mysql的redolog、undo、binlog的作用
概览:
MySQL三大日志包括:undolog,redo log,binlog,它们分别有以下作用:
undolog:是Innodb存储引擎事务生成的日志。用于事务的回滚和MVCC,保证了事务的原子性。
redo log:是Innodb存储引擎事务生成的日志。用于崩溃后修复数据,保证了事务的持久性。
binlog:是Server层生成的日志。用于备份数据,集群主从复制等。
一.undo log
undo log 两大作用:
实现事务回滚,保障事务的原子性。事务处理过程中,如果出现了错误或者用户执 行了 ROLLBACK 语句,MySQL 可以利用 undo log 中的历史数据将数据恢复到事务开始之前的状态。
实现 MVCC(多版本并发控制)关键因素之一。MVCC 是通过 ReadView + undo log 实现的。undo log 为每条记录保存多份历史数据,MySQL 在执行快照读(普通 select 语句)的时候,会根据事务的 Read View 里的版本信息,顺着 undo log 的版本链找到满足其可见性的记录。
事务回滚
undo log用于回滚数据,在开始执行事务时,MySQL会把更新前的数据都记录到undolog里面,
事务提交前如果MySQL崩溃,这时候我们可以进行回滚操作回到数据更新前的状态。

undo log 格式:undo log 格式都有一个 roll_pointer 指针和一个 trx_id 事务id
通过 trx_id 可以知道该记录是被哪个事务修改的;
通过 roll_pointer 指针可以将这些 undo log 串成一个链表,这个链表就被称为版本链;
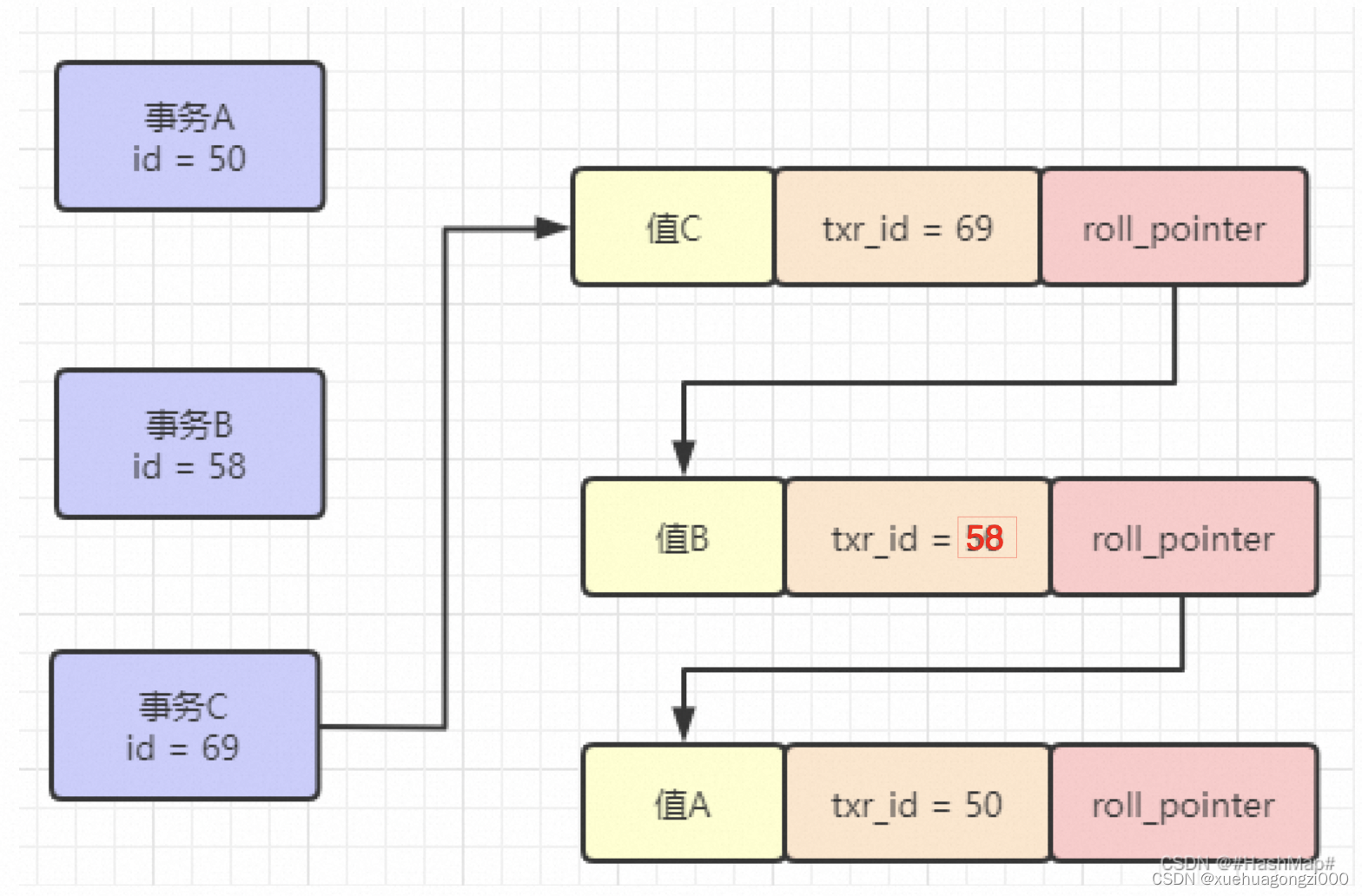
多版本并发控制
另外,undo log 还有一个作用,通过 ReadView + undo log 实现 MVCC(多版本并发控制)。
「读提交」隔离级别是在每个 select 都会生成一个新的 Read View,也意味着,事务期间的多次读取同一条数据,前后两次读的数据可能会出现不一致,因为可能这期间另外一个事务修改了该记录,并提交了事务。从版本链中获取不同版本号的数据。
「可重复读」隔离级别是启动事务时生成一个 Read View,然后整个事务期间都在用这个 Read View,这样就保证了在事务期间读到的数据都是事务启动前的记录。从版本链中获取事务启动前版本号的数据。
二.Buffer Pool
MySQL 的数据都是存在磁盘中的,那么我们要更新一条记录的时候,得先要从磁盘读取该记录,然后在内存中修改这条记录。修改完这条记录不是直接写回到磁盘,而是缓存起来。
为此,Innodb 存储引擎设计了一个缓冲池(Buffer Pool),来提高数据库的读写性能。
三.redo log(预写日志)
redo log 是物理日志,记录了某个数据页做了什么修改,比如对 XXX 表空间中的 YYY 数据页 ZZZ 偏移量的地方做了AAA 更新,每当执行一个事务就会产生这样的一条或者多条物理日志。
Buffer Pool 是提高了读写效率没错,但是问题来了,Buffer Pool 是基于内存的,而内存总是不可靠,万一断电重启,还没来得及落盘的脏页数据就会丢失。
为了防止断电导致数据丢失的问题,当有一条记录需要更新的时候,InnoDB 引擎就会先更新内存(同时标记为脏页),然后将本次对这个页的修改以 redo log 的形式记录下来,这个时候更新就算完成了。
WAL(Write-Ahead Logging) 技术指的是, MySQL 的写操作并不是立刻写到磁盘上,而是先写日志,然后在合适的时间再写到磁盘上。(redo log是防止断电导致数据丢失的问题)

?redo log 和 undo log 区别在哪?
这两种日志是属于 InnoDB 存储引擎的日志,它们的区别在于:
undo log 记录了此次事务「开始前」的数据状态,记录的是更新之前的值;
redo log 记录了此次事务「完成后」的数据状态,记录的是更新之后的值;
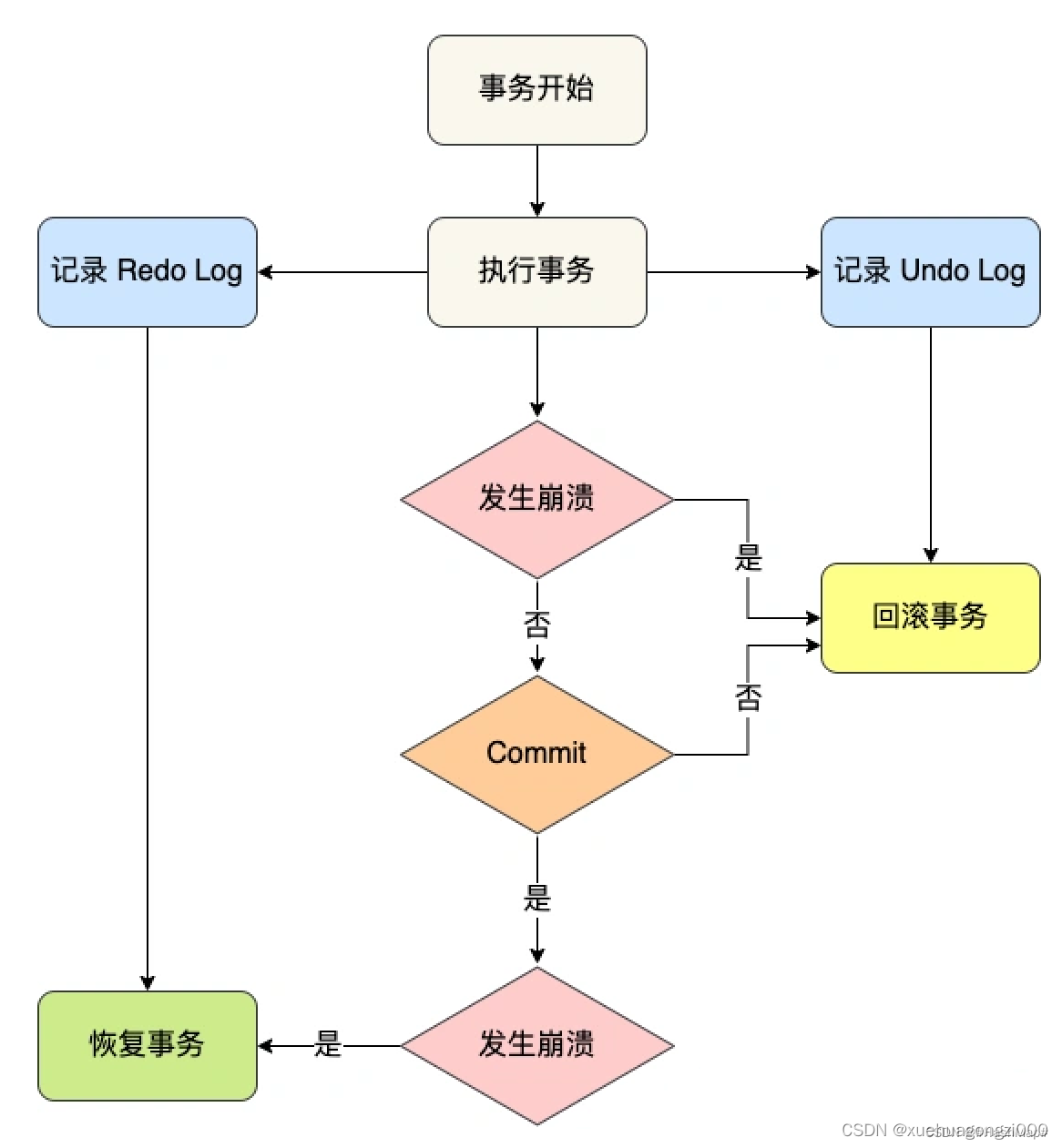
事务提交之前发生了崩溃,重启后会通过 undo log 回滚事务,事务提交之后发生了崩溃,重启后会通过 redo log 恢复事务,如下图:
InnoDB 还提供了另外两种策略,由参数 innodb_flush_log_at_trx_commit 参数控制,
当设置该参数为 1 时,表示每次事务提交时,都将缓存在 redo log buffer 里的 redo log 直接持久化到磁盘,这样可以保证 MySQL 异常重启之后数据不会丢失。
四.binlog?
概述:
MySQL 在完成一条更新操作后,Server 层还会生成一条 binlog,等之后事务提交的时候,会将该事物执行过程中产生的所有 binlog 统一写 入 binlog 文件。
binlog 文件是记录了所有数据库表结构变更和表数据修改的日志,不会记录查询类的操作,比如 SELECT 和 SHOW 操作。
?redo log 和 binlog 有什么区别?
1、用途不同:
binlog 用于备份恢复、主从复制;
redo log 用于掉电等故障恢复。
2、适用对象不同:
binlog 是 MySQL 的 Server 层实现的日志,所有存储引擎都可以使用;
redo log 是 Innodb 存储引擎事务实现的日志;
3、文件格式不同:
binlog 记录每一条修改数据的 SQL (相当于记录了逻辑操作,所以针对这种格式, binlog 可以称为逻辑日志),
redo log 是物理日志,记录的是在某个数据页做了什么修改,比如对 XXX 表空间中的 YYY 数据页 ZZZ 偏移量的地方做了AAA 更新;
4、写入方式不同:
binlog 是追加写,写满一个文件,就创建一个新的文件继续写,不会覆盖以前的日志,保存的是全量的日志。
redo log 是循环写,日志空间大小是固定,全部写满就从头开始,保存未被刷入磁盘的脏页日志。
五.两阶段提交
事务提交后,redo log 和 binlog 都要持久化到磁盘,但是这两个是独立的逻辑,可能出现半成功的状态,这样就造成两份日志之间的逻辑不一致。
如果在将 redo log 刷入到磁盘之后, MySQL 突然宕机了,而 binlog 还没有来得及写入。
如果在将 binlog 刷入到磁盘之后, MySQL 突然宕机了,而 redo log 还没有来得及写入。
MySQL 为了避免出现两份日志之间的逻辑不一致的问题,使用了「两阶段提交」来解决,两阶段提交其实是分布式事务一致性协议,它可以保证多个逻辑操作要不全部成功,要不全部失败,不会出现半成功的状态。
两阶段提交把单个事务的提交拆分成了 2 个阶段,分别是「准备(Prepare)阶段」和「提交(Commit)阶段」
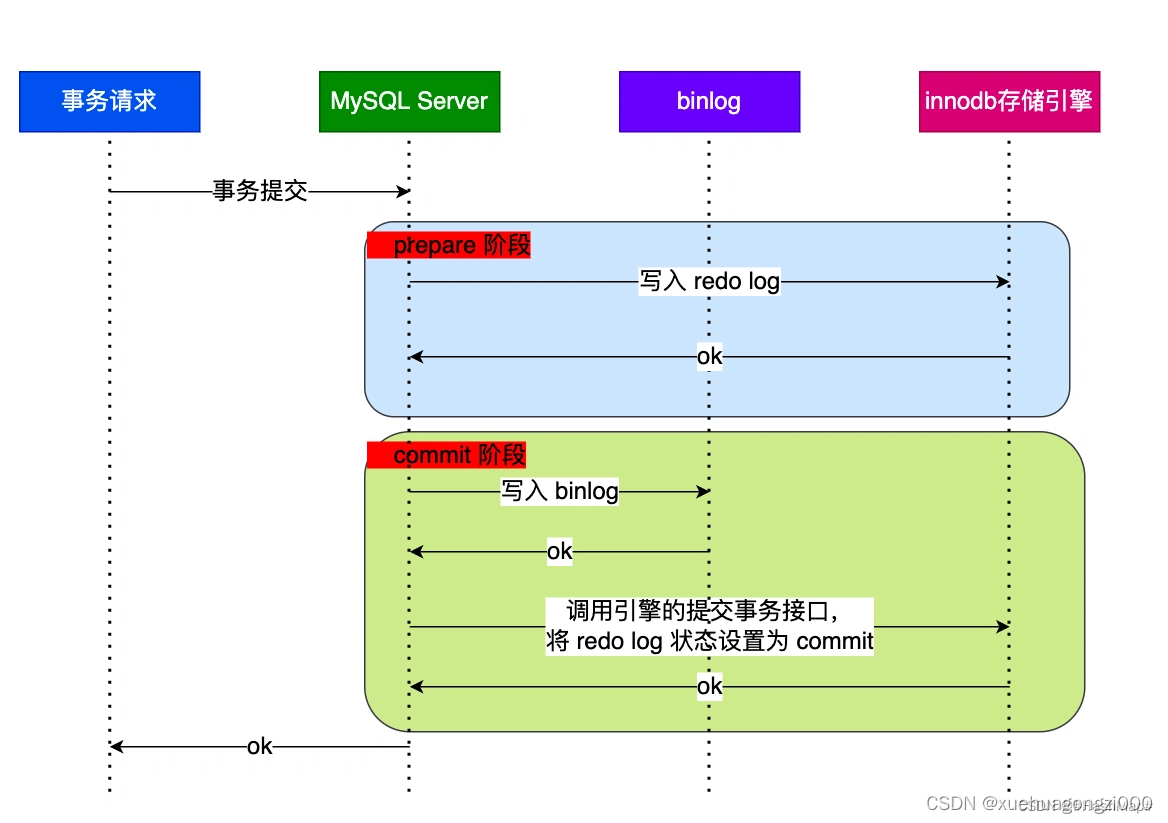
从图中可看出,事务的提交过程有两个阶段,就是将 redo log 的写入拆成了两个步骤:prepare 和 commit,中间再穿插写入binlog,具体如下:
prepare 阶段:将 XID(内部 XA 事务的 ID) 写入到 redo log,同时将 redo log 对应的事务状态设置为 prepare,然后将 redo log 持久化到磁盘(innodb_flush_log_at_trx_commit = 1 的作用);
commit 阶段:把 XID 写入到 binlog,然后将 binlog 持久化到磁盘(sync_binlog = 1 的作用),接着调用引擎的提交事务接口,将 redo log 状态设置为 commit。只要 binlog 写磁盘成功,就算 redo log 的状态还是 prepare 也没有关系,一样会被认为事务已经执行成功;
?异常重启会出现什么现象?
不管是时刻 A(redo log 已经写入磁盘, binlog 还没写入磁盘),还是时刻 B (redo log 和 binlog 都已经写入磁盘,还没写入 commit 标识)崩溃,此时的 redo log 都处于 prepare 状态。
在 MySQL 重启后会按顺序扫描 redo log 文件,碰到处于 prepare 状态的 redo log,就拿着 redo log 中的 XID 去 binlog 查看是否存在此 XID:
如果 binlog 中没有当前内部 XA 事务的 XID,说明 redolog 完成刷盘,但是 binlog 还没有刷盘,则回滚事务。对应时刻 A 崩溃恢复的情况。
如果 binlog 中有当前内部 XA 事务的 XID,说明 redolog 和 binlog 都已经完成了刷盘,则提交事务。对应时刻 B 崩溃恢复的情况。
可以看到,对于处于 prepare 阶段的 redo log,即可以提交事务,也可以回滚事务,这取决于是否能在 binlog 中查找到与 redo log 相同的 XID,如果有就提交事务,如果没有就回滚事务。这样就可以保证 redo log 和 binlog 这两份日志的一致性了。
所以说,两阶段提交是以 binlog 写成功为事务提交成功的标识,因为 binlog 写成功了,就意味着能在 binlog 中查找到与 redo log 相同的 XID。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!