基于GPT-2的新闻文本生成——News Creator,使用MindSpore实现
基于GPT-2的新闻本文生成——News Creator
基于GPT-2的新闻本文生成项目——News Creator,是一个创新的自然语言处理项目,使用GPT-2作为核心模型,并结合专为新闻内容设计的AG news数据集进行深度微调。项目通过LoRA技术进一步提升了模型在特定新闻文本生成任务上的表现,有效地结合了模型的泛化能力与任务特异性,使其更加适合于高效、高质量的新闻文章生成。
注:本项目使用MindSpore框架或MindFormer库完成模型的训练和开发。
代码链接:https://xihe.mindspore.cn/projects/guojialiang/GPT-2_news
或者
百度网盘:https://pan.baidu.com/s/1-wQO7pppwZSXlGmkSaOXSw?pwd=xn3u
1. mindformer安装
-
方式1:Linux源码编译安装
支持源码编译安装,用户可以执行下述的命令进行包的安装
git clone -b dev https://gitee.com/mindspore/mindformers.git cd mindformers bash build.sh -
方式2:镜像
docker下载命令
docker pull swr.cn-central-221.ovaijisuan.com/mindformers/mindformers0.8.0_mindspore2.2.0:aarch_20231025创建容器
# --device用于控制指定容器的运行NPU卡号和范围 # -v 用于映射容器外的目录 # --name 用于自定义容器名称 docker run -it -u root \ --ipc=host \ --network host \ --device=/dev/davinci0 \ --device=/dev/davinci1 \ --device=/dev/davinci2 \ --device=/dev/davinci3 \ --device=/dev/davinci4 \ --device=/dev/davinci5 \ --device=/dev/davinci6 \ --device=/dev/davinci7 \ --device=/dev/davinci_manager \ --device=/dev/devmm_svm \ --device=/dev/hisi_hdc \ -v /etc/localtime:/etc/localtime \ -v /usr/local/Ascend/driver:/usr/local/Ascend/driver \ -v /var/log/npu/:/usr/slog \ -v /usr/local/bin/npu-smi:/usr/local/bin/npu-smi \ --name {请手动输入容器名称} \ swr.cn-central-221.ovaijisuan.com/mindformers/mindformers0.8.0_mindspore2.2.0:aarch_20231025 \ /bin/bash -
版本对应关系
需要根据Mindspore版本选择对应的mindformer版本
MindFormers MindPet MindSpore Python CANN 驱动固件 镜像链接 备注 dev 1.0.2 master 3.9 / / / 开发分支(非稳定版本) dev 1.0.2 2.2.0 3.9 7.0.RC.beta1: aarch64 x86_64 固件驱动获取链接 / 开发分支(非稳定版本) 0.8 1.0.2 2.2.1 3.9 / / / 发布版本分支 0.8 1.0.2 2.2.0 3.9 7.0.RC.beta1: aarch64 x86_64 固件驱动获取链接 物理机 AICC 发布版本分支 0.7 1.0.1 2.1.1 3.9 6.3.RC2.alpha005: aarch64 x86_64 固件驱动获取链接 / 旧版本分支
2. News Creator平台的使用
-
新闻文本生成
首先cd到GPT-2_news文件夹中,运行web.py
cd GPT-2_news python web.py打开生成的网址,效果如下:

输入需要的新闻标题,点击submit。(注意:目前模型是英语数据集训练的,需要输入英文标题。)结果如下:
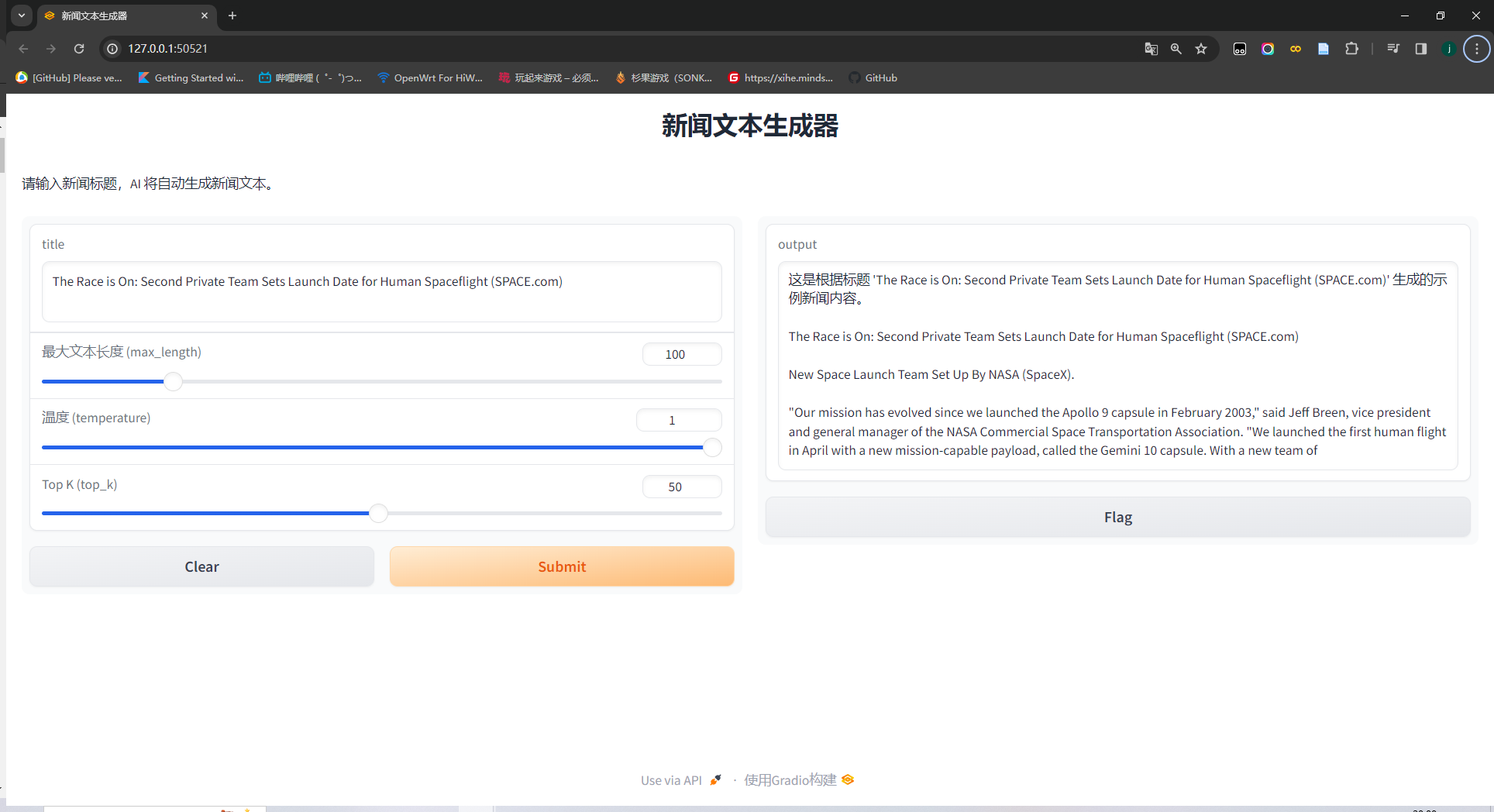
-
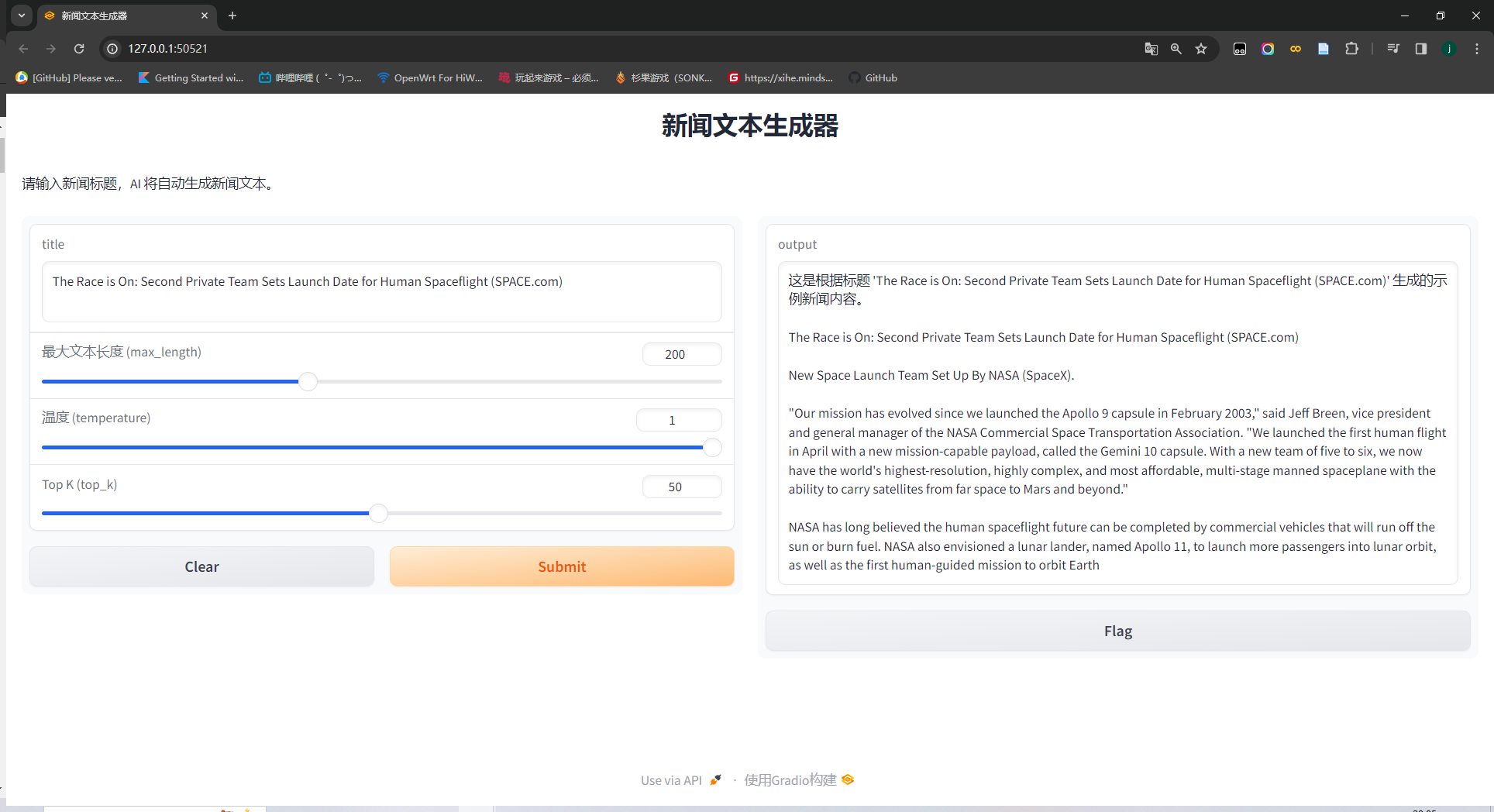
参数选择
平台提供三种参数可调整,用于调整模型输出的长度和质量。
- 最大文本长度:控制新闻文本生成的最大长度
- 温度:温度是一个正实数,通常设置在 0 到 1 之间。它用于调整模型在生成文本时的确定性和随机性。当温度接近于 0 时(例如 0.1 或更低),模型倾向于生成非常确定性的文本。在这种情况下,模型几乎总是选择最有可能的下一个单词,这会导致生成的文本非常一致和可预测,但可能缺乏创造性和多样性。当温度设置为 1 时,模型生成文本时会根据每个单词的概率分布进行选择。这意味着较高概率的单词更可能被选择,但也为较不常见的单词留下了空间。
- Top_K:
top_k采样是一种文本生成策略,其中每次模型选择下一个单词时,只考虑概率最高的前 k 个单词。这个 k 值就是top_k的值。
3. 微调模型
-
生成mindrecord数据集
本项目中使用的AGnews数据集。
- 数据集通常包含训练集和测试集。训练集大约包含 120,000 个样本,测试集大约包含 7,600 个样本。
- 每个样本都包括一个新闻标题和一个新闻描述,以及相应的类别标签(世界、体育、商业或科技)。
使用如下代码进行mindrecord格式数据集生成
python data_process.py --input_file train.csv路径 --output_file 输出路径 --max_length 1025 -
微调模型
安装mindformer后,cd到mindspores文件夹下:
cd mindformers在config/gpt2/run_gpt2_lora.yaml中配置batch_size、epochs、训练集路径等参数
使用如下命令进行微调:
python run_mindformer.py --config configs/gpt2/run_gpt2_lora.yaml --run_mode finetune -
查看效果
使用下面的命令查看效果
python run_mindformer.py --config configs/gpt2/run_gpt2.yaml --run_mode predict --use_parallel False --predict_data 输入新闻标题也可以使用GPT-2_news中的generate.py进行推理
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!