gpt1与bert区别
2023-12-13 12:30:19
目录
区别1:网络结构(主要是Masked Multi-Head-Attention和Multi-Head-Attention)
区别1:网络结构(主要是Masked Multi-Head-Attention和Multi-Head-Attention)
????????gpt1使用transformer的decoder,单向编码,是一种基于语言模型的生成式模型,更适合生成下一个单词或句子
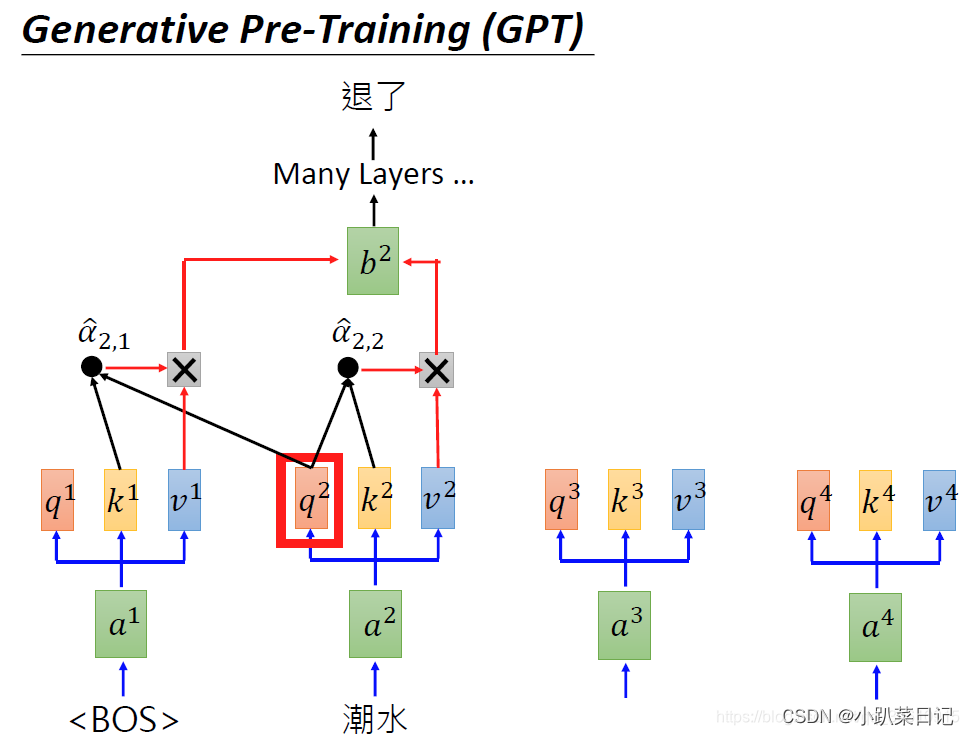
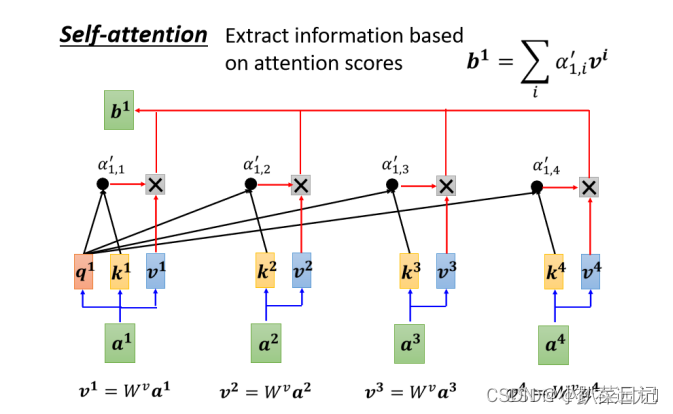
????????bert使用transformer的encoder,双向编码,适合处理需要理解整个句子或段落的任务。可以用于许多NLP任务,如分类、命名实体识别和句子关系判断等
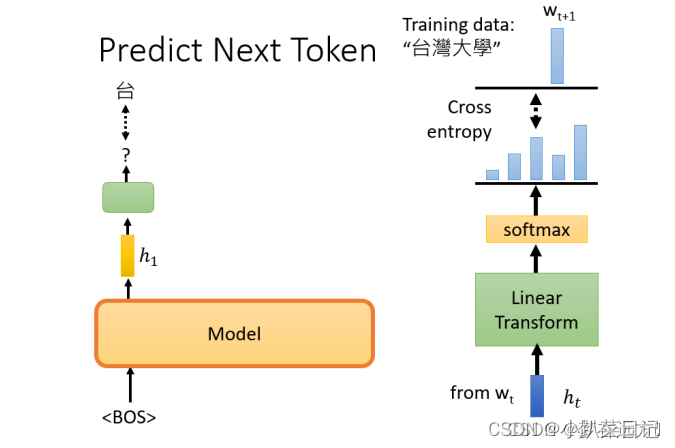
区别2:预训练任务(主要是Masking Input)
????????有一个句子是台湾大学,GPT选取BOS这个起始Token,所对应的输出embedding,用h来表示。然后通过一个Linear Transform,再通过一个softmax,得到一个概率分布,我们希望这个输出的概率分布,跟正确答案的交叉熵越小越好。
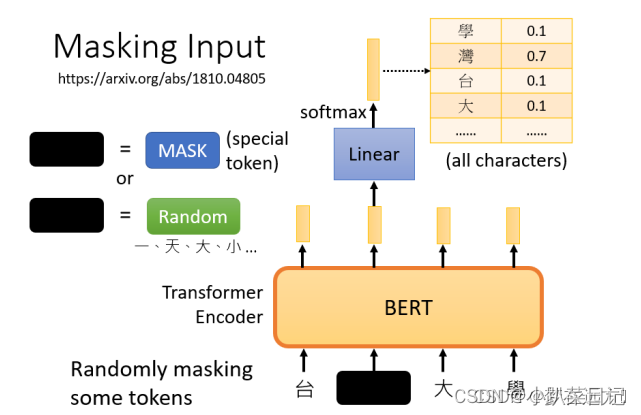
????????在Bert的预训练任务中,Bert主要使用“填空题"的方式来完成预训练,当我们输入一个句子时,其中的一些词会被随机mask。可以用一个one-hot vector来表示这个字符,并使输出和one-hot vector之间的交叉熵损失最小。
文章来源:https://blog.csdn.net/qq_55736201/article/details/134843409
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!