NLP项目实战01--电影评论分类
介绍:
欢迎来到本篇文章!在这里,我们将探讨一个常见而重要的自然语言处理任务——文本分类。具体而言,我们将关注情感分析任务,即通过分析电影评论的情感来判断评论是正面的、负面的。
展示:
训练展示如下:
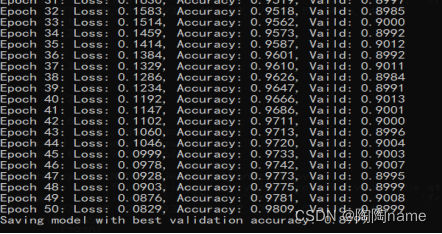
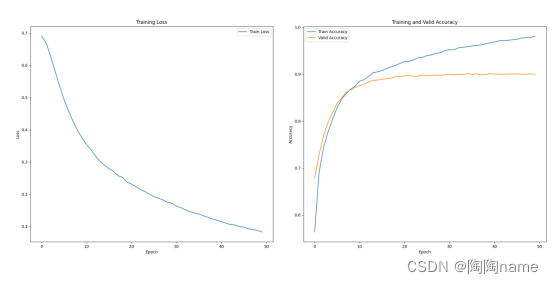
实际使用如下:
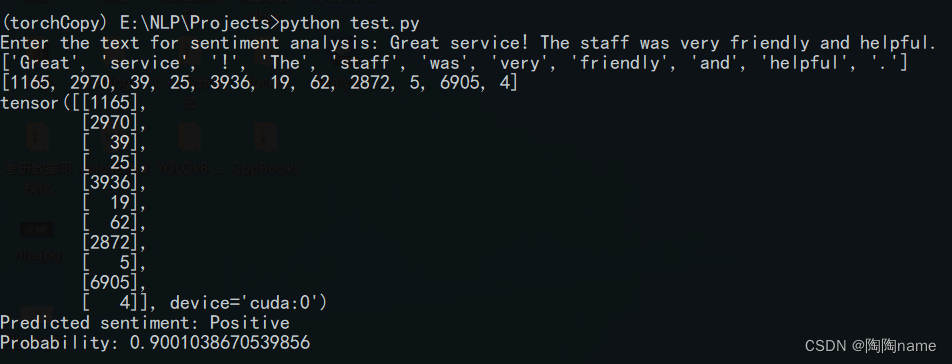
实现方式:
选择PyTorch作为深度学习框架,使用电影评论IMDB数据集,并结合torchtext对数据进行预处理。
环境:
Windows+Anaconda
重要库版本信息
torch==1.8.2+cu102
torchaudio==0.8.2
torchdata==0.7.1
torchtext==0.9.2
torchvision==0.9.2+cu102
实现思路:
1、数据集
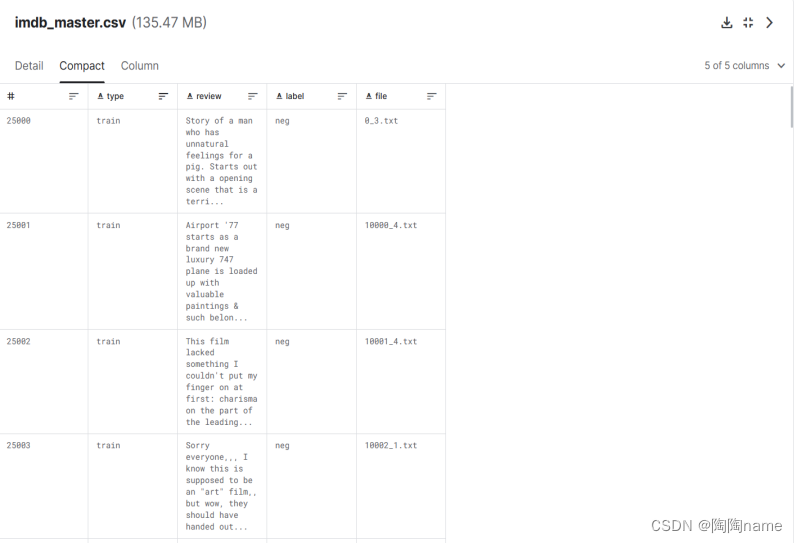
本次使用的是IMDB数据集,IMDB是一个含有50000条关于电影评论的数据集
数据如下:
2、数据加载与预处理
使用torchtext加载IMDB数据集,并对数据集进行划分
具体划分如下:
TEXT = data.Field(tokenize='spacy', tokenizer_language='en_core_web_sm')
LABEL = data.LabelField(dtype=torch.float)
# Load the IMDB dataset
train_data, test_data = datasets.IMDB.splits(TEXT, LABEL)
创建一个 Field 对象,用于处理文本数据。同时使用spacy分词器对文本进行分词,由于IMDB是英文的,所以使用en_core_web_sm语言模型。
创建一个 LabelField 对象,用于处理标签数据。设置dtype 参数为 torch.float,表示标签的数据类型为浮点型。
使用 datasets.IMDB.splits 方法加载 IMDB 数据集,并将文本字段 TEXT 和标签字段 LABEL 传递给该方法。返回的 train_data 和 test_data 包含了 IMDB 数据集的训练和测试部分。
下面是train_data的输出

3、构建词汇表与加载预训练词向量
TEXT.build_vocab(train_data,max_size=25000,vectors="glove.6B.100d",unk_init=torch.Tensor.normal_)
LABEL.build_vocab(train_data)
train_data:表示使用train_data中数据构建词汇表
max_size:限制词汇表的大小为 25000
vectors=“glove.6B.100d”:表示使用预训练的 GloVe 词向量,其中 “glove.6B.100d” 指的是包含 100 维向量的 6B 版 GloVe。
unk_init=torch.Tensor.normal_ :表示指定未知单词(UNK)的初始化方式,这里使用正态分布进行初始化。
LABEL.build_vocab(train_data):表示对标签进行类似的操作,构建标签的词汇表
train_iterator, valid_iterator, test_iterator = data.BucketIterator.splits( (train_data, valid_data, test_data), batch_size=BATCH_SIZE, device=device)
使用data.BucketIterator.splits 来创建数据加载器,包括训练、验证和测试集的迭代器。这将确保你能够方便地以批量的形式获取数据进行训练和评估。
4、定义神经网络
这里的网络定义比较简单,主要采用在词嵌入层(embedding)后接一个全连接层的方式完成对文本数据的分类。
具体如下:
class NetWork(nn.Module):
def __init__(self,vocab_size,embedding_dim,output_dim,pad_idx):
super(NetWork,self).__init__()
self.embedding = nn.Embedding(vocab_size,embedding_dim,padding_idx=pad_idx)
self.fc = nn.Linear(embedding_dim,output_dim)
self.dropout = nn.Dropout(0.5)
self.relu = nn.ReLU()
def forward(self,x):
embedded = self.embedding(x)
embedded = embedded.permute(1,0,2)
pooled = F.avg_pool2d(embedded, (embedded.shape[1], 1)).squeeze(1)
pooled = self.relu(pooled)
pooled = self.dropout(pooled)
output = self.fc(pooled)
return output
5、模型初始化
vocab_size = len(TEXT.vocab)
embedding_dim = 100
output = 1
pad_idx = TEXT.vocab.stoi[TEXT.pad_token]
model = NetWork(vocab_size,embedding_dim,output,pad_idx)
pretrained_embeddings = TEXT.vocab.vectors
model.embedding.weight.data.copy_(pretrained_embeddings)
定义模型的超参数,包括词汇表大小(vocab_size)、词向量维度(embedding_dim)、输出维度(output,在这个任务中是1,因为是二元分类,所以使用1),以及 PAD 标记的索引(pad_idx)
之后需要将预训练的词向量加载到嵌入层的权重中。TEXT.vocab.vectors 包含了词汇表中每个单词的预训练词向量,然后通过 copy_ 方法将这些词向量复制到模型的嵌入层权重中对网络进行初始化。这样做确保了模型的初始化状态良好。
6、训练模型
total_loss = 0
train_acc = 0
model.train()
for batch in train_iterator:
optimizer.zero_grad()
preds = model(batch.text).squeeze(1)
loss = criterion(preds,batch.label)
total_loss += loss.item()
batch_acc = (torch.round(torch.sigmoid(preds)) == batch.label).sum().item()
train_acc += batch_acc
loss.backward()
optimizer.step()
average_loss = total_loss / len(train_iterator)
train_acc /= len(train_iterator.dataset)
optimizer.zero_grad():表示将模型参数的梯度清零,以准备接收新的梯度。
preds = model(batch.text).squeeze(1):表示一次前向传播的过程,由于model输出的是torch.tensor(batch_size,1)所以使用squeeze(1)给其中的1维度数据去除,以匹配标签张量的形状
criterion(preds,batch.label):定义的损失函数 criterion 计算预测值 preds 与真实标签 batch.label 之间的损失
(torch.round(torch.sigmoid(preds)) == batch.label).sum().item():
通过比较模型的预测值与真实标签,计算当前批次的准确率,并将其累加到 train_acc 中
后面的就是进行反向传播更新参数,还有就是计算loss和train_acc的值了
7、模型评估:
model.eval()
valid_loss = 0
valid_acc = 0
best_valid_acc = 0
with torch.no_grad():
for batch in valid_iterator:
preds = model(batch.text).squeeze(1)
loss = criterion(preds,batch.label)
valid_loss += loss.item()
batch_acc = ((torch.round(torch.sigmoid(preds)) == batch.label).sum().item())
valid_acc += batch_acc
和训练模型的类似,这里就不解释了
8、保存模型
这里一共使用了两种保存模型的方式:
torch.save(model, "model.pth")
torch.save(model.state_dict(),"model.pth")
第一种方式叫做模型的全量保存
第二种方式叫做模型的参数保存
全量保存是保存了整个模型,包括模型的结构、参数、优化器状态等信息
参数量保存是保存了模型的参数(state_dict),不包括模型的结构
9、测试模型
测试模型的基本思路:
加载训练保存的模型、对待推理的文本进行预处理、将文本数据加载给模型进行推理
加载模型:
saved_model_path = "model.pth"
saved_model = torch.load(saved_model_path)
输入文本:
input_text = “Great service! The staff was very friendly and helpful.”
文本进行处理:
tokenizer = get_tokenizer("spacy", language="en_core_web_sm")
tokenized_text = tokenizer(input_text)
indexed_text = [TEXT.vocab.stoi[token] for token in tokenized_text]
tensor_text = torch.LongTensor(indexed_text).unsqueeze(1).to(device)
模型推理:
saved_model.eval()
with torch.no_grad():
output = saved_model(tensor_text).squeeze(1)
prediction = torch.round(torch.sigmoid(output)).item()
probability = torch.sigmoid(output).item()
由于笔者能力有限,所以在描述的过程中难免会有不准确的地方,还请多多包含!
更多NLP和CV文章以及完整代码请到"陶陶name"获取。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!