第5章:知识存储:概述、方法、实战
💗💗💗欢迎来到我的博客,你将找到有关如何使用技术解决问题的文章,也会找到某个技术的学习路线。无论你是何种职业,我都希望我的博客对你有所帮助。最后不要忘记订阅我的博客以获取最新文章,也欢迎在文章下方留下你的评论和反馈。我期待着与你分享知识、互相学习和建立一个积极的社区。谢谢你的光临,让我们一起踏上这个知识之旅!

🥦知识存储概述
知识从某种程度上也属于一种数据
🥦知识存储的定义
"知识存储"指的是将信息、数据、经验和概念等以某种形式记录下来,并存储在特定的媒介或系统中,以便后续检索、利用和共享。知识存储是知识管理的一部分,它有助于组织、保存和传递知识,以便在需要时能够方便地获取和利用。
知识存储可以采用多种形式,包括文本文档、数据库、图形、多媒体文件等。这些存储形式可以涵盖各种领域,包括科学、技术、业务、文化等。在组织和企业中,知识存储通常与知识管理系统(Knowledge Management System)相关联,以促进知识的共享、协作和创新。
在当前的知识图谱标准中,这些知识数据的基本数据结构是RDF数据和图模型,所以知识数据的存储系统实质上是研究如何存储RDF和图,知识图谱需要存储的基本数据包括:三元组知识、事件信息、时态信息、基于图结构和数据。
🥦知识存储的方法
本节从基于关系型数据集、NoSQL、分布式入门来介绍一下知识存储的几种方法
🥦基于关系型数据库的知识存储
关系型数据库采用关系模型来组织数据,并以行和列的形式存储数据,一行表示一条记录,一列表示一种属性,用户通过SQL查询功能来检索数据库中的数据。
基于关系型数据库的知识存储方案主要有以下几种:基于三元组的三列表存储、水平表存储,以及基于类型的属性表存储和全索引表存储等。
-
三元组存储(Triplestore):
- 定义: 三元组存储是一种图数据库的存储方式,基于三元组的模型,每个三元组由主语(subject)、谓语(predicate)、宾语(object)组成。
- 特点: 这种存储方式非常适合表示图结构的数据,因为每个三元组都是图中的一条边。它允许灵活的数据模型,支持表示实体之间的关系。
- 应用: RDF(Resource Description Framework)是一种常见的使用三元组存储的数据表示标准,用于描述资源之间的关系。
-
水平表存储:
- 定义: 水平表存储是一种数据库设计方法,其中数据被水平划分成多个表,每个表包含相同类型的数据,通常通过关联键进行关联。
- 特点: 这种存储方式有助于减少冗余,提高查询性能,特别是在大规模数据存储和分布式数据库系统中。
- 应用: 分布式数据库系统、大数据存储和处理系统等常常使用水平表存储的设计。
-
基于类型的属性表存储:
- 定义: 这是一种数据存储模型,其中数据表的结构是根据数据类型和属性进行设计的,每个属性都有一个明确定义的数据类型。
- 特点: 这种存储方式使得数据更为规范,有助于数据的一致性和可靠性。每个属性都有指定的数据类型,如整数、字符串、日期等。
- 应用: 常见于关系型数据库中,如SQL数据库,其中表的列有明确定义的数据类型。
-
全索引表存储:
- 定义: 这是一种数据库存储方式,其中对表中的所有列都创建了索引,以提高查询性能。
- 特点: 全索引表存储的优势在于查询速度较快,但也存在一定的存储开销和写入性能损失。
- 应用: 适用于需要频繁查询而对写入性能要求相对较低的场景,例如数据仓库和大型查询系统。
过去一段时间,关系型数据库作为知识存储的首选,但是关系型数据库并不太适合建立在集群之上,随着数据规模的迅速扩大,关系型数据库作为存储工具显得十分吃力,研究者们开始考虑其他存储方式,NoSQL数据库进入视野中。
🥦基于NoSQL的知识存储
-
列式存储(Column-family Store):
- 例子:Apache Cassandra
- 特点: Cassandra 是一种高度可扩展的分布式列式存储系统。它适用于需要处理大规模数据和需要水平扩展的场景。数据按照列族(Column Family)的方式组织,可以动态添加列。
- 应用场景: 适用于时间序列数据、日志数据等需要快速写入和读取的大规模分布式系统。
-
基于文档的存储(Document Store):
- 例子:MongoDB(非关系型数据库)
- 特点: MongoDB 是一个常见的文档存储系统,它使用 BSON(二进制JSON) 格式存储数据。每个文档是一个键值对的集合,可以包含嵌套的文档和数组。
- 应用场景: 适用于需要灵活的数据模型和复杂的查询场景,如内容管理系统、电子商务平台等。
-
基于图的存储(Graph Store):
- 例子:Neo4j(后面会实战一下)
- 特点: Neo4j 是一种图数据库,以图的形式存储实体之间的关系。节点表示实体,边表示实体之间的关系,具有高效的图遍历和查询性能。
- 应用场景: 适用于需要深度关系和图算法的场景,如社交网络分析、推荐系统、路径规划等。
🥦基于分布式的知识存储
-
RDFPeers:
- 特点: RDFPeers 是一个基于分布式体系结构的RDF(Resource Description Framework)存储系统。它使用分布式哈希表(DHT)来存储和检索RDF数据,使其能够有效地处理大规模数据集。
- 架构: 采用对等网络(Peer-to-Peer)架构,其中每个节点存储一部分RDF数据,并通过分布式哈希表进行索引和查询。
- 应用场景: 适用于需要分布式存储和检索RDF数据的场景,如语义网应用和知识图谱管理。
-
YARS2 (Yet Another RDF Store 2):
- 特点: YARS2 是一个基于分布式存储的RDF存储系统,旨在提供高性能的RDF数据管理。它支持数据的分布式存储和查询,并采用三元组(Triple)作为基本数据单元。
- 架构: 使用分布式哈希表和分区策略,将RDF数据分布式存储在多个节点上。支持SPARQL查询语言。
- 应用场景: 适用于大规模RDF数据的存储和查询,例如语义网应用和知识图谱。
-
4Store:
- 特点: 4Store 是一个基于分布式的开源RDF存储系统,旨在提供高性能和可扩展性。它使用了分布式架构,支持SPARQL查询语言。
- 架构: 数据存储在多个节点上,每个节点负责存储和处理一部分数据。通过节点之间的通信来实现查询和更新。
- 应用场景: 适用于需要高性能和可扩展性的大规模RDF数据存储和检索,例如语义搜索和Linked Data应用。
🥦知识存储的实例
下面我来简单演示一下Neo4j数据库存储数据
演示之前我们首先得做好环境的配置,软件安装,下面附上链接,自行下载
这是我的JDK版本和Neo4j

最后别忘了添加环境变量哈

Neo4j的启动命令如下(注意启动中别关闭窗口)
win+R cmd
neo4j.bat console
运行后
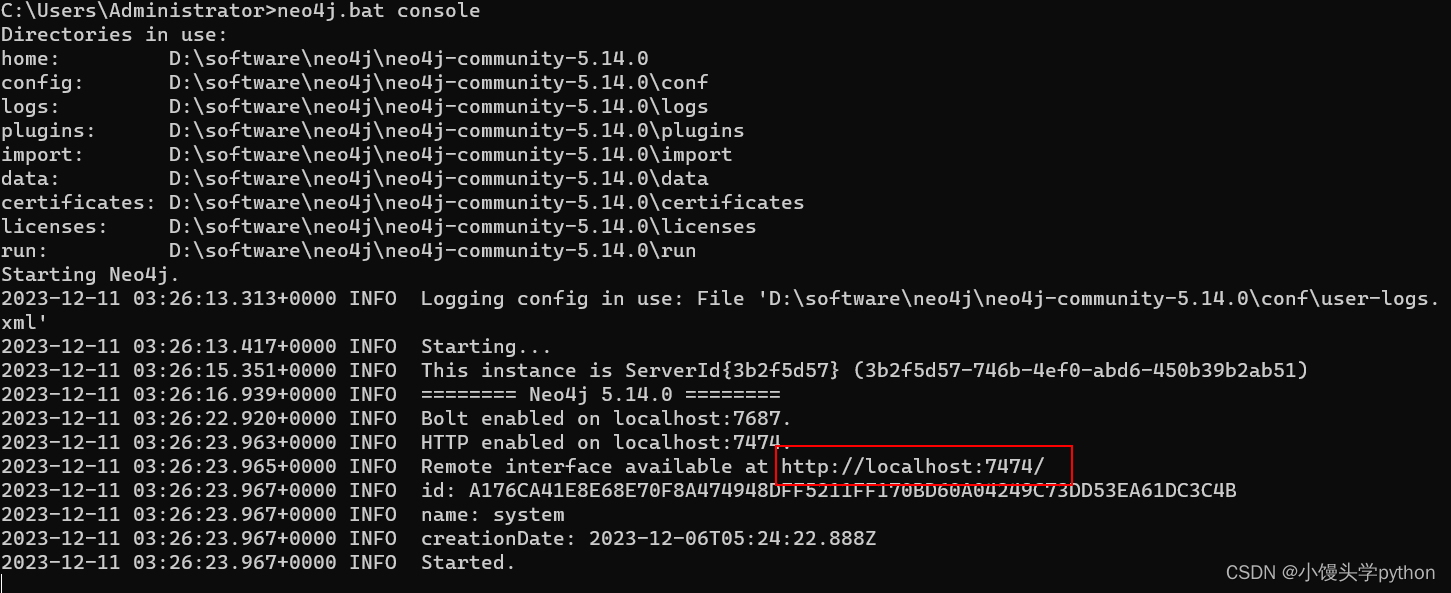
进入红框中的链接即可,我记得有一布设置用户名密码之类的,设置一下后面连接会用到

这就相当于成功安装了,接下来我将介绍怎么使用,附上简单的使用命令
接下来我们使用一组测试数据来演示如何构架一个知识图谱
"head","tail","relation"
"PersonA","PersonB","Friend"
"PersonA","PersonC","Colleague"
"PersonB","PersonD","Sibling"
"PersonC","PersonE","Parent"
"PersonD","PersonF","Spouse"
将上面的文件保存到txt文件再重命名为csv文件即可
import csv
import py2neo
from py2neo import Graph,Node,Relationship,NodeMatcher
g=Graph('http://localhost:7474',user='neo4j',password='自己的密码',name='neo4j')
with open('测试.csv', 'r', encoding='utf-8') as f:
reader=csv.reader(f)
for item in reader:
if reader.line_num==1: # 跳过CSV文件的第一行,因为它通常包含标题而不是数据。
continue
print("当前行数:",reader.line_num,"当前内容:",item)
start_node=Node("Person",name=item[0]) # 创建节点
end_node=Node("Person",name=item[1])
relation=Relationship(start_node,item[2],end_node) # 创建关系
g.merge(start_node,"Person","name") # 如果已存在具有相同属性值的节点,则不会重复创建。相比之下还有一个create,这个如果重复运行会重复创建不会进行覆盖
g.merge(end_node,"Person","name")
g.merge(relation,"Person","name")
构建之后的图谱如下
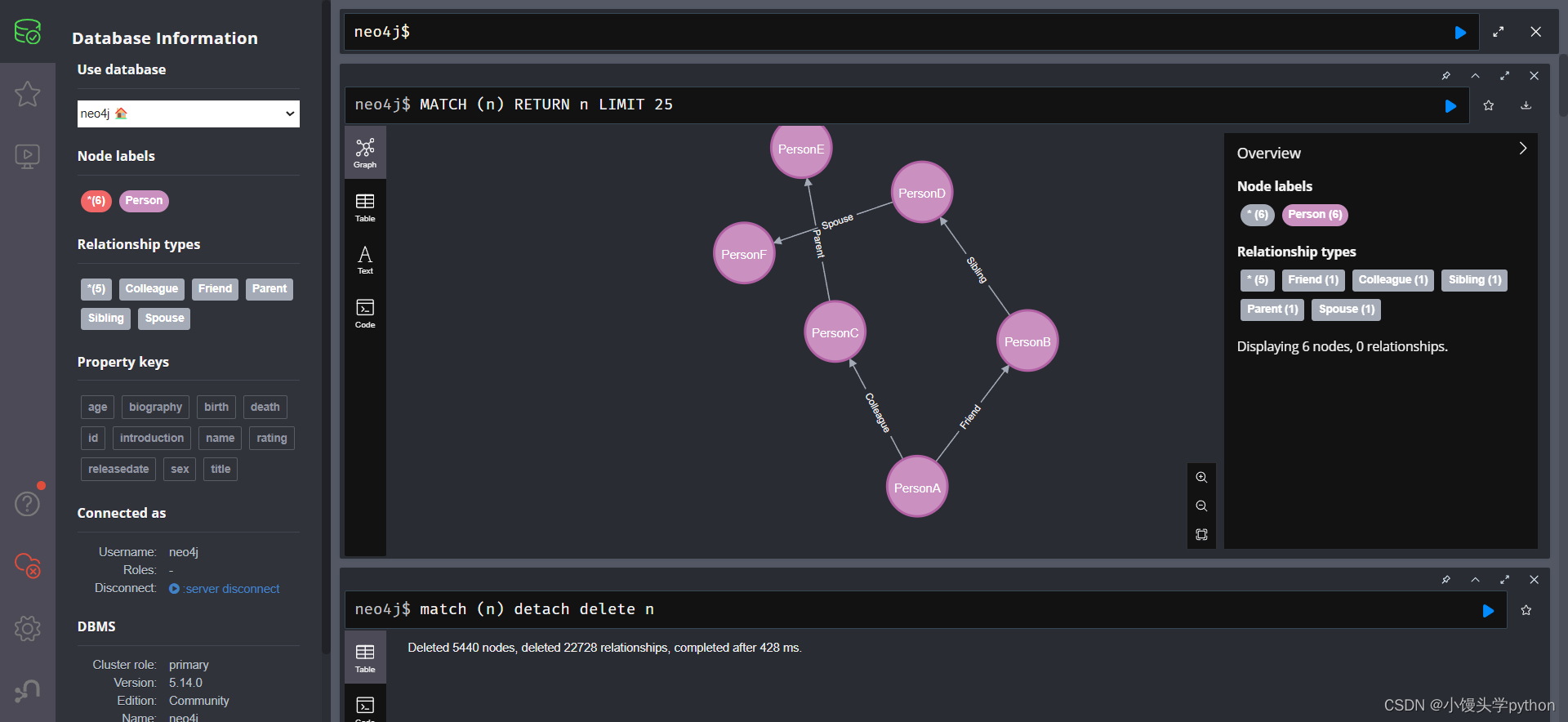
我之前在构建完其他的知识图谱后再构建,会造成节点一大堆,大家可以使用如下命令进行清空,但是清空后需要重新构建图谱
match (n) detach delete n


挑战与创造都是很痛苦的,但是很充实。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!