Nougat:科学文档的OCR 使用记录
https://github.com/facebookresearch/nougat
python环境需要在3.8以上
安装:pip?install?nougat-ocr
模型默认下载地址:/home/****/.cache/torch/hub/nougat-0.1.0-small
环境安装好之后默认使用cpu
UserWarning: CUDA initialization: The NVIDIA driver on your system is too old (found version 11080). Please update your GPU driver by downloading and installing a new version from the URL: http://www.nvidia.com/Download/index.aspx Alternatively, go to: https://pytorch.org to install a PyTorch version that has been compiled with your version of the CUDA driver. (Triggered internally at ../c10/cuda/CUDAFunctions.cpp:108.)
? return torch._C._cuda_getDeviceCount() > 0
WARNING:root:No GPU found. Conversion on CPU is very slow.
如果需要使用GPU,则需要重新安装和自己cuda版本对应的torch等,我这边是cuda11.8
conda?install?pytorch?torchvision?torchaudio?pytorch-cuda=11.8?-c?pytorch?-c?nvidia
环境配置好之后即可进行PDF识别
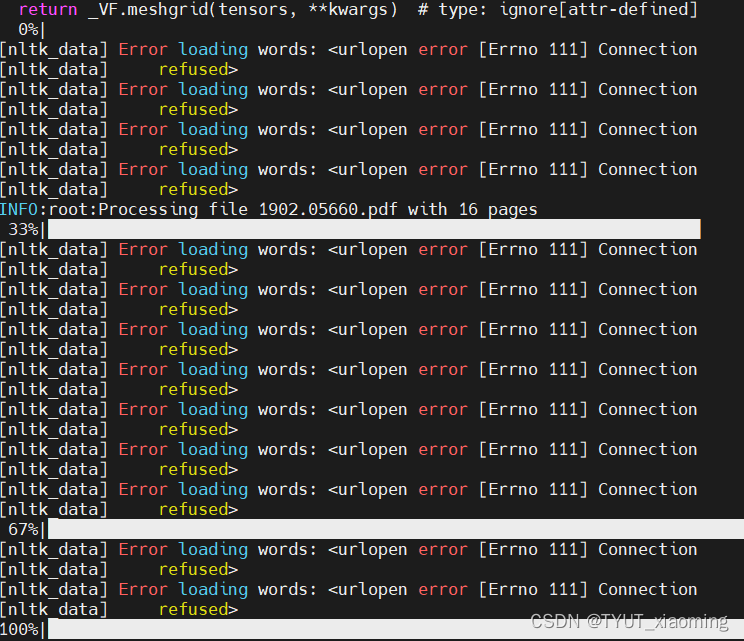
在output目录下会生成.mmd格式的文件
vscode中使用如下插件可以查看mmd格式中的内容,文字可直接复制

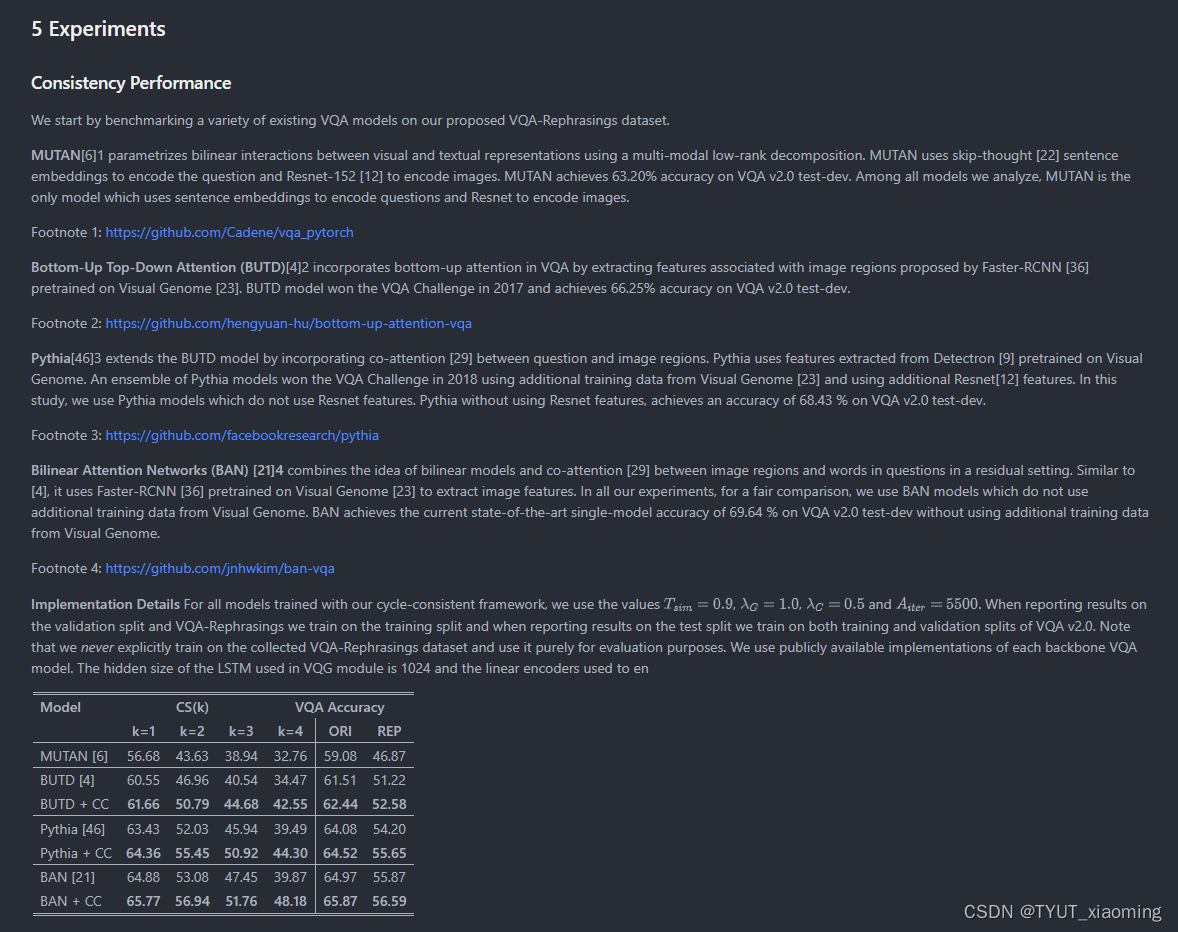
3090GPU上
显存占用17368?/?24576M??显存占用17G,16页的PDF??耗时30秒?
自己随便写的文字可能识别不了,图片中的文字无法识别
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!