实验三 MapReduce编程
实验目的:
1.掌握MapReduce的基本编程流程;
2.掌握MapReduce序列化的使用;
实验内容:
一、在本地创建名为MapReduceTest的Maven工程,在pom.xml中引入相关依赖包,配置log4j.properties文件,搭建windwos开发环境。 编程实现以下内容:
(1)创建com.nefu.(xingming).maxcount包,编写wordcountMapper、Reducer、Driver三个类,实现统计每个学号的最高消费。
输入数据data.txt格式如下:
??????????序号 \t 学号?\t ?日期 ?\t ?消费总额
输出数据格式要求如下:
??????????学号 ?\t ?最高消费?
ZnMapper.java
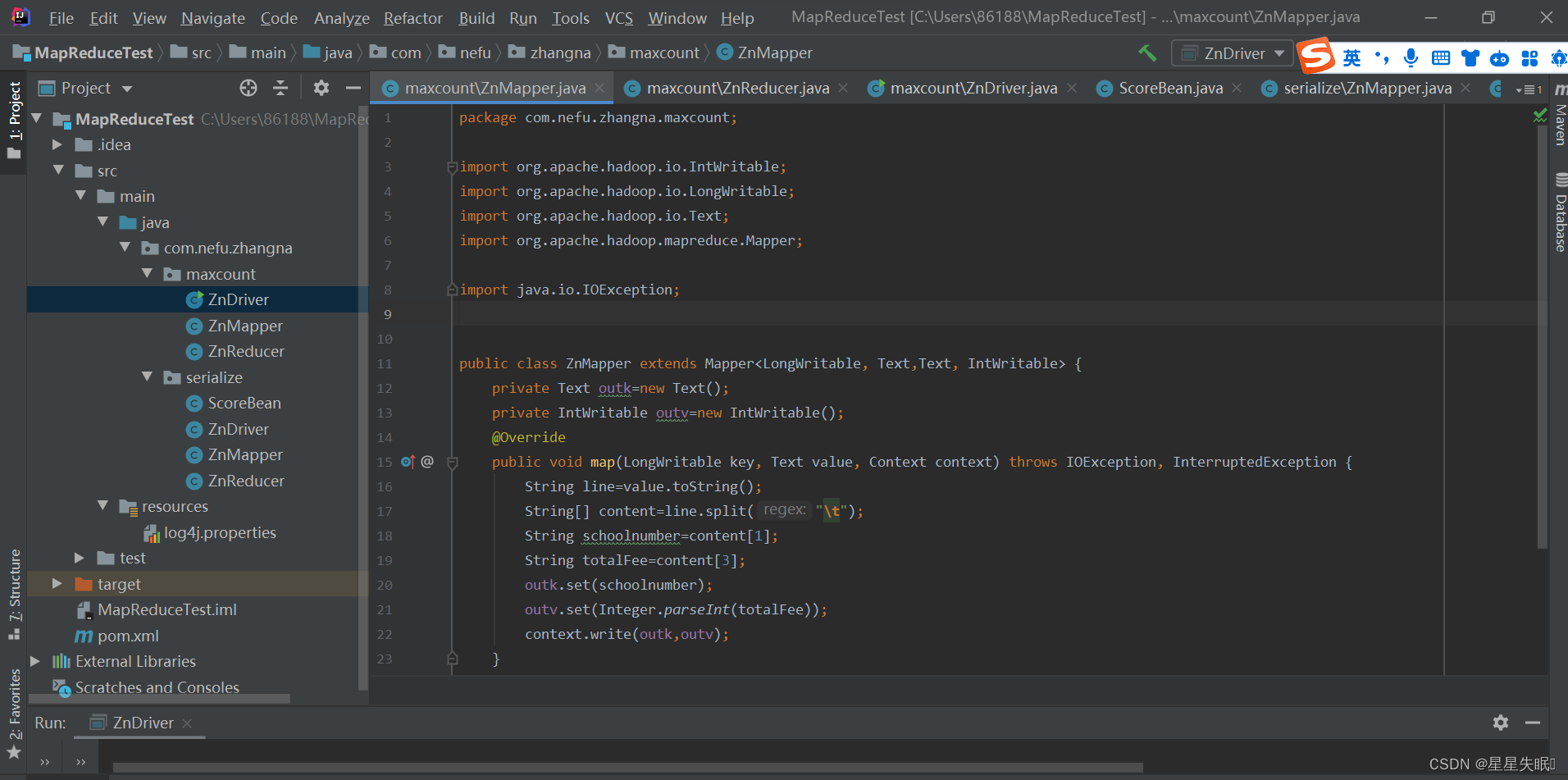
package com.nefu.zhangna.maxcount;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class ZnMapper extends Mapper<LongWritable, Text,Text, IntWritable> {
private Text outk=new Text();
private IntWritable outv=new IntWritable();
@Override
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line=value.toString();
String[] content=line.split("\t");
String schoolnumber=content[1];
String totalFee=content[3];
outk.set(schoolnumber);
outv.set(Integer.parseInt(totalFee));
context.write(outk,outv);
}
}
ZnReducer.java
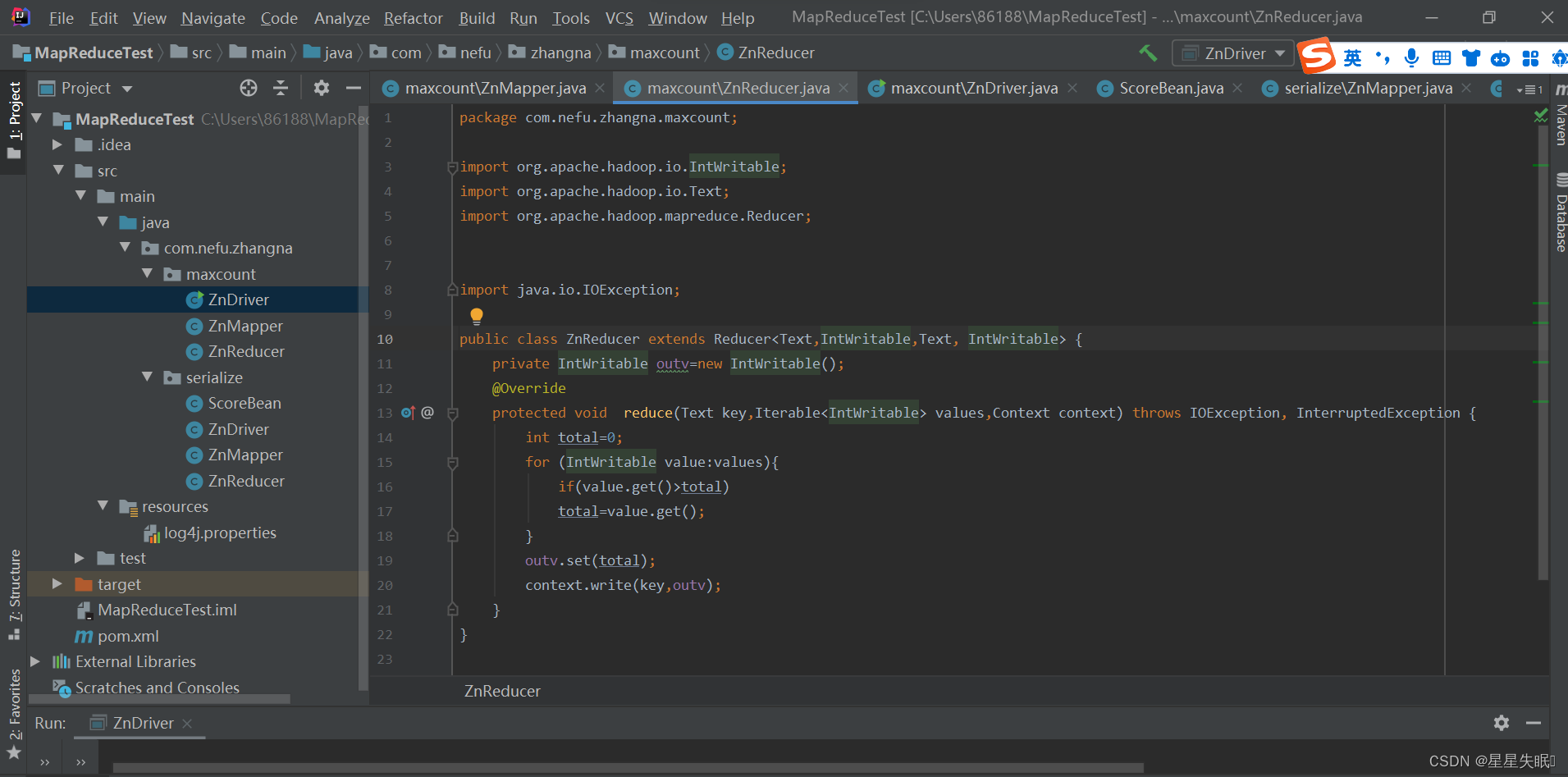
package com.nefu.zhangna.maxcount;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class ZnReducer extends Reducer<Text,IntWritable,Text, IntWritable> {
private IntWritable outv=new IntWritable();
@Override
protected void reduce(Text key,Iterable<IntWritable> values,Context context) throws IOException, InterruptedException {
int total=0;
for (IntWritable value:values){
if(value.get()>total)
total=value.get();
}
outv.set(total);
context.write(key,outv);
}
}
ZnDriver.java
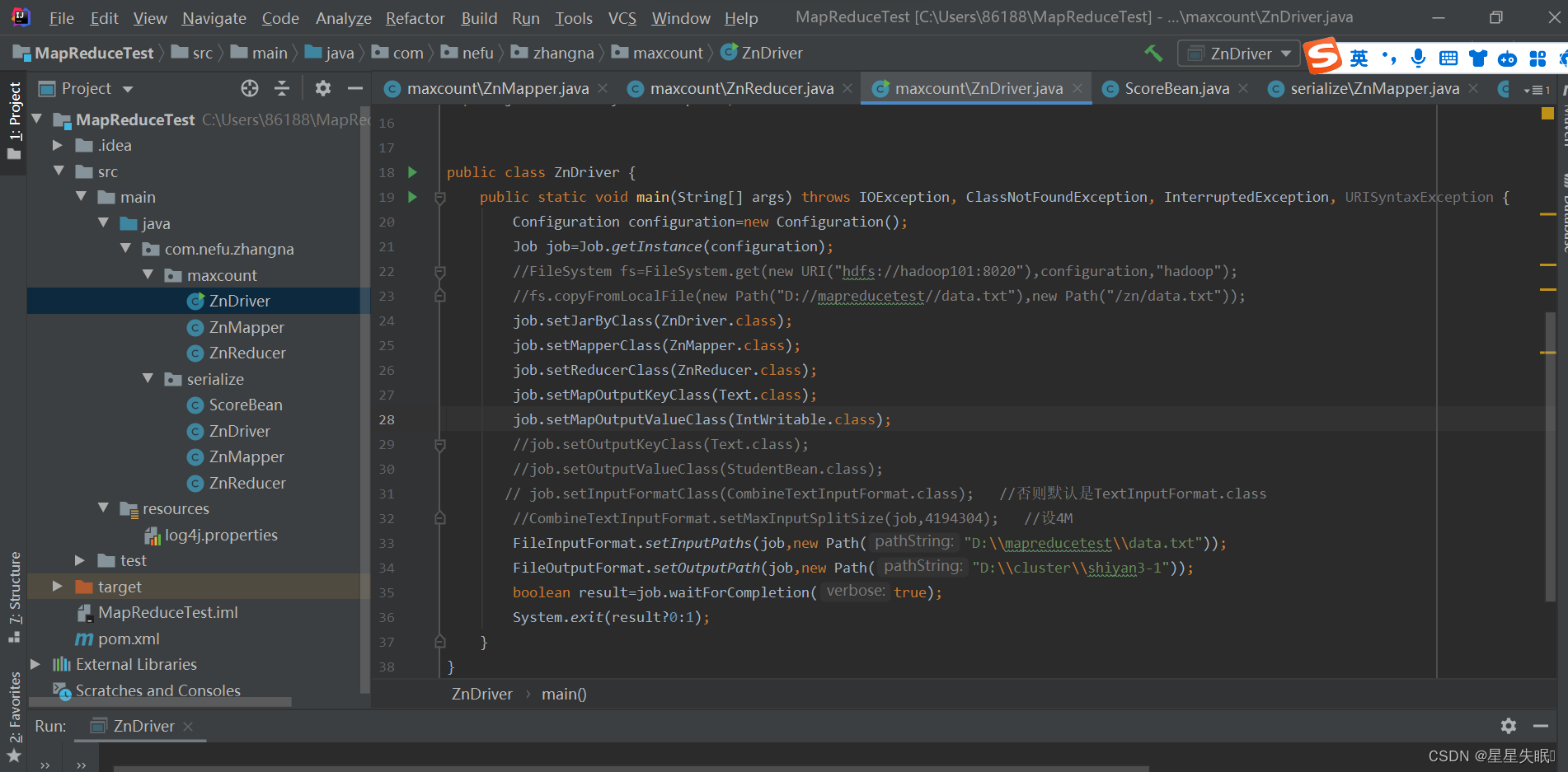
package com.nefu.zhangna.maxcount;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.CombineTextInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
public class ZnDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException, URISyntaxException {
Configuration configuration=new Configuration();
Job job=Job.getInstance(configuration);
//FileSystem fs=FileSystem.get(new URI("hdfs://hadoop101:8020"),configuration,"hadoop");
//fs.copyFromLocalFile(new Path("D://mapreducetest//data.txt"),new Path("/zn/data.txt"));
job.setJarByClass(ZnDriver.class);
job.setMapperClass(ZnMapper.class);
job.setReducerClass(ZnReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//job.setOutputKeyClass(Text.class);
//job.setOutputValueClass(StudentBean.class);
// job.setInputFormatClass(CombineTextInputFormat.class); //否则默认是TextInputFormat.class
//CombineTextInputFormat.setMaxInputSplitSize(job,4194304); //设4M
FileInputFormat.setInputPaths(job,new Path("D:\\mapreducetest\\data.txt"));
FileOutputFormat.setOutputPath(job,new Path("D:\\cluster\\shiyan3-1"));
boolean result=job.waitForCompletion(true);
System.exit(result?0:1);
}
}
(2)测试上述程序,查看运行结果
原数据
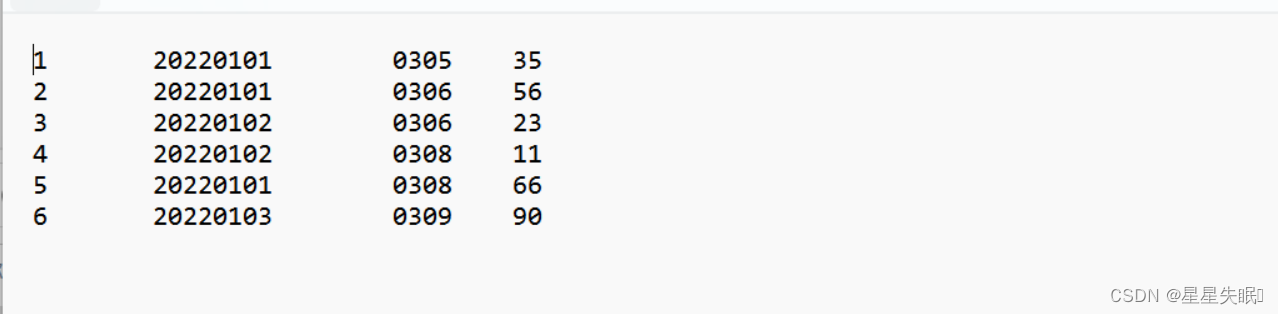
mapreduce之后

(3)查看日志,共有几个切片,几个MapTask(截图)
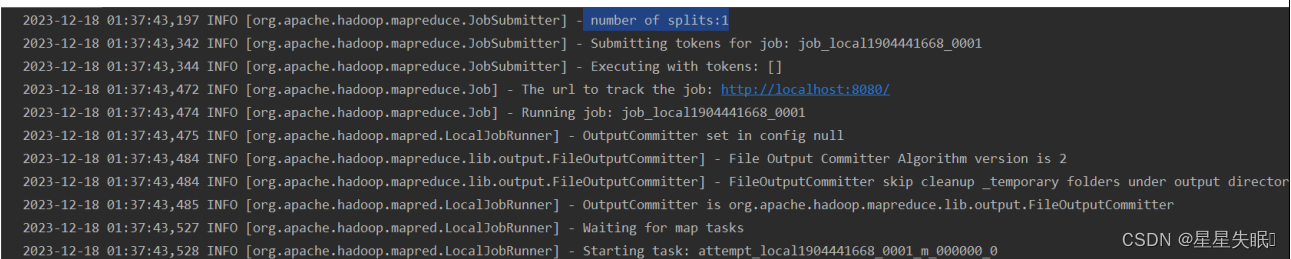
Number of split表示有一个切片,Starting task:?attempt_local649325949_0001_m_000000_0表示有一个Map Tast任务
(4)添加文件data1.txt,重新运行程序,共有几个切片,几个MapTask(截图)
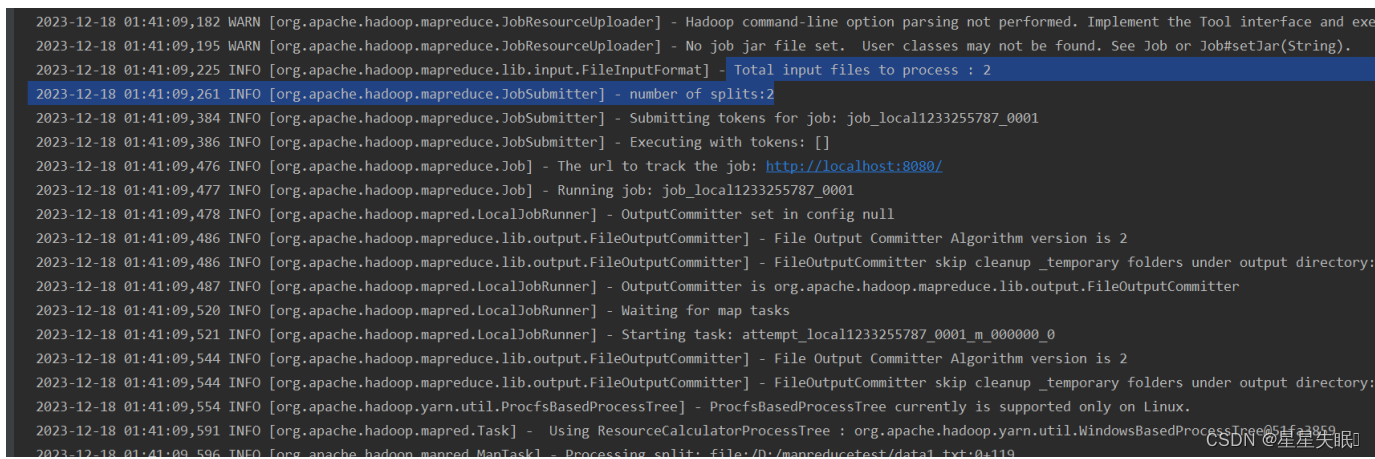
可见我输入了两个文件,切片的数目为2,也就有两个Map Text任务
(5)使用CombinTextInputFormat,让data.txt,data1.txt两个文件在一个切片中

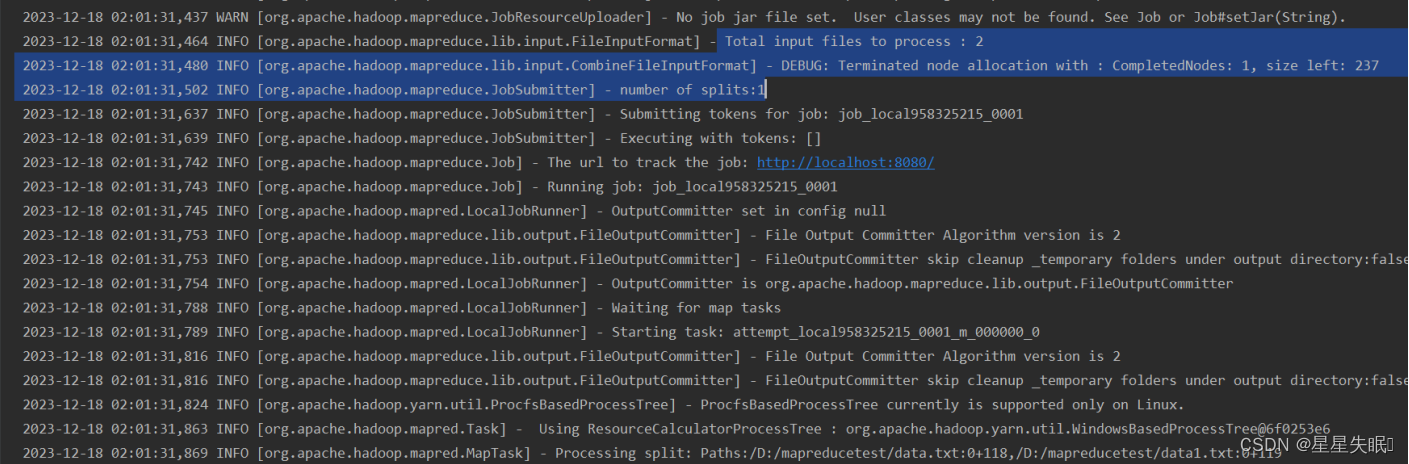
在驱动类中CombinTextInputFormat,可见只有一个切片
(6)将data.txt上传至HDFS

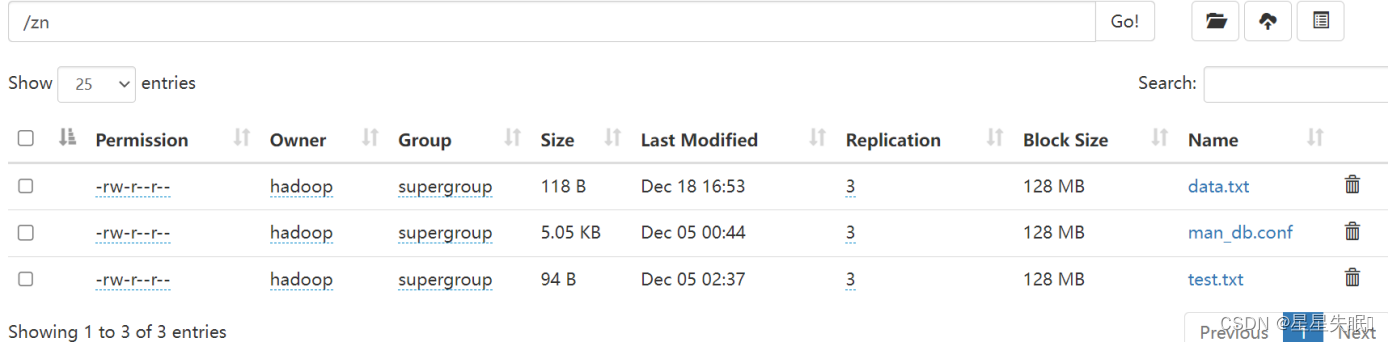

(7)使用maven将程序打成jar包并上传至hadoop集群运行,观察是否能正确运行。
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.6.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>将程序打成jar包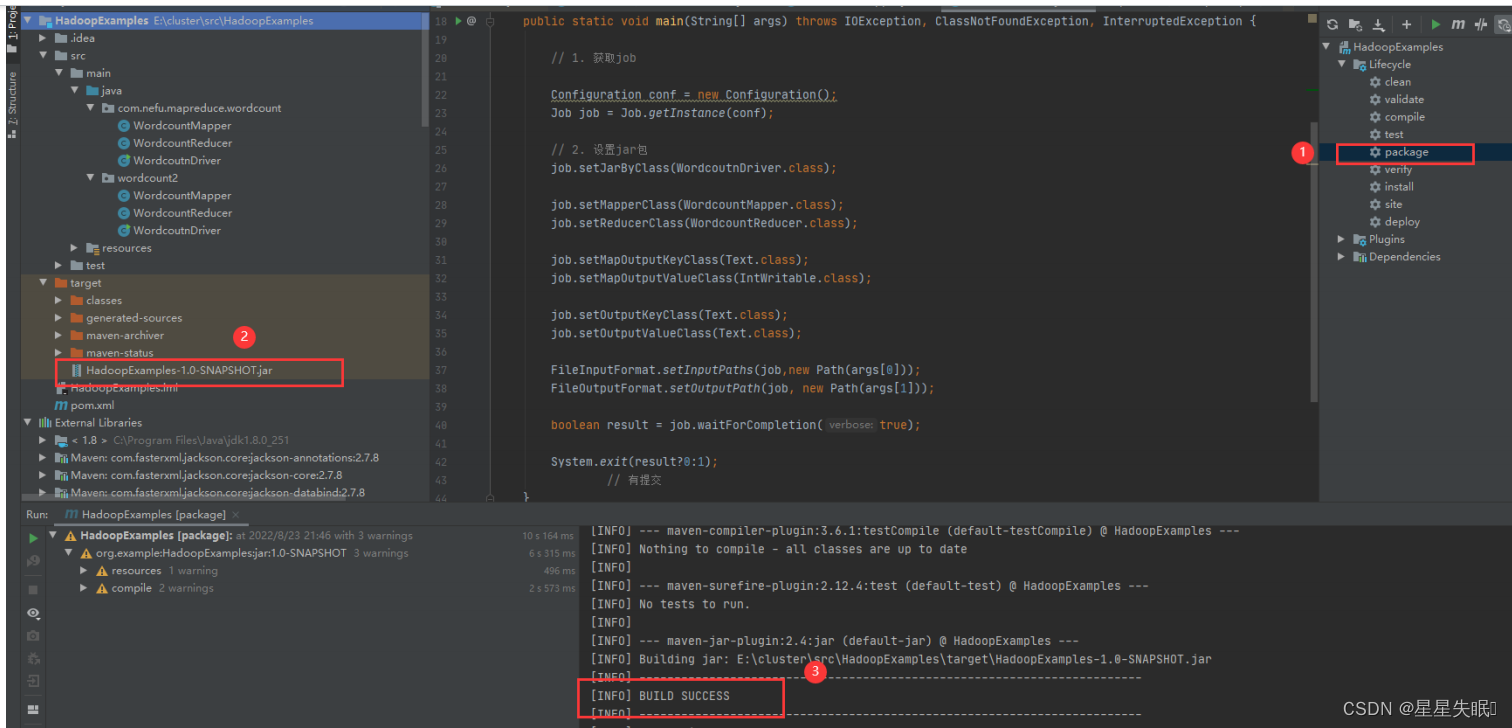
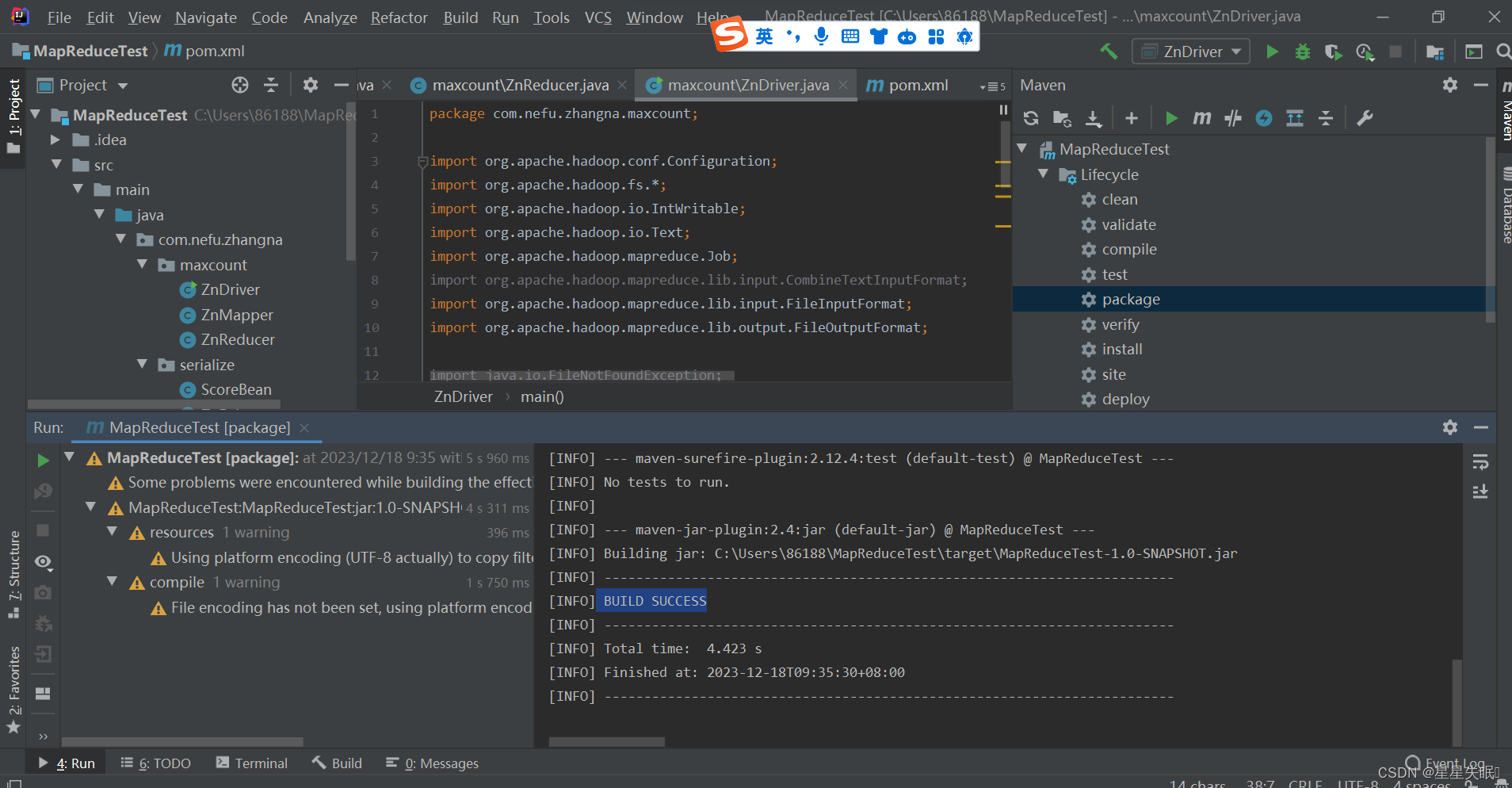

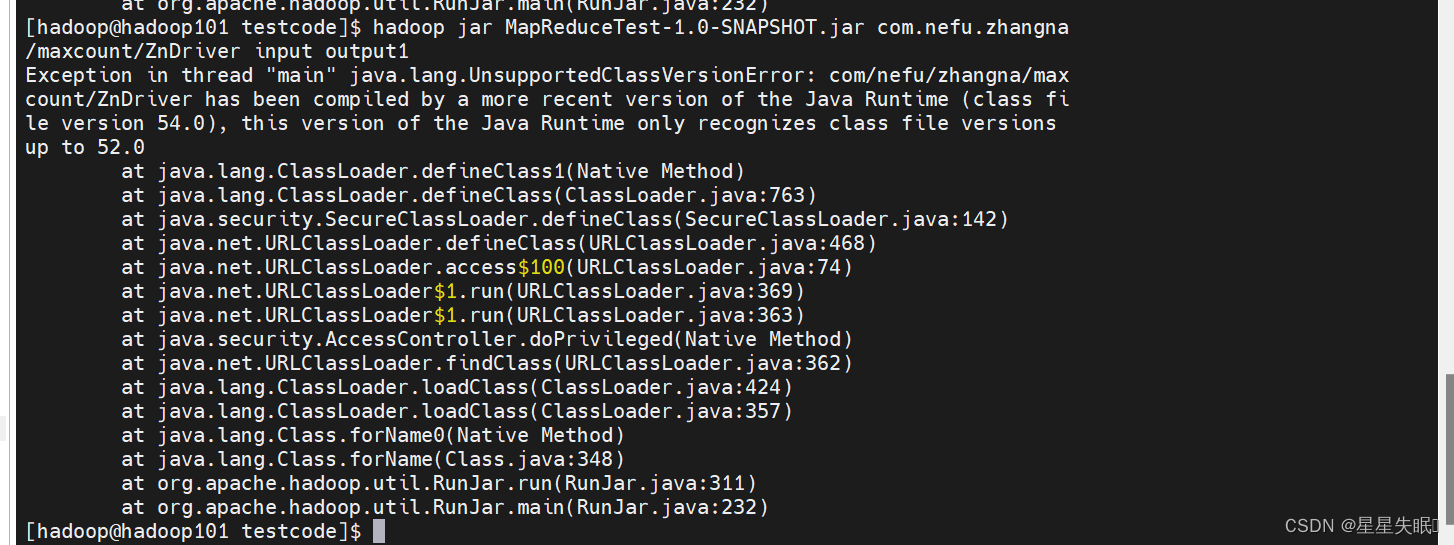
二、创建com.nefu.(xingming).serialize包,编写ScoreBean、Mapper、Reducer、Driver三个类,实现统计每个学号的平均成绩。并将结果按照年级分别写到三个文件中。
输入数据mydata.txt文件格式:
学号 ?\t ?姓名??\t ??成绩
输出数据格式(共3个文件):
学号 ??\t ?姓名??\t ??平均成绩
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!