【 FILIP】一种大规模细粒度交互式语言图像预训练方法
FILIP
Paper : Fine-grained Interactive Language-Image Pretrain
Author : Lewei Yao , Runhui Huang , Lu Hou1 , Guansong Lu , Minzhe Niu , Hang Xu , Xiaodan Liang , Zhenguo Li , Xin Jiang , Chunjing Xu
Affiliation : Huawei Noah’s Ark Lab , Hong Kong University of Science and Technology , Sun Y at-sen University
Code : Not open source
1 前言
作者引入了大规模细粒度交互式语言图像预训练(FILIP),通过跨模态后期交互机制实现更精细的对齐,该机制使用视觉token和文本token之间的token级别最大相似度指导对比学习的目标函数。 FILIP 通过仅修改对比损失,成功地利用了图像块和文本单词之间的细粒度表达能力,同时获得了在推理时离线预计算图像和文本表示的能力,保持了大规模训练和推理的效率。
作者构建了一个新的大规模图像文本对数据集 FILIP300M 进行预训练。实验表明,FILIP 在多个下游视觉语言任务(包括零样本图像分类和图像文本检索)上实现了最先进的性能。字token对齐的可视化进一步表明 FILIP 可以学习有意义的细粒度特征,并且具有良好的本地化能力。
1.1 动机
CLIP和 ALIGN等大规模视觉语言预训练(VLP)模型最近在各种下游任务中取得了成功。他们从互联网上收集的数百万个图像文本对中学习视觉和文本表示,并表现出卓越的零样本能力和鲁棒性。这些模型的核心技术在于通过双流模型对图像和文本进行全局对比对齐。这种架构对于检索等下游任务来说推理效率很高,因为两种模态的编码器可以解耦,并且可以离线预先计算图像或文本表示。然而,**CLIP 和 ALIGN 仅通过每种模态的全局特征的相似性来建模跨模态交互,缺乏捕获更精细级别的信息(例如视觉对象和文本单词之间的关系)的能力。**因此,作者为大规模 VLP 开发了一种简单而有效的跨模态细粒度交互机制。
1.2 相关工作
为了实现更细粒度的跨模态交互,先前的方法主要利用两种方法。
-
使用预训练对象检测器从图像中提取感兴趣区域(ROI)特征,然后通过 VLP 模型将其与配对文本融合。由于预先计算和存储了大量的 ROI 特征,这种设计使预训练变得复杂。此外,这些方法的零样本能力通常受到预定义类别数量的限制,并且它们的性能也受到检测器质量的限制。
-
将两种模态的 token-wise 或 patch-wise 表示强制到同一空间,并通过交叉注意力或自注意力对这些更细粒度的交互进行建模。然而,这些方法在训练和推理方面通常效率较低。特别是,在训练过程中,交叉注意力需要在编码器-解码器结构中执行,而自注意力的复杂度随着两种模态的序列长度增长而呈二次方增长。在推理过程中,来自两种模态的数据交织在一起以计算交叉注意力或自注意力,并且不能像 CLIP 和 ALIGN 等双流模型一样进行离线预先计算。对于图像/文本检索和图像分类等下游任务来说,这可能效率较低。
在本文中,作者提出了一种名为 FILIP 的大规模细粒度交互式语言图像预训练框架来解决这些限制。受 Khattab 和 Zaharia (2020) 的启发,作者通过对比损失中一种新颖的跨模态后期交互机制来建模细粒度语义对齐,而不是使用交叉或自注意力。具体来说,作者的细粒度对比学习使用视觉和文本token之间的token最大相似性来指导对比目标。通过这种方式,FILIP 成功地利用了图像块和文本单词之间更细粒度的表达能力,同时获得了离线预先计算图像和文本表示的能力。与 Khattab & Zaharia (2020) 不同,作者在计算图像-文本对齐时丢弃了填充的token,并使用平均值而不是token最大相似度的求和,这增强了跨模式表示学习并稳定了训练。此外,作者从互联网上构建了一个名为 FILIP300M 的大规模预训练数据集。这项工作还探索了数据清理和图像文本数据增强,并证明是有用的。
1.2.1 视觉语言预训练模型
预训练和微调方案在自然语言处理和计算机视觉领域取得了巨大成功。然后它自然地扩展到视觉和语言预训练(VLP)的联合跨模态领域。最近VLP模型的预训练数据集包括YFCC100M和CC12M等公开数据集,以及CLIP中超过1亿个样本的更大规模数据集和 ALIGN,事实证明它们更加强大。 VLP模型的预训练任务可以分为两类:图像文本对比学习任务和基于语言建模(LM)的任务:
-
CLIP、ALIGN和UNIMO 利用跨模态对比学习,将文本和视觉信息对齐到统一的语义空间;
-
VisualBERT 、UNITER 、M6 和 DALL-E采用类似 LM 的目标,包括两种掩码LM(例如,掩码语言/区域建模)和自回归 LM(例如,图像字幕、基于文本的图像生成)。另一方面,一些方法依赖于预训练的对象检测模型,例如 Faster-RCNN来离线提取图像区域特征,这需要额外的token边界框数据,并使该方法的可扩展性较差。 SOHO和 SimVLM等最近的努力尝试通过视觉词典或 PrefixLM消除这种负担。
在本文中,作者以端到端且更简单的方式直接学习细粒度的视觉语言表示,同时保持推理效率的优势。
1.2.2 多模态交互机制
视觉语言预训练模型的核心在于对两种模态之间的交互进行建模。跨模态交互架构主要有两种类型:
-
单流模型和双流模型。 VisualBERT和 ViLT等单流模型直接连接patch或区域视觉特征和文本嵌入,并将它们提供给基于 Transformer 的模型。
-
双流模型例如 ViLBERT 和 CLIP 对于不同的模态有单独的编码器。通过解耦编码器和离线预计算图像/文本特征的能力,可以针对不同的模态灵活使用不同的模型,并有效地推理图像文本检索等下游任务
在本文中,在遵循双流方法灵活高效的推理的同时,作者进一步提出了一种新的多模态交互机制来捕获细粒度表示。
2 方法
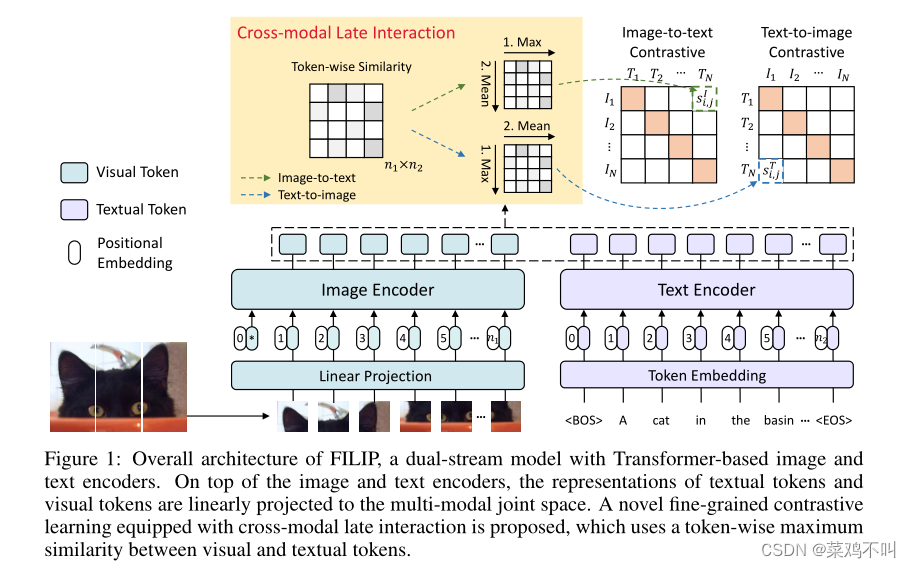
在本文中,作者提出了一种新的跨模态预训练模型,该模型擅长图像编码器和文本编码器之间的细粒度交互,用于挖掘更详细的语义对齐,称为 FILIP,如图 1 所示。具有基于 Transformer 的图像和文本编码器的双流模型。对于视觉模态,图像编码器是一个 Vision Transformer,它将一个额外的 [CLS] token嵌入和线性投影图像块串联作为输入。对于文本模态,按照使用词汇量为 49,408 的小写字节对编码(BPE)来标记文本。每个文本序列以 [BOS] token开始,以 [EOS] token结束。在词嵌入层之后,token嵌入被输入到经过修改的仅解码器 Transformer 模型中。在图像和文本编码器之上,文本token和视觉token的表示被线性投影到多模态公共空间,并分别进行 L2 归一化。与现有的双流模型(例如 CLIP 和 ALIGN)仅通过整个图像和文本序列的全局特征来建模跨模态交互不同,作者引入了一种配备跨模态后期交互的新颖的细粒度对比学习目标,它考虑了图像patches和文本tokens之间的细粒度交互
2.1 细粒度对比学习
最发现,在视觉和视觉语言跨模态预训练中,对比表征学习比预测性学习能学到更好的表征。在跨模态对比学习的一般公式下,想要学习图像数据
I
\mathcal I
I 的编码器
f
θ
f_θ
fθ? 和文本数据
T
\mathcal T
T 的
g
φ
g_φ
gφ? ,给定图像
x
I
∈
I
x^I ∈ \mathcal I
xI∈I和文本
x
T
∈
T
x^T ∈\mathcal T
xT∈T,在距离度量下,如果相关,则编码表示$ f_θ(x^I)$ 和
g
φ
(
x
T
)
g_φ(x^T )
gφ?(xT) 很接近,如果不相关,则相距很远。在每个训练批次中,作者采样b对图像-文本对
{
x
k
I
,
x
k
T
}
k
=
1
b
\{x_k^I,x_k^T\}_{k=1}^b
{xkI?,xkT?}k=1b? 。对于图像-文本对
{
x
k
I
,
x
k
T
}
\{x_k^I,x_k^T\}
{xkI?,xkT?}中的图像
x
k
I
x_k^I
xkI? ,
x
k
T
x_k^T
xkT? 是正样本,其余文本样本为负样本。
x
k
I
x_k^I
xkI?的图像到文本对比损失
L
k
I
\mathcal L^I_k
LkI?可以表示为
L
k
I
(
x
k
I
,
{
x
k
T
}
j
=
1
b
)
=
?
1
b
l
o
g
e
x
p
(
s
k
,
k
I
)
∑
j
e
x
p
(
s
k
,
j
I
)
\mathcal L^I_k(x_k^I,\{x_k^T\}^b_{j=1})=-\frac{1}{b}log\frac{exp(s_{k,k}^I)}{\sum_j exp(s_{k,j}^I)}
LkI?(xkI?,{xkT?}j=1b?)=?b1?log∑j?exp(sk,jI?)exp(sk,kI?)?
其中
s
k
,
j
I
s_{k,j}^I
sk,jI?表示第 k 个图像与第 j 个文本的相似度。类似地,
x
k
T
x^T_k
xkT? 的文本到图像对比损失为
L
k
T
(
x
k
T
,
{
x
k
T
}
j
=
1
b
)
=
?
1
b
l
o
g
e
x
p
(
s
k
,
k
T
)
∑
j
e
x
p
(
s
k
,
j
T
)
\mathcal L^T_k(x_k^T,\{x_k^T\}^b_{j=1})=-\frac{1}{b}log\frac{exp(s_{k,k}^T)}{\sum_j exp(s_{k,j}^T)}
LkT?(xkT?,{xkT?}j=1b?)=?b1?log∑j?exp(sk,jT?)exp(sk,kT?)?
该小批量的总损失可以表示为
L
=
1
2
∑
k
=
1
b
(
L
k
I
+
L
k
T
)
(
1
)
\mathcal L=\frac{1}{2}\overset{b}{ \underset{k=1}{\sum}}(L^I_k+L^T_k) \quad (1)
L=21?k=1∑?b?(LkI?+LkT?)(1)
2.1.1 跨模态后期交互
从对比损失 (1) 来看,跨模态交互反映在作者如何计算第 i 个图像和第 j 个文本的相似度$ s^I_{i,j} $和
s
i
,
j
T
s^T_{i,j}
si,jT? 上。以前的方法,如 CLIP 和 ALIGN 只是将每个图像或文本分别编码为全局特征,即$ f_θ(x^I_i ) ∈ \mathbb R^d$ 和
g
φ
(
x
j
T
)
∈
R
d
g_φ(x^T_j ) ∈ \mathbb R^d
gφ?(xjT?)∈Rd,并计算这些两个相似之处为
KaTeX parse error: Got function '\rm' with no arguments as superscript at position 39: … = f_θ(x^I_i )^\?r?m?{T}\it g_φ(x^T_…
忽略两种模态之间更细粒度的交互(例如,字patch对齐)。为了缓解这个问题,同时保持双流模型的训练和推理效率,作者应用跨模态后期交互来建模 token-wise 跨模态交互。
具体来说,将
n
1
n_1
n1? 和 $n_2 $分别表示为第 i 个图像和第 j 个文本的(未填充)token的数量,对应的编码特征为
f
θ
(
x
i
I
)
∈
R
n
1
×
d
f_θ(x^I_i ) \in \mathbb R^{n_1×d}
fθ?(xiI?)∈Rn1?×d 和
g
φ
(
x
j
T
)
∈
R
n
2
×
d
g_φ(x^T_j ) \in \mathbb R^{n_2×d}
gφ?(xjT?)∈Rn2?×d。对于第 k 个视觉token,作者计算其与
x
j
T
x^T_j
xjT? 的所有文本token的相似度,并使用最大的
m
a
x
0
≤
r
<
n
2
[
f
θ
(
x
i
I
)
]
k
T
[
g
φ
(
x
j
T
)
]
r
(
3
)
\underset{0\le r<n_2}{max}[f_θ(x^I_i )]^T_k [g_φ(x^T_j )]_r \quad(3)
0≤r<n2?max?[fθ?(xiI?)]kT?[gφ?(xjT?)]r?(3)
作为其token-wise的与
x
j
T
x^T_j
xjT? 的最大相似度。然后,作者使用在图像(或者文本)中所有非填充tokens的平均的token-wise的最大相似度作为图像到文本(或者文本到图像)的相似度。因此,第 i 个图像与第 j 个文本的相似度可以表示为:
s
i
,
j
I
(
x
i
I
,
x
j
T
)
=
1
n
1
∑
n
1
k
=
1
[
f
θ
(
x
i
I
)
]
k
T
[
g
φ
(
x
j
T
)
]
m
k
I
(
4
)
s^I_{i,j}(x^I_i , x^T_j ) = \frac{1} {n_1} \underset{k=1}{\overset{n_1} \sum} [f_θ(x^I_i )]_k^T [g_φ(x^T_j )]_{m^I_k} \quad (4)
si,jI?(xiI?,xjT?)=n1?1?k=1∑n1???[fθ?(xiI?)]kT?[gφ?(xjT?)]mkI??(4)
其中
m
k
I
=
a
r
g
m
a
x
0
≤
r
<
n
2
[
f
θ
(
x
i
I
)
]
k
T
[
g
φ
(
x
j
T
)
]
r
m^I_k = arg max_{0≤r<n_2}[f_θ(x^I_i )]_k^T [g_φ(x^T_j )]_r
mkI?=argmax0≤r<n2??[fθ?(xiI?)]kT?[gφ?(xjT?)]r?。类似地,第 j 个文本与第 i 个图像的相似度为
s
T
?
i
,
j
(
x
i
I
,
x
j
T
)
=
1
n
2
∑
n
2
k
=
1
[
f
θ
(
x
i
I
)
]
m
k
T
T
[
g
φ
(
x
j
T
)
]
k
(
5
)
s^T-{i,j}(x^I_i , x^T_j ) = \frac{1} {n_2} \underset{k=1}{\overset{n_2}\sum} [f_θ(x^I_i )] _{m^T_k}^T [g_φ(x^T_j )]_k\quad(5 )
sT?i,j(xiI?,xjT?)=n2?1?k=1∑n2???[fθ?(xiI?)]mkT?T?[gφ?(xjT?)]k?(5)
其中
m
k
T
=
a
r
g
m
a
x
0
≤
r
<
n
1
[
f
θ
(
x
i
I
)
]
r
T
[
g
φ
(
x
j
T
)
]
k
m^T_k = arg max_{0≤r<n_1}[f_θ(x^I_i )]_r^T [g_φ(x^T_j )]_k
mkT?=argmax0≤r<n1??[fθ?(xiI?)]rT?[gφ?(xjT?)]k?。注意,等式(4)中的
s
i
,
j
I
(
x
i
I
,
x
j
T
)
s^I_{i,j}(x^I_i , x^T_j )
si,jI?(xiI?,xjT?)不一定等于等式(5)中的
s
i
,
j
T
(
x
i
I
,
x
j
T
)
s^T_{i,j}(x^I_i , x^T_j )
si,jT?(xiI?,xjT?)。
备注 1 直观上,等式(3)中的token最大相似度意味着对于每个图像块,作者找到其最相似的文本token。类似地,对于每个文本token,作者还找到其最接近的图像块。通过将其应用于(4)和(5)中对比损失(1)的相似性计算,双流模型学习图像patch和文本token之间的细粒度对齐
原始的后期交互机制计算文档与用被掩码tokens填充的查询的相关性得分,作为token-wise最大相似度的总和,并通过成对 softmax 交叉熵损失进行优化。作者提出的跨模式后期交互在几个方面有所不同。首先,**作者在计算相似度时排除填充的文本token,因为它们会损害性能。**作者推测这是因为这些填充的tokens也会学习文本表示,并且会误导模型将图像patch与这些无意义的填充token对齐,而不是与有意义的非填充单词对齐。其次,**在计算相似度(4)和(5)时,作者使用token最大相似度的平均值而不是求和。**这是因为非填充token的数量因文本而异,并且所有非填充token的总和可能具有完全不同的大小,导致训练不太稳定且最终性能更差。第三,作者通过对比损失(1)优化后期交互机制,该损失被发现是强大的视觉语言预训练而不是的原始成对损失。
训练效率
尽管与原始损失相比,跨模态后期交互能够捕获更细粒度的特征,但它依赖于两种模态的 token-wise 表示,并且在通信、内存和计算方面可能效率低下,特别是当批处理尺寸很大。为了缓解这个问题,作者采用了多种方法。首先,作者将嵌入大小减少到 256。此外,作者在分布式学习设置中的节点通信之前将两种模态的最后一层特征的精度从 fp32 降低到 fp16,并在降低的精度下执行等式(4)和(5)中的乘法。此外,由于相似度计算的复杂性与文本token和图像patch的序列长度成比例,因此对于每个图像(或者文本),在节点通信之前作者从同一项工作中的所有的文本(或者图像)选择具有最高token-wise最大相似度得分的 25% tokens(等式(3) ),基于每个样本可以由一些最具代表性的token表示的直觉。
2.1.2 Prompt ensemble and templates
由于一词多义和与预训练过程不一致的问题,作者还使用提示模板来增强一些下游任务的原始标签。
为了可视化,为了简单起见,作者在整篇论文中仅使用一个提示模板,即“{标签}的照片”。对于其他实验,作者按照 CLIP的方法使用即时集成报告结果。当允许多个提示时,同一类标签的不同提示模板的token表示是不同的,并且不能汇总在一起以形成平均文本表示。因此,作者不是通过平均文本表示来集成不同的提示模板,而是通过它们的平均token相似性来集成它们。具体地,假设有C个提示模板,每个标签被扩充为C个不同的文本 x 1 T , x 2 T , ? ? ? , x C T x^T_1,x^T_2,···,x^T_C x1T?,x2T?,???,xCT?。图像 x I x^I xI 和该标签之间的相似度计算为$ \frac{1} {C} \sum ^C _{c=1} sI·,·(xI, x^T_c )$,其中 s I ? , ? s^I·,· sI?,? 在等式(4)中定义。
作者使用统一的基于规则的方法来构建图像分类任务的提示模板。具体来说,每个模板由四个部分组成:
[
前缀
]
{
标签
}
,
[
类别描述
]
.
[
后缀
]
.
(
6
)
[前缀]\{标签\},[类别描述]. [后缀]. \quad(6)
[前缀]{标签},[类别描述].[后缀].(6)
这里,“[前缀]”是上下文描述,如“a photo of a”,类似于 CLIP。 “label”是数据集的类别标签; “[类别描述]”描述了对某些细粒度图像分类数据集很有帮助的类别,例如数据集 Oxford-IIIT Pets 的“一种宠物”。一个有趣的发现是,在提示末尾添加包含参考词“it”(例如“I like it”)的后缀可以根据经验提高所提出模型的零样本分类性能。作者推测这是因为参考词“it”加强了细粒度的跨模式对齐,因为它也可以与目标对象的图像块对齐。
2.2 图像和文本增强
为了获得模型更好的泛化和数据效率,作者在预训练阶段对图像和文本进行数据增强,以构造更多的图像文本对。作者应用 AutoAugment(Krizhevsky 等人,2012;Sato 等人,2015;Cubuk 等人,2019;Hoffer 等人,2020)进行图像增强,遵循 SOTA 视觉识别方法。为了确保增强文本在语义上与原始文本相似,对于文本增强,作者使用反向翻译重写原始文本。具体来说,文本首先被翻译成目标语言,然后再翻译回源语言。作者选择德语和俄语作为目标语言,并为每个图像文本对获得额外的两个文本。在预训练期间构建一批图像文本对时,每个图像文本对的文本是从三个候选文本(即原始文本和两个反向翻译文本)中随机采样的。
2.3 预训练数据集
足够大的图文数据集是视觉语言预训练的前提。最近的 CLIP 和 ALIGN 分别构建了具有 400M 和 1800M 图像文本对的数据集。在这项工作中,作者还构建了一个名为 FILIP300M 的大规模数据集,它由 3 亿个图像文本对组成,涵盖了视觉和语言概念。具体来说,作者从互联网上收集图像-文本对,并应用以下基于图像和文本的过滤规则来清理数据。对于基于图像的过滤,作者删除尺寸小于200像素且长宽比大于3的图像。对于基于文本的过滤,作者只保留英文文本,并排除无意义的文本。作者还丢弃文本重复超过 10 次的图像-文本对。此外,作者还使用了3个公共数据集,包括Conceptual Captions 3M 、Conceptual 12M (CC12M) 和Y ahoo Flickr Creative Commons 100M (YFCC100M)。作者在 YFCC100M 上应用相同的过滤规则。最后,作者使用大约 340M 个图像文本对进行预训练。尽管使用比 CLIP 和 ALIGN 更小的训练数据集,作者的模型在大多数后续任务中仍然优于它们
3 实验
3.1 实验设置模型架构
3.1.1 模型架构
作者从头开始训练两个模型,即 F I L I P b a s e FILIP_{base} FILIPbase? 和 F I L I P l a r g e FILIP_{large} FILIPlarge?。模型架构遵循 CLIP,即 F I L I P b a s e FILIP_{base} FILIPbase? 的图像编码器为 ViT-B/32, F I L I P l a r g e FILIP_{large} FILIPlarge? 的图像编码器为 ViT-L/14。
3.1.2 预训练细节
**为了节省内存并扩大批量大小,使用自动混合精度和梯度检查点。**输入图像在训练期间被调整为224×224分辨率。根据 CLIP的规定,预训练和文本的最大长度限制为 77 个tokens。训练主要在Nvidia V100 GPU和Ascend卡上进行。 F I L I P b a s e FILIP_{base} FILIPbase? 在 128 张卡上训练大约需要 9 天, F I L I P l a r g e FILIP_{large} FILIPlarge? 在 192 张卡上训练大约需要 24 天。除非另有说明,作者使用 F I L I P l a r g e FILIP_{large} FILIPlarge? 与其他方法进行比较,并使用 F I L I P b a s e FILIP_{base} FILIPbase? 进行消融。作者使用 LAMB 优化器和余弦学习率计划和线性预热来训练这两个模型。权重衰减正则化使用于除偏差、层归一化、标记嵌入、位置嵌入和对比损失中的temperature之外的所有参数。
3.2 零样本图像分类
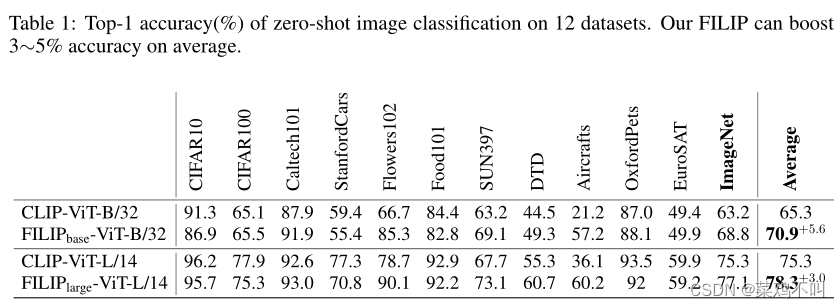
在本节中,作者在零样本图像分类任务上评估作者提出的 FILIP。作者使用与 CLIP 相同的评估设置,在 12 个下游分类数据集上将 FILIP 与 CLIP 进行比较。作者对每个数据集应用一组提示并将它们组合以获得最终结果。作者这里只比较零样本性能与 CLIP,因为 ALIGN 没有发布其模型,并且其论文中也没有报告相关性能。
表 1 显示了 12 个数据集的结果。尽管使用较少的训练数据(340M vs. M), F I L I P b a s e FILIP_{base} FILIPbase?和 F I L I P l a r g e FILIP_{large} FILIPlarge?在 12 个数据集的平均 top-1 准确率方面都远远优于其 CLIP 同行,即分别实现了 5.6% 和 3.0% 的绝对改进。特别是,作者的 FILIP 在 ImageNet 上超过了 CLIP。 FILIP 还在一些特定领域的数据集上实现了显着的性能提升,例如,对于飞机,两个 FILIP 模型比 CLIP 平均提高了 30%。作者推测这是因为,与将整个图像的信息聚合到 [CLS] token的表示中的 CLIP 不同,作者提出的 FILIP 模型通过直接将目标对象对应的图像patches与类标签对应的文本tokens对齐,更加关注目标对象
3.3 图文检索
图文检索由两个子任务组成:图像到文本检索和文本到图像检索。
作者在零样本和微调设置下,在两个检索基准数据集:Flickr30K和 MSCOCO上评估作者的 FILIP 模型。

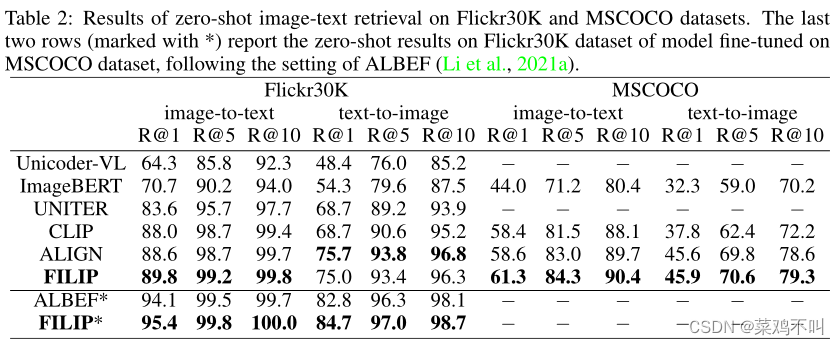
表 2 和表 3 分别显示了零样本和微调图像文本检索的结果。作者将作者的 FILIP 模型与具有复杂注意力层的方法进行比较,包括 Unicoder-VL、ImageBERT 、UNITER 、VILLA、 ERNIE-ViL 、Oscar、VinVL 、ALBEF 以及在更大规模图像文本数据集上训练的方法包括 CLIP和 ALIGN。正如作者所看到的,FILIP 在 Flickr30K 和 MSCOCO 数据集上的所有指标下都实现了最先进的性能,除了 Flickr30K 上的零样本文本到图像检索,其中 FILIP 实现了与 SOTA 竞争的性能。对于 MSCOCO 数据集上的零样本图像到文本检索,作者提出的 FILIP 的绝对 R@1 比 ALIGN 高 2.7%,后者是在更大的数据集上训练的。
3.4 消融实验
3.4.1 每个组件的有效性

作者研究了 FILIP 中每个组件的有效性,即图像/文本增强和跨模式后期交互。在 F I L I P b a s e FILIP_{base} FILIPbase? 上进行零样本检索和分类任务的实验,以 YFCC100M 的过滤子集作为训练数据集。
表 4 报告了结果。可以看出,所有三个组件对这两项任务都有好处。尽管设计简单,但跨模式后期交互相对于基线(普通 CLIP ViT-B/32)带来了显着的性能改进,图像到文本的绝对 R@1 增益为 5.5%(分别为 3.8%) MSCOCO 上的(分别是文本到图像)检索以及 ImageNet 上的零样本分类的绝对 top-1 准确度增益为 3.9%。当所有组件组合在一起时,可以观察到进一步的改进。
3.4.2 跨模态后期交互的效率研究

由于2.1.1节中的后期交互机制需要计算所有视觉和文本token之间的相似度,因此在大规模分布式训练中使用时,其效率可能会成为问题。如第 2.1.1 节所述,作者多次尝试解决该问题。表 5 显示了应用这些尝试时 ImageNet 上零样本分类的效率改进。
可以看出,这些尝试改善了后期交互效率而没有准确度下降。结合所有三种尝试,仅实现比 CLIP 中原始损失稍慢的训练和更大的内存消耗。
3.5 细粒度对齐的可视化
在本节中,作者将可视化 FILIP 使用字补丁对齐方法捕获细粒度跨模式对应的能力。为了进行公平比较,作者使用在 YFCC100M 上训练的 FILIPbase 和 CLIP 的 ViT-B/32(大小相同)进行可视化。每个图像被修补为 7×7 图像块。
3.5.1 可视化方法
word-patch对齐是基于图像patches和文本tokens之间的token-wise相似性来执行的。具体来说,对于第k个图像块,将与其相似度最大的文本token的位置索引(等式(4)中的 m k I m^I_k mkI?)视为其预测标签,并将其放置在其中心。以“balloon” 类为例。标记化文本序列“[BOS] a photo of a balloon. [EOS]”中有 8 个token。 类标签“balloon”的位置索引为“5”。请注意,一个类标签可以标记为多个token。与类标签相对应的文本tokens的位置索引以红色突出显示,而其他标记以白色标记。学习细粒度表示的理想模型会将目标对象的图像块预测为红色索引。
3.5.2 观察结果
图 2 显示了 FILIP 和 CLIP 在 ImageNet 数据集中的 4 个类上的word-patch对齐结果。可以看出,FILIP在以下几个方面表现出了对图像更细粒度的理解。
(i) 单个对象:从类 “small white butterfly”的可视化来看,覆盖该对象的图像块都被正确分类;
(ii) 不同形状的同一物体:从类“balloon”和 “lifeboat”的可视化中,与具有不同形状和位置的所有目标物体对应的图像块被正确分类;
(iii) 对象的关键组件:对于“electric locomotive”类,有两个对于正确分类图像至关重要的关键组件,即 “electric”和 “locomotive”,其对应的文本token索引为“5”和“6” “, 分别。可以看出,匹配这两个关键组件的图像块分别被正确分类。
另一方面,CLIP 无法正确地将图像patch与相应的文本token对齐。与 使用额外的最优传输来对齐文本单词和图像patch分布相比,作者的方法可以简单地自动学习单词补丁对齐。
4 结论和未来的工作
本文介绍了 FILIP,一个简单但通用的细粒度视觉语言预训练框架。通过使用token-wise最大相似度,作者的方法学习图像中的patches和句子中的单词的细粒度表示。虽然它在各种下游任务上与多个大规模多模态预训练相比取得了有竞争力的结果,但其架构和训练过程仍然可以优化以提高其性能。未来,可以使用更先进的图像编码器以及精心设计的交互层来提高性能。此外,作者可以进一步添加更多的屏蔽语言/图像损失来支持更多的生成任务。为此,作者希望将 FILIP 扩展为通用且统一的接口,用于解决各种视觉语言任务。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!