搜索Agent方案
为啥需要整体方案,直接调用搜索接口取Top1返回不成嘛?要是果真如此Simple&Naive,New Bing岂不是很容易复刻->.->
我们先来看个例子,前一阵火爆全网的常温超导技术,如果想回答LK99哪些板块会涨,你会得到以下搜索答案
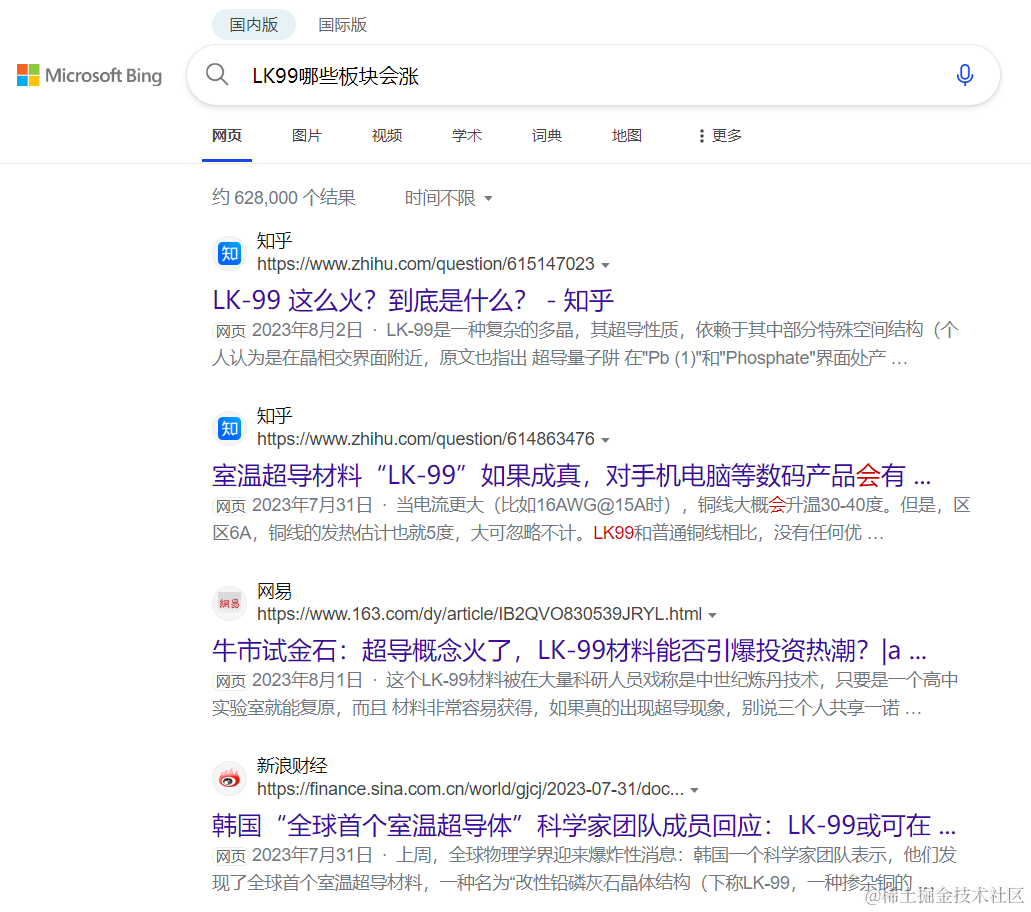
从以上的搜索结果不难发现,Top1答案并不能回答问题,在和搜索引擎交互中几个可能的问题有
-
Query:用户的query不适配搜索引擎,导致搜索不到有效内容;或者问题需要通过类似Self Ask的思维链拆解通过多轮搜索来解决
-
Ranking:细看langchain的搜索Wrapper,会发现它默认只使用搜索的Top1返回,但是除了传统百科问题,这类问题因为做过优化,Top1往往是最优答案。但其他场景,例如当前问题,第三个内容显然更合适。当前传统搜索引擎并非为大模型使用设计,因此需要后接一些优化排序模块,例如REPLUG论文
-
Snippet: Bing的网页标题下面会默认展示150字左右根据query定位的正文摘要内容,也是langchain等框架使用的网页结果。但是不难发现,snippet太短或者定位不准会导致snippet缺乏有效信息
为了解决上述提到的3个主要问题,我们会基于WebGPT,WebGLM,WebCPM的3篇论文,详述如何更有效的和搜索引擎进行交互,来解决长文本开放问答LFQA问题。和搜索引擎的交互主要分成以下4个模块
-
Search:生成搜索请求query,或基于结果进行query改写,请求搜索API。类似self-Ask里面的Thought,只不过selfask强调问题拆解,而这里的search还有query改写,追问等功能
-
Retrieve:从搜索返回的大段内容中,定位可以回答query的支撑性事实,进行抽取式摘要、生成式摘要。类似React里面的LookUp行为,只不过更加复杂不是简单的定位文字。
-
Synthesis: 对多个内容进行组装,输入模型进行推理得到答案
-
Action: 针对需要和搜索引擎进行自动化多轮交互的场景,需要预测下一步的行为,是继续搜索,抽取摘要,还是停止搜索,组装内容进行推理等等,对应LLM Agent中的规划模块。其实就是丰富了React/SelfAsk里面的Action,加入了更多和搜索引擎交互的行为,例如继续浏览,翻页等等
虽然论文的发布顺序是webcpm>webglm>webgpt,但考虑webcpm开源了很全面的中文数据哈哈,手动点赞!我会以webcpm作为基准详细介绍,再分别介绍webglm和webgpt的异同点。
webcpm
paper:WEBCPM: Interactive Web Search for Chinese Long-form Question Answering
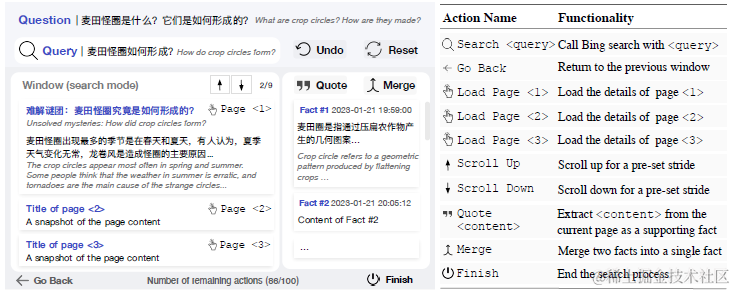
WebCPM其实是这三篇论文中最新的一篇,所以集成了webgpt和webglm的一些方案。构建了通过和搜索引擎进行多轮交互,来完成长文本开放问答(LFQA)的整体方案。它使用的搜索API是Bing。23名标注人员通过和搜索进行多轮交互,来获取回答问题所需的支撑性事实。
webCPM的问题来自Reddit上的英文QA转成中文。之所以使用Reddit而非知乎,百度知道,是因为后两者的答案往往经过很好的处理,直接搜索一轮就能获得很好的答案,降低了多轮搜索的交互难度。人工标注的搜索数据微调10B的CPM模型并在LFQA任务拿到了不错的效果。
WebCPM的整体框架就是上面提到的4个模块,下面我们来分别介绍。强烈建议和源码结合起来看,论文本身写的略简单,哈哈给读者留下了充分的想象空间。
Action:行为规划
首先是行为规划,也就是让模型学习人和搜索引擎交互生成的行为链路。webcpm针对交互式搜索问题,定义了包括搜索,页面加载,页面下滑等以下10个行为。不过个人感觉如果只从解决长文本问答出发,以下行为中的Scroll,load page等操作其实可能可以被优化掉,因为内容的遍历可以通过引入排序模块,和以上的摘要模块来筛选相关和不相关的内容,并不一定要通过Action来实现。这样可能可以进一步简化Action空间,提升效果。
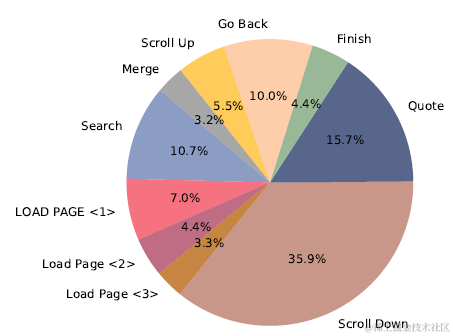
针对行为序列的建模,被抽象为文本分类问题。把当前状态转化为文本表述,预测下一步Action是以上10分类中的哪一个。当前状态的描述包括以下内容
-
最初的问题:question
-
当前的搜索query:title
-
历史Action序列拼接:last_few_actions,消融实验中证明历史Action序列是最重要的,哈哈所以可能可以简化成个HMM?
-
历史全部摘要内容拼接:quotes
-
上一步的搜索界面:past_view, 上一步页面中展示所有内容的标题和摘要拼接的文本
-
当前搜索界面:text, 当前页面中展示所有内容的标题和摘要拼接的文本
-
剩余Action步骤:actions_left
以下为指令样本的构建代码,就是把以上的状态拼接作为input,把下一步Action作为Output
def make_input(self, info_dict, type="action"):
? ?context_ids = ""
? ?def convert_nothing(info):
? ? ? ?return "无" if len(info) == 0 else info
?
? ?context_ids += "问题:\n" + info_dict["question"] + "\n"
? ?context_ids += "摘要:\n" + convert_nothing(info_dict["quotes"]) + "\n"
?
? ?last_few_actions = ""
? ?for past_action in info_dict["past_actions"]:
? ? ? ?if past_action != []:
? ? ? ? ? ?last_few_actions += past_action
?
? ?context_ids += "当前搜索:\n" + convert_nothing(info_dict["title"]) + "\n"
? ?context_ids += "上回界面:\n" + convert_nothing(info_dict["past_view"]) + "\n"
? ?context_ids += "当前界面:\n" + convert_nothing(info_dict["text"]) + "\n"
?
? ?context_ids += "剩余操作步数:" + str(info_dict["actions_left"]) + "\n"
?
? ?if type == "action":
? ? ? ?context_ids += "可选操作:"
? ? ? ?for idx, k in enumerate(self.action2idx):
? ? ? ? ? ?context_ids += self.action2idx[k]
? ? ? ? ? ?if idx != len(self.action2idx) - 1:
? ? ? ? ? ? ? ?context_ids += ";"
? ? ? ?context_ids += "\n"
?
? ?context_ids += "历史操作:" + convert_nothing(last_few_actions) + "\n"
?
? ?if type == "action":
? ? ? ?context_ids += "下一步操作:"
? ?elif type == "query":
? ? ? ?context_ids += "请生成新的合适的查询语句:"
? ?elif type == "abstract":
? ? ? ?context_ids += "请对当前界面内容摘取和问题相关的内容:"
?
? ?next_action = info_dict["next_action"]
? ?return context_ids, next_action具体分类模型的微调就没啥好说的了。不过这里需要提一下,源码中其实给出了两种webcpm的实现方案。两种方案均开源了数据。
-
Interactive方案:对应当前的行为建模,每一步执行什么行为会由Action模型预测得到,同时以下query改写,摘要等模块,也会获得之前所有执行步骤已有的上文输出,进行条件文本生成任务
-
pipeline方案:整体行为链路固定依次是,query改写 -> 所有改写query搜索得到Top-K内容 -> 针对每个页面进行摘要抽取 -> 整合所有内容回答问题。 因此Pipeline方案并不需要Action模型,同时以下的摘要改写等模块,也会简化为不依赖上文的文本生成任务
这么说有些抽象,让我们用Query改写来看下以上两种方案的差异,假设用户提问:网页布局都有哪种?一般都用什么布局?
-
Interactive:第一个改写query=网页布局种类, 然后搜索+摘要获得网页布局总结性的概述后,第二个query在已有摘要内容的基础上,改写query=网页布局最佳实践, 这样综合两个query的内容就可以回答上述问题
-
pipeline:在最初就调用query改写模型生成一堆改写query,例如网页布局种类,网页布局技巧,网页布局模式,网页布局优势。然后全部去调用搜索引擎,再对所有返回结果进行整合。
虽然看上去Interactive似乎能得到更优解,但其实只对明显串行的搜索任务有边际增益,整体没有pipeline模式更加简洁优雅。因为pipeline模型的无条件生成,使得每一步都可以并发处理,更容易落地。并且每个模块可以独立优化,可以相互解耦。因此以下三个模块的介绍,我们都以pipeline方案来进行介绍
Search:query改写
query改写模型,是一个seq2seq的文本生成模型。其实和Self-Ask通过自我提问,来对问题进行拆解的本质相似。改写核心是为了解决两个问题
-
Decompose:用户的问题由多个并联、串联的内容组合而成,因此需要对问题进行拆解,得到子query。例如Self-Ask那一章的例子,提问涨幅最高的板块成交量如何?需要拆解成涨幅最高的板块+XX板块成交量
-
Rephrase:用户的问题本身不适配搜索引擎,需要改写成更加简洁,关键词更明确的搜素query。例如"微软的new bing上线了,使用体验如何?"可以改写为"new bing使用体验"
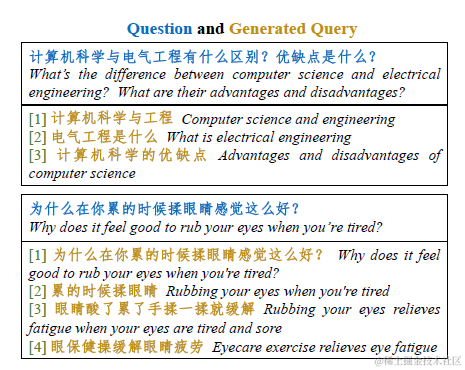
以下为webcpm微调得到的query生成模型的效果,webcpm提供了这部分训练数据,包括一个query和改写得到的多个query
Retriever:摘要抽取
Retriever负责从网页正文中,抽取和Query相关的内容,也就是一个阅读理解/抽取式摘要问题。这样就不需要依赖搜索API直接提供的snippet摘要,可以针对你的场景来设计抽取的长度,以及是整段抽取,还是抽取多个段落组合。
为了降低推理延时,webcpm通过decoder实现了类似span抽取的方案,解码器只解码应当抽取的段落的第一个字和最后一个字。例如
Query = 麦田怪圈是什么?
Content= 麦田怪圈(Crop Circle),是指在麦田或其它田地上,通过某种未知力量(大多数怪圈是人类所为)把农作物压平而产生出来的几何图案。这个神秘现象有时被人们称之为“Crop Formation”。麦田怪圈的出现给了对支持外星人存在论的人们多种看法。
假设应该抽取段落中的第一句话
Fact=麦田怪圈(Crop Circle),是指在麦田或其它田地上,通过某种未知力量(大多数怪圈是人类所为)把农作物压平而产生出来的几何图案
则模型的解码器输出的结果是起始字符:麦-结束字符:案,如果首尾两字能匹配到多端文本,则取最长能匹配到的文本段落。刨了刨代码,发现pipeline和interactive在摘要部分的样本构建方式不同,只有以下互动式的样本构建中采用了以上类span抽取的方案
abstract = "起始字符:" + self.tokenizer.decode(decoded_abstract[: num_start_end_tokens]) + "-结束字符:" + self.tokenizer.decode(decoded_abstract[-num_start_end_tokens: ])
Synthesis:信息聚合
Synthesis负责整合以上search+Retriever得到的多个Fact,拼接作为上文,通过人工标注的答案,来让模型学习如何基于多段事实生成一致,流畅,基于上文内容的长回答。
为了解决模型本身在自动检索过程中会收集到无关信息,而[1]中提到,无关的上文输入会影响推理结果的问题。Webcpm在构建基于多段上文的QA问答指令集时,在人工收集的每个query对应的多个摘要fact的基础上,会从其他样本中随机采样同等量级的无关上文,和原始的事实进行shuffle之后,拼接作为输入,来进行Query+content -> Answer的模型微调。让模型学会区分相关事实和无关事实,并在推理时不去关注无关的信息输入。
同时论文对比了加入无关Fact,和只使用相关Fact微调后的模型效果差异,如下。只使用相关内容的Baseline模型的偏好率18%显著低于,加入随机无关内容微调后的43.7%。因此加入无关上文训练,确实可以提升模型对噪声上文的判别能力。

WebGPT
paper: WebGPT:Browser-assisted question-answering with human feedback
Demo: WebGPT Answer Viewer
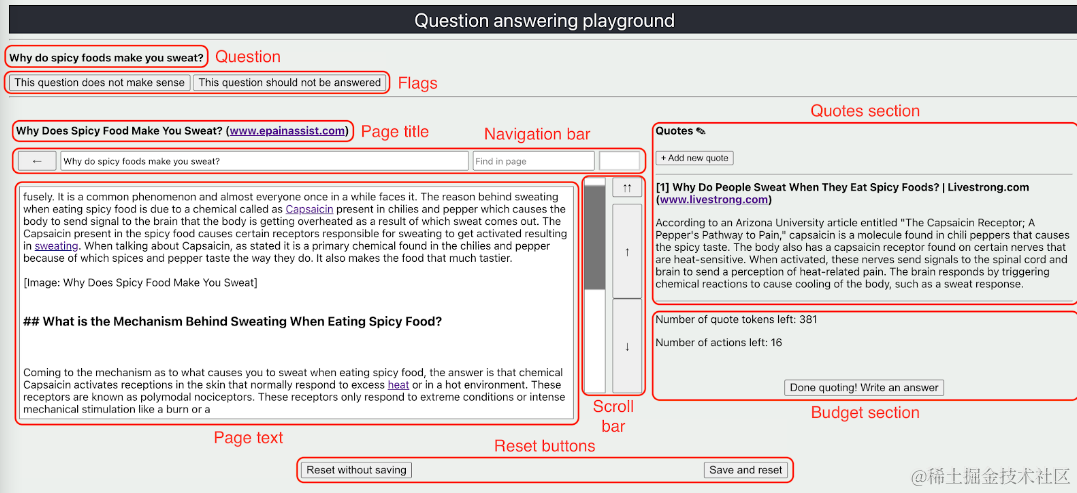
webgpt的论文发表最早,但论文本身写的比较"高山仰止",可能先读完webcpm再来读webgpt,会更容易理解些,只看收集交互式搜索数据使用的界面,就会发现二者非常相似。
webgpt的问题以ELI5为主,混合了少量TriviaQA,AI2,手写问题等其他问题。搜索引擎也是使用了Bing API。和webcpm相同,为了避免直接找到答案简化搜索流程,webgpt过滤了Reddit,quora等类知乎的站点信息,提高任务难度。
多数细节和webcpm比较类似,最大的不同是webgpt除了使用指令微调,还加入了强化学习/拒绝采样的偏好打分方案。
数据收集
webgpt的数据收集分成两部分:
-
Demonstrations:和webcpm的全流程搜索数据类似,从键入query,搜索,摘要,到问题回答,收集人类的交互数据,这里不再细说
-
Comparison: 同一个query模型生成的两个回答的偏好数据,用于训练偏好模型。webgpt开源了这部分的数据
以下我们细说下Comparison的数据集构建。为了降低偏好标注的噪音,和人类偏好主观性的影响,webgpt只使用引用源来判断模型回答的优劣,具体标注步骤如下
-
Flags:剔除不合理,争议性问题
-
Trustworthiness:先对模型引用的数据源进行标注:分为Trustworthy,Netural, Suspicious三挡,区分不同网页的权威性和真实性
-
Annotations:选定模型回答的每一个观点(高亮),根据该观点是否有引用支持,以及支持该观点的引用在以上的权威性分类中属于哪一档,来综合评价每个观点。也分为三挡strong support, weak support, no support。同时需要标注每个观点对于回答最终提问的重要性,有core,side,irrelevant三挡。
-
Ratings:分别对模型采样生成的AB两个答案标注完以上3步之后,才到对比打分的环节。webgpt给出了很详细的如何综合每个观点的重要性和是否有支撑,对AB答案进行觉得打分,再对比两个打分得到相对打分,此处有无数人工智能中智能的人工.......详见论文中的标注文档链接~

训练
对应上面的数据收集,webgpt的训练过程和InstructGPT基本是一致的。先使用Demonstration数据进行指令微调,论文称之为Behaviour Cloning,顾名思义模仿人类的搜索过程(BC)。再基于BC模型,使用Comparison对比数据训练偏好模型(RM)。最后基于偏好模型使用PPO算法微调BC模型得到强化微调后的模型(RL)。训练细节可以直接参考InstructGPT。
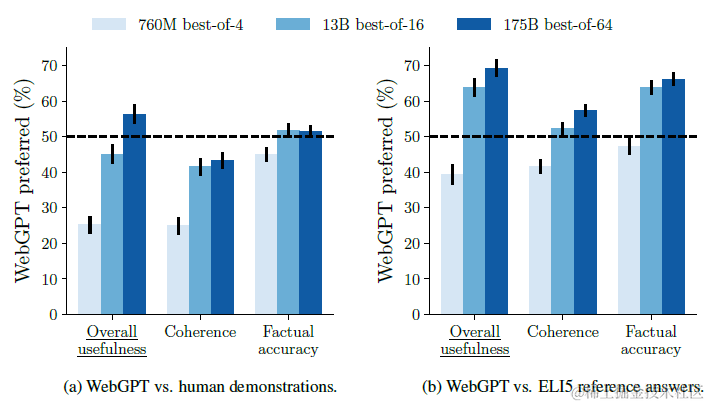
在解密Prompt7. 偏好对齐RLHF-OpenAI·DeepMind·Anthropic对比分析中我们讨论过强化学习的本质之一其实就是拒绝采样,论文也对比了使用BC/RL模型为基座,加入拒绝采样,随机采样4/16/64个模型回答,从中选取偏好模型打分最高的回答作为结果的方案。论文中效果最好的方案是BC+Best of 64拒绝采样。RL模型相比BC略有提升,但提升幅度没有拒绝采样来的高。
评估方案,论文把webgpt生成的结果,和Eli5数据集的原始结果(Reddit上的高赞答案),以及Demonstration中人工标注的答案进行偏好对比,让标注同学选择更偏好的答案。效果上,175B的微调模型,在64个回答中采样RM打分最高的答案,效果上是可以显著超越人工回答的。
WebGLM
paper: WebGLM: Towards An Efficient Web-Enhanced Question Answering System with Human Preferences
github: GitHub - THUDM/WebGLM: WebGLM: An Efficient Web-enhanced Question Answering System (KDD 2023)
webglm介于二者中间,是用google search api, 英文数据做的项目。整个项目数据集构建过程自动化程度更高,人工标注依赖更少,性价比更高一些。这里主要介绍数据集构建上的一些差异,架构和前两者差不多。
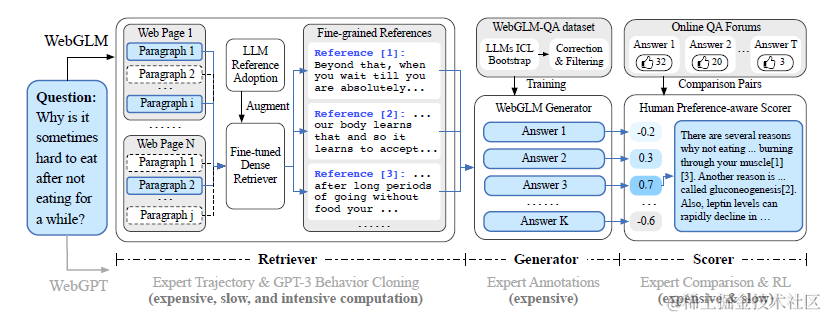
Retriever
和webcpm使用抽取的方案来定位网页内容中和qurery相关的部分不同,webglm采取了先对网页进行分段,然后每个段落和query计算相似度,通过相似度来筛选相关内容的方案。作者选取了基于对比学习的Contriever预训练模型,不过评估准确率只有不到70%。
因此这里使用大模型的阅读理解能力来补充构建了query*reference样本对。论文使用GPT-3 1-shot 。也就是给一个相关段落抽取的case,让大模型来从众多段落中筛选和query相关的。并对模型构建的样本集过滤query-reference相关度较低,大概率是模型发挥的低质量样本。
然后基于大模型构造的样本,使用query和reference embedding的内积作为相似度打分,微调目标是拟合相似度打分的MSE Loss。
synthesis
sysnthesis,也就是基于引用内容,大模型进行QA问答的部分,webglm使用davinci-003来进行样本生成, 这里主要包含四个步骤
-
大模型生成指令:这里作者使用了APE的方案,不熟悉的同学看这里# APE+SELF=自动化指令集构建代码实现。输入是Question+Refernce,输出是Answer, 问大模型,什么样的指令可以更好描述这类LFQA任务。大模型给出的指令是:Read the Refernces Provided and answer the corresponding question
-
few-shot构造样本:基于生成的instruction,人工编写几个few-shot样本,给大模型更多的query+Reference,让davinci-003来构建推理样本
-
引用校准:论文发现模型生成结果存在引用内容正确,但是引用序号错误的情况,这里作者用Rouge-1进行相似度判断,校准引用的Reference。
-
样本过滤:再强的大模型也是模型,davinci-003造的样本质量参差不齐,部分模型会自己发挥。因此加入了质量过滤模块,主要过滤引用占比较低,引用太少,以及以上引用需要错误率较高的。
通过以上的生成+过滤,最终从模型生成的83K样本过滤得到45K质量更高的LFQA样本用于推理部分的模型微调
RM模型
webglm没有像webgpt一样使用人工标注对比偏好数据,而是使用线上QA论坛的点赞数据作为偏好数据,高赞的是正样本。并通过过滤掉回答较少的问题,对长文本进行截断,以及使用点赞数差异较大的回答构建对比样本对,等数据预处理逻辑,得到质量相对较高,偏好差异较大,长度相对无偏的偏好样本。整体量级是93K个问题,249K个样本对。
其实现在大模型的样本构建往往有两种方案,一个是高质量小样本,另一个就是中低质量大样本,前者直接告诉模型如何做,后者是在质量参差不齐的样本中不断求同存异中让模型抽取共性特征。webglm是后者,而webgpt是前者。
其次RL的初始模型,对标以上webgpt的BC模型。在之前RL的博客中我们有提到过,初始模型需要是有能力生成人类偏好答案的对齐后的模型。这里webglm直接使用Reddit的摘要数据,通过指令微调得到,也没有使用人工标注数据,考虑摘要任务也属于阅读理解的子任务。
上一章我们主要讲搜索引擎和LLM的应用设计,这一章我们来唠唠大模型和DB数据库之间的交互方案。有很多数据平台已经接入,可以先去玩玩再来看下面的实现方案,推荐
-
sql translate:简单,文本到SQL,SQL到文本双向翻译,新手体验
-
ai2sql:功能更全,包括语法检查,格式化等
-
chat2query:可处理复杂query和实时数据
-
OuterBase:加入电子表格的交互和可视化模块
本章会提到的前置知识点有Chain-of-thought,Least-to-Most Prompt,Self-Consistency Prompt,建议不熟悉的同学先看下解密Prompt系列9. 模型复杂推理-思维链基础和进阶玩法
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!