分布式理论基础:CAP定理
什么是CAP
CAP原则又称CAP定理,指的是在一个分布式系统中,Consistency(一致性)、 Availability(可用性)、Partition tolerance(分区容错性)这三个基本需求,最多只能同时满足其中的2个。
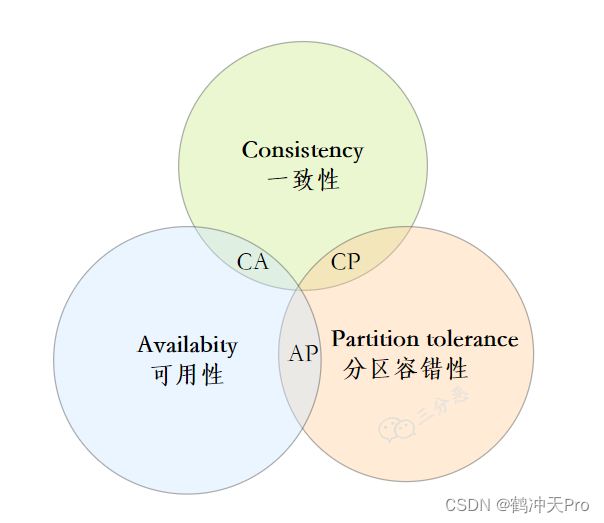
一致性 :数据在多个副本之间能够保持一致的特性。
可用性:系统提供的服务一直处于可用的状态,每次请求都能获得正确的响应。
分区容错性:分布式系统在遇到任何网络分区故障的时候,仍然能够对外提供满足一致性和可用性的服务。
什么是分区?
在分布式系统中,不同的节点分布在不同的子网络中,由于一些特殊的原因,这些子节点之间出现了网络不通的状态,但他们的内部子网络是正常的。从而导致了整个系统的环境被切分成了若干个孤立的区域,这就是分区。
为什么三者不可得兼
首先,我们得知道,分布式系统,是避免不了分区的,分区容错性是一定要满足的,我们看看在满足分区容错的基础上,能不能同时满足一致性和可用性?
假如现在有两个分区N1和N2,N1和N2分别有不同的分区存储D1和D2,以及不同的服务S1和S2。
- 在满足一致性 的时候,N1和N2的数据要求值一样的,D1=D2。
- 在满足可用性的时候,无论访问N1还是N2,都能获取及时的响应。
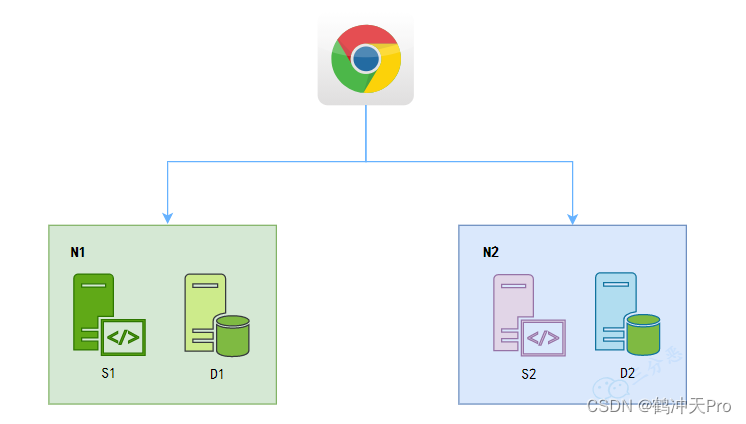
好的,现在有这样的场景:
-
用户访问了N1,修改了D1的数据。
-
用户再次访问,请求落在了N2。此时D1和D2的数据不一致。
接下来: -
保证一致性:此时D1和D2数据不一致,要保证一致性就不能返回不一致的数据,可用性无法保证。
-
保证可用性:立即响应,可用性得到了保证,但是此时响应的数据和D1不一致,一致性无法保证。
所以,可以看出,分区容错的前提下,一致性和可用性是矛盾的。
CAP原则权衡
CAP三者不可同得,那么必须得做一些权衡。
CA without P?
如果不要求P(不允许分区),则C(强一致性)和A(可用性)是可以保证的。但是对于分布式系统,分区是客观存在的,其实分布式系统理论上是不可选CA的。
CP without A
如果不要求A(可用),相当于每个请求都需要在Server之间强一致,而P(分区)会导致同步时间无限延长,如此CP也是可以保证的。很多传统的数据库分布式事务都属于这种模式。
AP wihtout C
要高可用并允许分区,则需放弃一致性。一旦分区发生,节点之间可能会失去联系,为了高可用,每个节点只能用本地数据提供服务,而这样会导致全局数据的不一致性。现在众多的NoSQL都属于此类。
CAP原则实际应用
我们应该都接触过微服务,常见的可以作为注册中心的组件有:ZooKeeper、Eureka、Nacos…。
- ZooKeeper 保证的是 CP
任何时刻对 ZooKeeper 的读请求都能得到一致性的结果,但是, ZooKeeper 不保证每次请求的可用性比如在 Leader 选举过程中或者半数以上的机器不可用的时候服务就是不可用的。 - Redis集群 保证AP
Redis通过AOF和RDB将数据同步到子节点。如果Master节点挂了,可以很迅速的将Slave提升为Master,尽可能的保证了系统的可用性,但是可能存在数据丢失的问题。所以Redis其实并不适合做分布式锁。 - Eureka 保证的则是 AP
Eureka 在设计的时候就是优先保证 A (可用性)。在 Eureka 中不存在什么 Leader 节点,每个节点都是一样的、平等的。因此 Eureka 不会像 ZooKeeper 那样出现选举过程中或者半数以上的机器不可用的时候服务就是不可用的情况。 Eureka 保证即使大部分节点挂掉也不会影响正常提供服务,只要有一个节点是可用的就行了。只不过这个节点上的数据可能并不是最新的。 - Nacos 不仅支持 CP 也支持 AP。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!