oom问题
问题描述
虚拟机集群节点上pod报oom,最后pod被驱逐,主节点上查看kubectl top node的mem使用率很高,重启系统后,mem会降下来,但还会慢慢增长。
node节点上查看 /sys/fs/cgroup/memory/memory.usage_in_bytes内存使用超过物理可用内存。
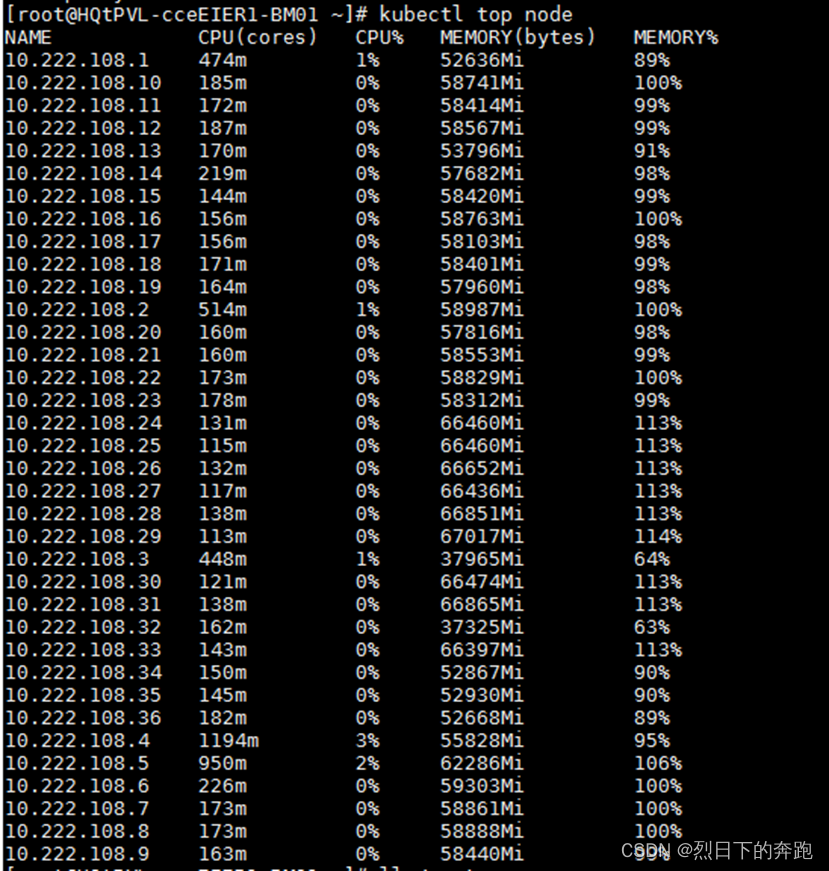
free -m、cat /proc/meminfo查看是有剩内存的。
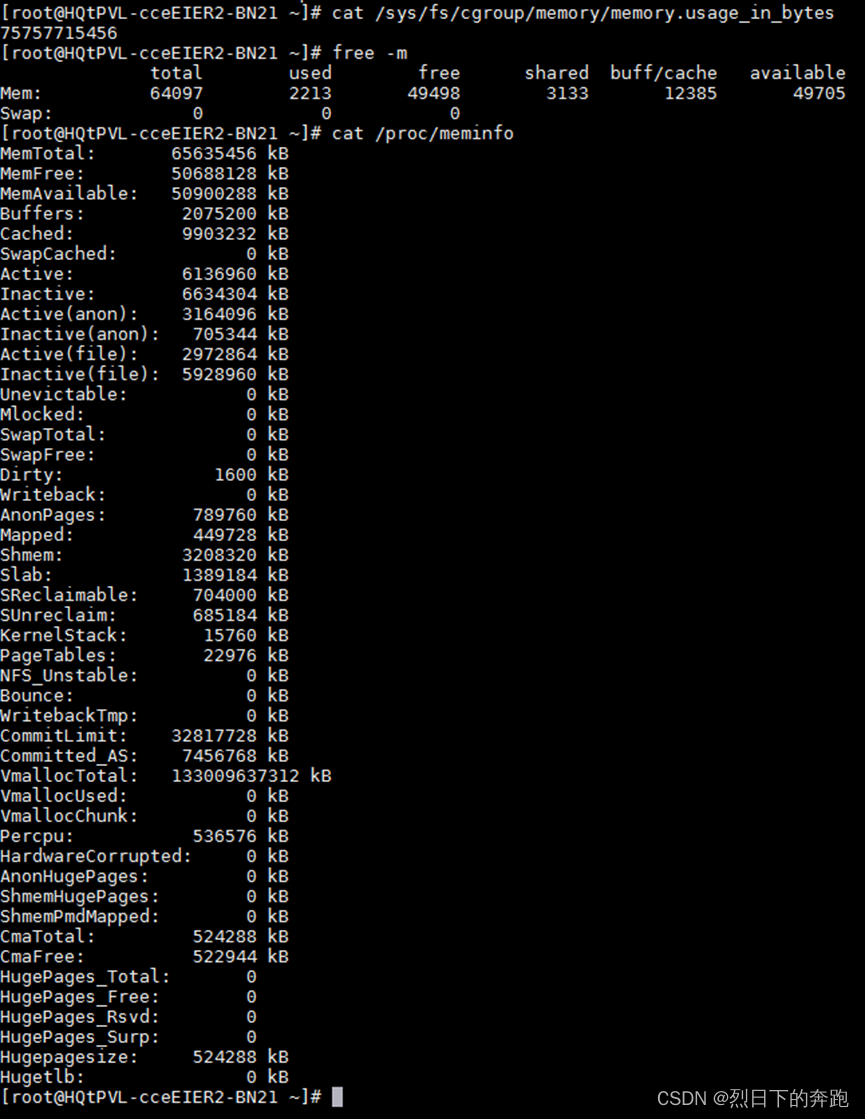
脚本memory.available.sh查看的就是cgroup里的内存。
分析过程
虚拟机集群节点上pod报oom,导致pod被驱逐。报oom的原因是由于上层应用程序不是根据实际物理内存来判断内存是否足够,而是根据/sys/fs/cgroup/memory/memory.usage_in_bytes占用内存比值进行判断。
通过查看sos_report日志,可以确定客户生产系统的/sys/fs/cgroup/memory/memory.usage_in_bytes 值已经超过了实际的物理内存,由此可以判断memory.usage_in_bytes 的统计值出现问题。进一步查看进入/sys/fs/cgroup/memory/user.slice/user-0.slice目录,可以发现该层的total_rss远远大于所有子层的rss的总和,查看cat /proc/cgroup文件,可以看出来内存统计值出现问题。
虽然这些残留的memcg已经释放掉了page,但它和父辈的vmstats仍会因为更新滞后而不为0或偏大,从而导致memory.usage_in_bytes不准确,从而引起系统的异常。
解决方案
主要从两个方面解决销毁过程中的memcg的vmstats与真实值的同步问题:
1) 在memcg被offline时执行一次flush同步操作
2) 对处于销毁过程中的memcg,更新vmstats时绕过阀值判断
?????? 使得memory.usage_in_bytes统计结果和实际内存使用量匹配,从而使memory.usage_in_bytes值大于实际的物理内存的异常情况不再发生。对于本次发生的memory.usage_in_bytes内存超过阈值,引起的pod被逐问题得以修复。
?????? 对memory.usage_in_bytes的算法进行修改的patch(KYLIN: mm/memcontrol: fix wrong vmstats for dying memcg)已经更新到4.19.90-23.14内核,可以通过升级内核来修复本次异常。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!