实时更改数据捕获到 BigQuery — 没有 Kafka,没有Dataflow
实时更改数据捕获到 BigQuery — 没有 Kafka,没有Dataflow
使用 Debezium 和 Pub/Sub 实时运行从 MySQL 到 BigQuery 的 CDC 概念验证……
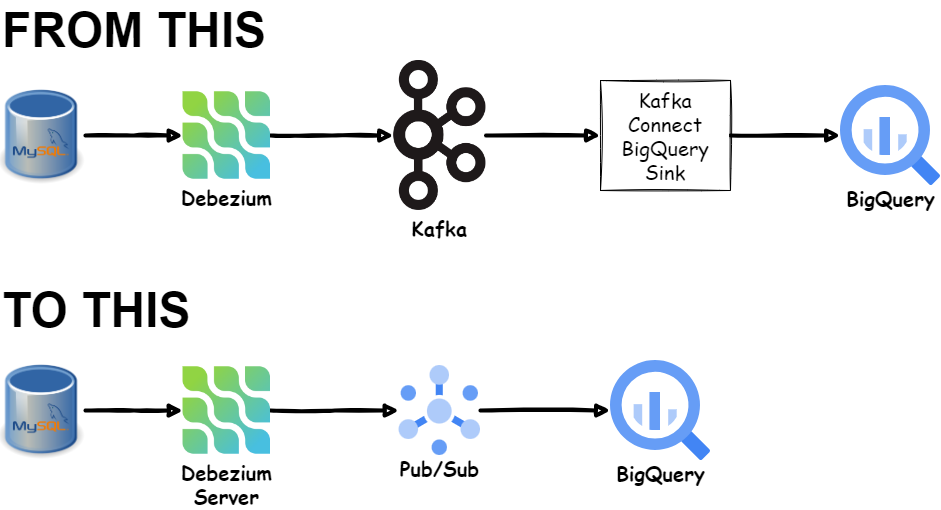
我已经有一段时间没有考虑使用 Debezium 进行概念验证,从 RDBMS 执行变更数据捕获或 CDC,并将数据摄取到 BigQuery,低延迟,无需 Kafka 和 Kafka Connect。上次我尝试使用 Debezium Server-Cloud Pub/Sub 组合,但感到失望,因为我需要部署数据流作业,这会产生额外的成本和更多的资源来管理。所以,我当时就放弃了这个想法。直到…
Update 2022–08–23 使用 FLOAT 或 DOUBLE PRECISION 数据类型的问题已解决。感谢谷歌云团队!
最近,Google Cloud 推出了新功能,可将数据从 Pub/Sub 直接流式传输到 BigQuery。有了这个新的 BigQuery 订阅功能,我可能会有另一种替代解决方案。我很有兴趣尝试一下。
注意:这只是为了好玩,不适用于生产用例。我将在这篇文章的末尾提出更多细节考虑因素。
Preparing Database And Debezium Server Locally
本地准备数据库和 Debezium 服务器
我使用 MySQL 作为源数据库,并使用 Docker 在我的笔记本电脑上部署 Debezium Server。您可以找到下面的 docker-compose.yml 文件作为参考。
version: '3.9'
services:
mysql:
image: quay.io/debezium/example-mysql
container_name: mysql
ports:
- 3306:3306
environment:
- MYSQL_ROOT_PASSWORD=debezium
- MYSQL_USER=mysqluser
- MYSQL_PASSWORD=mysqlpw
debezium-server:
image: quay.io/debezium/server
container_name: debezium-server
environment:
GOOGLE_APPLICATION_CREDENTIALS: /tmp/credentials/service-account.json
ports:
- "8080:8080"
volumes:
- ./demo-sa.json:/tmp/credentials/service-account.json
- ./conf:/debezium/conf
depends_on:
- mysql
restart: "always"
让我们对上面的 Docker Compose 文件做一些简单的解释:
- MySQL 容器预加载了一个名为
inventory的数据库。我们将使用一个名为inventory.products的表作为本次试验的测试表。 - Debezium Server 容器有 2 个安装卷。第一个是服务帐户文件 (
demo-sa.json),具有对 Pub/Sub 和 BigQuery 的写入权限。第二个,我们挂载conf/目录,其中包含名为application.properties的 Debezium Server 配置文件。您可以在下面看到初始配置文件。请参阅 Debezium 服务器接收器配置文档的详细信息。
这是我的目录结构。
├── conf
│ └── application.properties
├── demo-sa.json
└── docker-compose.yml
此时,我们还没有准备好运行 MySQL 和 Debezium 容器,因为我们需要在 Google Cloud 上提供这些资源:
- Pub/Sub schema(s) — optional
- Pub/Sub topic(s)
- Pub/Sub subscription(s)
- BigQuery table(s)
我们稍后将创建这些资源。
了解 BigQuery 订阅
发布/订阅服务帐户权限
要创建 BigQuery 订阅,Pub/Sub 服务帐号必须有权写入特定 BigQuery 表并读取表元数据。将 BigQuery 数据编辑器 (roles/bigquery.dataEditor) 角色和 BigQuery 元数据查看者 (roles/bigquery.metadataViewer) 角色授予 Pub/Sub 服务帐号。具体做法如下:
- 在控制台中,进入 IAM 页面。
- 前往IAM
- 选择包括 Google 提供的角色授予。
- 按名称过滤:Pub/Sub 服务帐户。格式为 service-project-number@gcp-sa-pubsub.iam.gserviceaccount.com 的服务帐户
- 单击 Pub/Sub 服务帐户的编辑。
- 在编辑权限窗格中,单击添加另一个角色。
- 在“选择角色”下拉列表中,输入 BigQuery,然后选择 BigQuery 数据编辑器角色。
- 再次单击添加另一个角色。
- 在选择角色下拉列表中,输入 BigQuery,然后选择 BigQuery 元数据查看者角色。
有关更多信息,请参阅将 BigQuery 角色分配给 Pub/Sub 服务帐号。
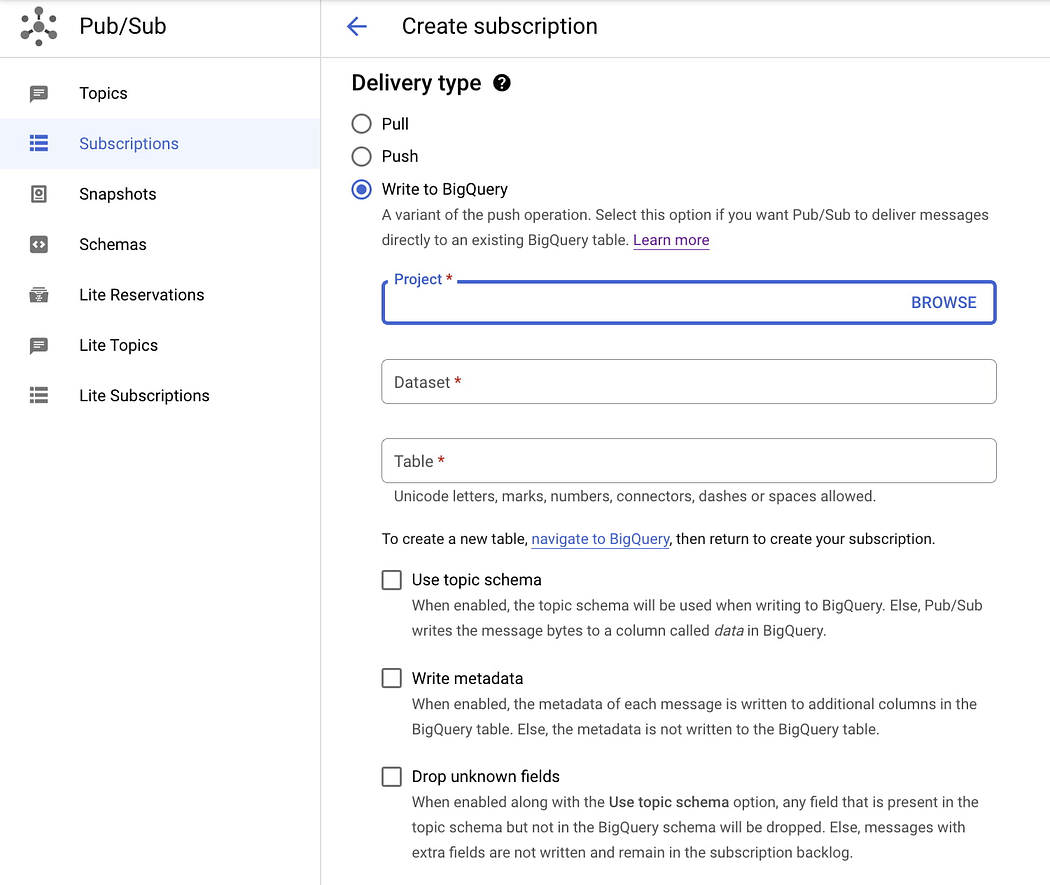
BigQuery 订阅的属性:Topic Schema
BigQuery 订阅有一个名为“使用Topic Schema”的选项。此选项允许 Pub/Sub 将主题消息中的字段写入 BigQuery 表中的相应列。这听起来很有趣。但是,它还有额外的要求:
- 主题架构和 BigQuery 架构中的字段必须具有相同的名称,并且它们的类型必须彼此兼容。
- 主题架构中的任何可选字段在 BigQuery 架构中也必须是可选的。
- 主题架构中的必填字段在 BigQuery 架构中不需要是必填字段。
- 如果主题架构中不存在 BigQuery 字段,这些 BigQuery 字段必须采用模式
NULLABLE。 - 如果主题架构具有 BigQuery 架构中不存在的其他字段并且可以删除这些字段,请选择“删除未知字段”选项。
如果我们不使用“Topic Schema”选项,订阅将写入名为 data 的列。因此,使用此选项更容易。只需确保目标表具有 data 列即可。
有关详细信息,请参阅 BigQuery 订阅属性文档。
我先选择不使用Topic Schema。
但是,在此之前,让我们设置一些环境变量以使我们的生活更轻松。
所以,事不宜迟…… 马上开始!
无 Schema Definition的 MySQL CDC 到 BigQuery
Let’s prepare the required resources before we run the CDC part.
在运行 CDC 部分之前,让我们准备好所需的资源。
首先,创建一个 BigQuery 表。由于我们不使用架构,因此我们将仅创建一个包含 data 列的表。
CREATE OR REPLACE TABLE
<project_id>.<dataset>.mysql_inventory_products_no_schema (
data STRING
);
接下来,创建一个名为 mysql.inventory.products 的 Pub/Sub 主题。如此命名的原因是,Debezium Server for MySQL 使用 serverName.databaseName.tableName 约定作为目标主题名称。
gcloud pubsub topics create mysql.inventory.products
接下来,创建 BigQuery 订阅。
gcloud pubsub subscriptions create \
mysql.inventory.products-bq-sub \
--topic mysql.inventory.products \
--bigquery-table=$PROJECT_ID.$BQ_DATASET.mysql_inventory_products_no_schema
现在,让我们运行容器。
docker-compose up
在等待 MySQL 容器准备就绪时,Debezium Server 容器可能会退出并重新启动多次。
使用 SQL 检查 BigQuery。
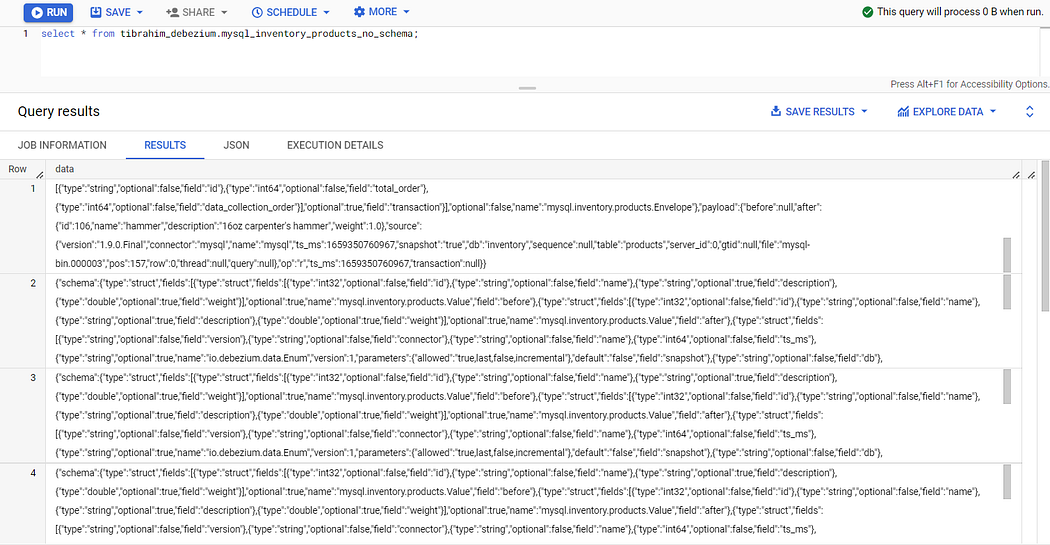
可以工作,但是数据看上去很乱!
为什么记录数据是这个样子?
因为 Debezium Server 默认发送原始 CDC 格式,包括数据本身的 payload 和 schema 。您可以在 Debezium MySQL 数据更改事件文档页面上了解更多相关信息。
我们需要使用 Debezium 的单消息转换 (SMT),称为新记录状态提取。让我们将这些行添加到 application.properties 文件中。
debezium.source.transforms=unwrap
debezium.source.transforms.unwrap.type=io.debezium.transforms.ExtractNewRecordState
debezium.source.transforms.unwrap.add.fields=op,table,source.ts_ms
debezium.source.transforms.unwrap.delete.handling.mode=rewrite
让我们重置所有的事情并重新开始。
# Delete subscription
gcloud pubsub subscriptions delete mysql.inventory.products-bq-sub
# Delete topic
gcloud pubsub topics delete mysql.inventory.products
# Recreate BigQuery table (Using SQL UI)
CREATE OR REPLACE TABLE
<project_id>.<dataset>.mysql_inventory_products_no_schema (
data STRING
);
# Create topic
gcloud pubsub topics create mysql.inventory.products
# Create subscription
gcloud pubsub subscriptions create \
mysql.inventory.products-bq-sub \
--topic mysql.inventory.products \
--bigquery-table=$PROJECT_ID.$BQ_DATASET.mysql_inventory_products_no_schema
# Make sure containers is empty
docker-compose down -v
# Restart containers
docker-compose up
使用 SQL 再次检查。

现在,这样好多了。等等… 那些 schema 是什么东西呢?我们能去掉它们吗?
当然,我们可以。在 application.properties 上添加这些行并重新开始。
debezium.source.key.converter.schemas.enable=false
debezium.source.value.converter.schemas.enable=false
使用 SQL 再次检查。
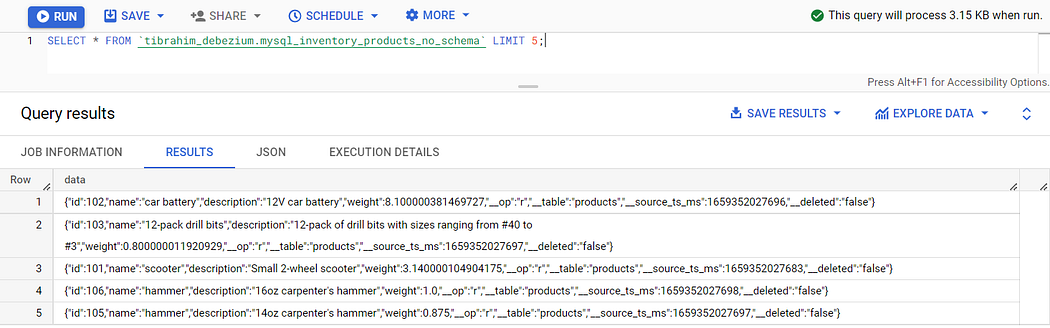
太好了!
就这样吧!
请注意,我们还有其他字段 __op 、 __table 、 __source_ts_ms 和 __deleted 。这是因为我们在 application.properties 上有这些额外的配置。
debezium.source.transforms.unwrap.add.fields=op,table,source.ts_ms
有 Schema Definition将 MySQL CDC 集成到 BigQuery 中
我们已成功将没有Schema Definition的 MySQL CDC 流式传输到单列 BigQuery 表中。现在,让我们尝试使用模式,以便我们拥有一个具有与 MySQL 源表模式匹配的分隔字段的表格数据。
首先,让我们清理之前所作的工作。
Delete subscription
gcloud pubsub subscriptions delete mysql.inventory.products-bq-sub# Delete topic
gcloud pubsub topics delete mysql.inventory.products# Drop BigQuery table (Using SQL UI)
DROP TABLE <project_id>.<dataset>.mysql_inventory_products_no_schema;
创建一个新的 BigQuery 表。
CREATE OR REPLACE TABLE tibrahim_debezium.mysql_inventory_products (
id INT64 NOT NULL,
name STRING,
description STRING,
weight float64,
__op STRING,
__table STRING,
__source_ts_ms INT64,
__deleted STRING
);
接下来,让我们为 Pub/Sub 主题创建架构。该模式必须是与源表定义匹配的有效 AVRO 模式。
gcloud pubsub schemas create mysql.inventory.products-schema \
--type=AVRO \
--definition='{"type":"record","name":"MysqlInventoryProductsSchema","fields":[{"type":"int","optional":false,"name":"id"},{"type":"string","optional":false,"name":"name"},{"type":"string","optional":false,"name":"description"},{"type":"float","optional":false,"name":"weight"},{"type":"string","optional":true,"name":"__op"},{"type":"string","optional":true,"name":"__table"},{"type":"long","optional":true,"name":"__source_ts_ms"},{"type":"string","optional":true,"name":"__deleted"}]}'
现在,让我们使用该schema 创建 Pub/Sub 主题。
gcloud pubsub topics create mysql.inventory.products --message-encoding=json --schema=mysql.inventory.products-schema
现在,新的 BigQuery 订阅…带有schema
gcloud pubsub subscriptions create mysql.inventory.products-bq-sub \
--topic mysql.inventory.products \
--bigquery-table=$PROJECT_ID.$BQ_DATASET.mysql_inventory_products \
--use-topic-schema
哎,报错了。
ERROR: Failed to create subscription [projects/<PROJECT_ID>/subscriptions/mysql.inventory.products-bq-sub]: Incompatible schema type for field weight: DOUBLE vs. FLOAT.
ERROR: (gcloud.pubsub.subscriptions.create) Failed to create the following: [mysql.inventory.products-bq-sub].
BigQuery 订阅似乎存在与 float 数据类型相关的问题/错误。我在 Google Cloud 社区论坛上写了一篇关于此问题的帖子,看来我并不是唯一遇到此错误的人。
好吧,我对这个问题有点失望。但是,我们不要就此止步。我们将尝试使用另一个没有 float 列的表。让我们使用 addresses 表。
更改 Debezium 服务器 application.properties :
debezium.source.table.include.list=inventory.addresses
让我们为 addresses 表创建一个新的 BigQuery 表。
CREATE OR REPLACE TABLE <project_id>.<dataset>.mysql_inventory_addresses (
`id` int64 NOT NULL,
`customer_id` int NOT NULL,
`street` STRING NOT NULL,
`city` STRING NOT NULL,
`state` STRING NOT NULL,
`zip` STRING NOT NULL,
`type` STRING NOT NULL,
__op STRING,
__table STRING,
__source_ts_ms INT64,
__deleted STRING
);
接下来,创建 Pub/Sub 架构、主题、BigQuery 订阅并运行 Debezium Server。
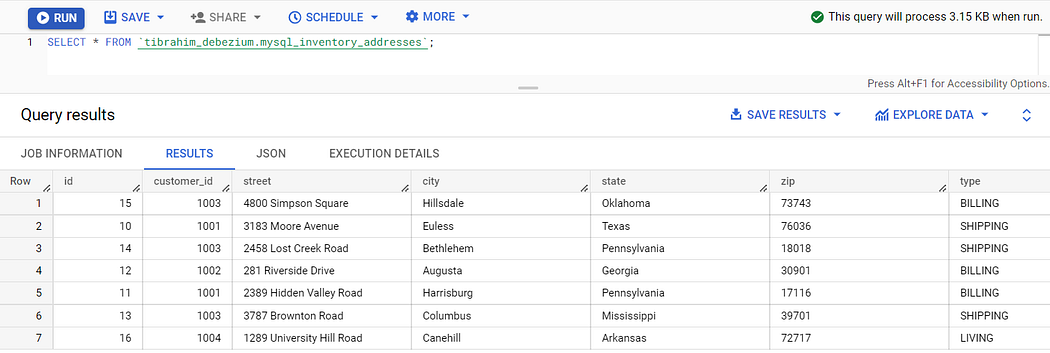
好了,这就是我们数据的漂亮的表格视图。
总结
借助 Debezium Server 和 Pub/Sub,无需 Kafka 和 Kafka Connect 即可运行变更数据捕获。随着 BigQuery 订阅功能的发布,无需 Cloud Dataflow 即可更轻松地直接流式传输到 BigQuery 表中。需要监控的资源更少,麻烦更少,成本更低。
然而,这种更简单的方法还带来了另一个问题:
-
Schema演变
目前,Schema 与 Topic 关联后,无法更新该 Schema。如果源表架构发生更改,则 CDC 流将失败。 Confluent Schema Registry或 Apicurio Schema Registry 已经解决了这个挑战。有一个关于此的 Google Issue Tracker。希望 Google Pub/Sub 团队能够在不久的将来解决这个问题。如果您的数据源经常发生架构更改,也许您最好坚持使用 Kafka 堆栈。
-
Topic and Destination Table Auto-Creation/Schema Auto-Evolution
主题和目标表自动创建/模式自动演化截至撰写本文时,我们需要在运行 Debezium 之前创建架构、主题、订阅和 BigQuery 表。如果您有数十或数百个表,那么您需要在创建、管理和销毁资源方面实现一些自动化。更成熟的框架(例如 Kafka Connect和开源 Kafka Connect BigQuery Sink)已经解决了这个问题。同样,如果您对此问题有疑问,那么也许您应该坚持使用 Kafka Connect 或其他成熟的框架。
如果您没有上述任何问题,那么此方法可能适合您。不管怎样,这个功能确实很棒。不仅用于更改数据捕获目的,您还可以将其用于很多用途,例如将 IoT 传感器数据直接发送到 BigQuery。或者捕获网络事件。可以任意发挥的地方很多。
参考文档:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!