部,接口层的网卡则添加以太网相关的信息后,
通过网卡的发送程序发送到网络上。
????????接收数据的过程是一个相反的过程,当有数据到来的时候,网卡的中断处理程序将数据从
以太网网卡的
FIFO
对列中接收到内核
,
传递给协议层
,
协议层在
IP
层剥离
IP
的首部、
UDP
层
剥离
UDP
的首部、
TCP
层剥离
TCP
的首部后传递给应用
API
层,应用
API
层查询
socket
的
标识后,将数据送给用户层匹配的
socket
。
????????在 Linux
内核实现中,链路层协议靠网卡驱动来实现,内核协议栈来实现网络层和传输层。
内核对更上层的应用层提供
socket
接口来供用户进程访问。
?
Linux 下的 IO 复用编程
????????select,
poll
,
epoll
都是
IO
多路复用的机制。
I/O
多路复用就是通过一种机制,一个进
程可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知程序
进行相应的读写操作。但
select
,
poll
,
epoll
本质上都是同步
I/O
,因为他们都需要在读写事
件就绪后自己负责进行读写,并等待读写完成。
文件描述符 FD
????????在 Linux
操作系统中,可以将一切都看作是文件,包括普通文件,目录文件,字符设备
文件(如键盘,鼠标…),块设备文件(如硬盘,光驱…),套接字等等,所有一切均抽象
成文件,提供了统一的接口,方便应用程序调用。
既然在
Linux
操作系统中,你将一切都抽象为了文件,那么对于一个打开的文件,我应
用程序怎么对应上呢?文件描述符应运而生。
???
?????文件描述符
:
File descriptor,简称 fd,当应用程序请求内核打开/新建一个文件时,内核
会返回一个文件描述符用于对应这个打开/新建的文件,其 fd 本质上就是一个非负整数。
实
际上,它是一个索引值,指向内核为每一个进程所维护的该进程打开文件的记录表。当程序
打开一个现有文件或者创建一个新文件时,内核向进程返回一个文件描述符。在程序设计中,
一些涉及底层的程序编写往往会围绕着文件描述符展开。但是文件描述符这一概念往往只适
用于
UNIX
、
Linux
这样的操作系统。
????????系统为了维护文件描述符建立了 3
个表:进程级的文件描述符表、系统级的文件描述符
表、文件系统的 i-node 表
。所谓进程级的文件描述符表,指操作系统为每一个进程维护了
一个文件描述符表,该表的索引值都从从
0
开始的,所以在不同的进程中可以看到相同的文
件描述符,这种情况下相同的文件描述符可能指向同一个实际文件,也可能指向不同的实际
文件
select
int select (int n, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval*timeout);
????????select 函数监视的文件描述符分
3
类,
分别是 writefds、readfds、和 exceptfds
。调用后
select
函数会阻塞,直到有描述副就绪(有数据 可读、可写、或者有
except
),或者超时
(
timeout
指定等待时间,如果立即返回设为
null
即可),函数返回。当
select
函数返回后,
可以 通过遍历
fdset
,来找到就绪的描述符。
????????select 目前几乎在所有的平台上支持,其良好跨平台支持也是它的一个优点。
select
的
一 个缺点在于单个进程能够监视的文件描述符的数量存在最大限制,在
Linux
上一般为
1024
,
可以通过修改宏定义甚至重新编译内核的方式提升这一限制,但是这样也会造成效率的降低。
poll
int poll (struct pollfd *fds, unsigned int nfds, int timeout);
????????
不同与 select 使用三个位图来表示三个 fdset 的方式,poll 使用一个 pollfd 的指针实现。
pollfd 结构包含了要监视的 event 和发生的 event,不再使用 select“参数-值”传递的方
式
。同时,
pollfd
并没有最大数量限制(但是数量过大后性能也是会下降)。 和
select
函数
一样,
poll
返回后,需要轮询
pollfd
来获取就绪的描述符。
epoll
????????
epoll 是在 2.6 内核中提出的,是之前的 select 和 poll 的增强版本
。相对于
select
和
poll
来说,可以看到
epoll
做了更细致的分解,包含了三个方法,使用上更加灵活。
int epoll_create(int size) ;int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event) ;int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout);
int epoll_create(int size);
????????创建一个 epoll
的句柄,
size
用来告诉内核这个监听的数目一共有多大,这个参数不同
于
select()
中的第一个参数,给出最大监听的
fd+1
的值,参数
size
并不是限制了
epoll
所能
监听的描述符最大个数,只是对内核初始分配内部数据结构的一个建议。当创建好
epoll
句
柄后,它就会占用一个
fd
值,在
linux
下如果查看
/proc/
进程
id/fd/
,是能够看到这个
fd
的,
所以在使用完
epoll
后,必须调用
close()
关闭,否则可能导致
fd
被耗尽。
作为类比,可以理解为对应于
JDK NIO
编程里的
selector = Selector.open();
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
函数是对指定描述符
fd
执行
op
操作。
????????epfd:是
epoll_create()
的返回值。
????????op:表示
op
操作,用三个宏来表示:添加
EPOLL_CTL_ADD
,删除
EPOLL_CTL_DEL
,修
改
EPOLL_CTL_MOD
。分别添加、删除和修改对
fd
的监听事件。
????????fd:是需要监听的
fd
(文件描述符)
????????epoll_event:是告诉内核需要监听什么事,有具体的宏可以使用,比如
EPOLLIN
:表示
对应的文件描述符可以读(包括对端
SOCKET
正常关闭);
EPOLLOUT
:表示对应的文件描述
符可以写;
????????作为类比,可以理解为对应于 JDK NIO
编程里的
socketChannel.register();
int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout);
????????等待 epfd
上的
io
事件,最多返回
maxevents
个事件。
????????参数 events
用来从内核得到事件的集合,
maxevents
告之内核这个
events
有多大,这 个 maxevents
的值不能大于创建
epoll_create()
时的
size
,参数
timeout
是超时时间(毫秒,
0
会立即返回,
-1
将不确定,也有说法说是永久阻塞)。该函数返回需要处理的事件数目,
如返回
0
表示已超时。
????????作为类比,可以理解为对应于 JDK NIO
编程里的
selector.select();
select、poll、epoll 的比较
????????select,
poll
,
epoll
都是 操作系统实现
IO
多路复用的机制。 我们知道,
I/O
多路复用
就通过一种机制,可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或者写就绪),
能够通知程序进行相应的读写操作。那么这三种机制有什么区别呢。
1
、支持一个进程所能打开的最大连接数
文章来源:https://blog.csdn.net/weixin_43874650/article/details/135231809
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!