C:Huffman编码a
【问题描述】
给定一组字符的Huffman编码表(从标准输入读取),以及一个用该编码表进行编码的Huffman编码文件(存在当前目录下的in.txt中),编写程序实现对Huffman编码文件的解码,并按照后序遍历序列输出解码过程中Huffman树(规定树中左分支表示0,右分支表示1)中各结点的访问次数。
例如给定的一组字符的Huffman编码表为:
6
1:111
2:0
+:110
*:1010
=:1011
8:100
第一行的6表示要对6个不同的字符进行编码,后面每行中冒号(:)左边的字符为待编码的字符,右边为其Huffman编码,冒号两边无空格。对于该编码表,对应的Huffman树(树中左分支表示0,右分支表示1)应为:

假如给定的Huffman编码文件in.txt中的内容(由0和1字符组成的序列)为:
111011001010011001011111100
则遍历上述Huffman树即可对该文件进行解码,解码后的文件内容为:
12+2*2+2=18
解码过程中,经过Huffman树中各结点的遍边次数见下图中结点中的数字:
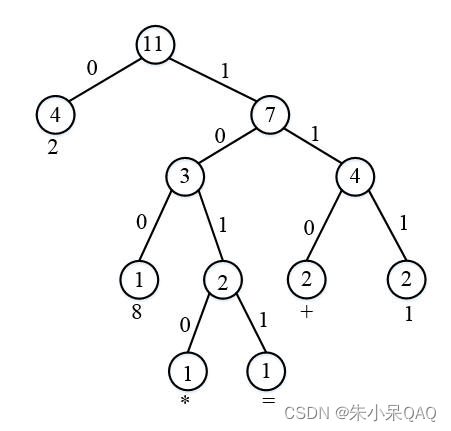
对该Huffman树中各结点的访问次数按照后序序列输出应为:
4 1 1 1 2 3 2 2 4 7 11?
【输入形式】
先从标准输入读入待编码的字符个数(大于等于2,小于等于50),然后分行输入各字符的Huffman编码(先输入字符,再输入其编码,字符和编码中间以一个英文字符冒号:分隔),编码只由0和1组成。
Huffman编码文件为当前目录下的in.txt文本文件,即:其中的0和1都是以单个字符的形式存储,文件末尾有一个回车换行符。
【输出形式】
先将解码后的文件内容输出到标准输出上(独占一行);然后以后序遍历序列输出解码过程中Huffman树中各结点的访问次数,各数据间以一个空格分隔,最后一个数据后也有一个空格。
【样例输入】
6
1:111
2:0
+:110
*:1010
=:1011
8:100
假如in.txt中的内容为:
111011001010011001011111100
【样例输出】
12+2*2+2=18
4 1 1 1 2 3 2 2 4 7 11?
【样例说明】
从标准输入读取了6个字符的Huffman编码,因为规定Huffman树中左分支表示0,右分支表示1,所以利用该编码表可构造上述Huffman树(见图1)。遍历该Huffman树对编码文件in.txt的进行解码,即可得到解码后的原文件内容,遍历过程中各树中结点的最终访问次数要按照后序遍历序列输出。
#include<stdio.h>
#include<stdlib.h>
typedef struct Node {
char name;
int time;
int found;
struct Node* LeftChild;
struct Node* RightChild;
}Node;
void build(char name, char code[], Node* root) {//根据哈夫曼编码构造哈夫曼树
Node* tree = root;
int i = 0;
for (i = 0; code[i] == '0' || code[i] == '1'; i++) {//通过01编码从根开始寻找字符对应结点,0代表左子结点,1代表右子结点
if (code[i] == '0') {
if (tree->LeftChild == NULL) {//若找不到此节点则新建节点
tree->LeftChild = (Node*)malloc(sizeof(Node));
tree = tree->LeftChild;
tree->time = 0;
tree->found = 0;
tree->LeftChild = NULL;
tree->RightChild = NULL;
}
else tree = tree->LeftChild;
}
if (code[i] == '1') {
if (tree->RightChild == NULL) {
tree->RightChild = (Node*)malloc(sizeof(Node));
tree = tree->RightChild;
tree->time = 0;
tree->found = 0;
tree->LeftChild = NULL;
tree->RightChild = NULL;
}
else tree = tree->RightChild;
}
}
tree->name = name;
}
Node* find(Node* tree) {
if (tree->LeftChild != NULL && tree->LeftChild->found != 1) find(tree->LeftChild);
if (tree->RightChild != NULL && tree->RightChild->found != 1) find(tree->RightChild);//后序遍历
printf("%d ", tree->time);
tree->found = 1;
return tree;
}
int main() {
Node* root = (Node*)malloc(sizeof(Node));
int n;
root->LeftChild = NULL;
root->RightChild = NULL;
root->found = 0;
root->time = 0;
scanf("%d", &n);
getchar();
char name[100];
char code[100][50];
for (int i = 0; i < n; i++) {
scanf("%c:%s", &name[i], code[i]);
getchar();
build(name[i], code[i], root);
}//输入编码表
FILE* fp = fopen("in.txt", "r+");
char a[1000];
int num = 0;
for (; fscanf(fp, "%c", &a[num]) != EOF; num++);//读入代码
Node* tree = root;
for (int i = 0; i < num; i++) {//根据读入的0,1编码从根节点开始搜寻,找到叶节点时输出叶节点对应字符
if (a[i] == '0') {
if (tree->LeftChild == NULL) {
printf("%c", tree->name);
tree->time++;//遍历经过某一节点是,++其被遍历次数
tree = root->LeftChild;
root->time++;
}
else {
tree->time++;
tree = tree->LeftChild;
}
}
else if (a[i] == '1') {
if (tree->RightChild == NULL) {
printf("%c", tree->name);
tree->time++;
tree = root->RightChild;
root->time++;
}
else {
tree->time++;
tree = tree->RightChild;
}
}
}
tree->time++;
printf("%c", tree->name);
printf("\n");
for (; find(root) != root;);//后序遍历
}
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!