谷歌推大语言模型VideoPoet:文本图片皆可生成视频和音频
Google Research最近发布了一款名为VideoPoet的大型语言模型(LLM),旨在解决当前视频生成领域的挑战。该领域近年来涌现出许多视频生成模型,但在生成连贯的大运动时仍存在瓶颈。现有领先模型要么生成较小的运动,要么在生成较大运动时出现明显的伪影。
VideoPoet的创新之处在于将语言模型应用于视频生成,支持多种任务,包括文本到视频、图像到视频、视频风格化、修复和修复以及视频到音频。与当前主流的扩散模型不同,VideoPoet将这些视频生成功能融合在一个大型语言模型中,而不是依赖于分别针对每个任务进行训练的组件。
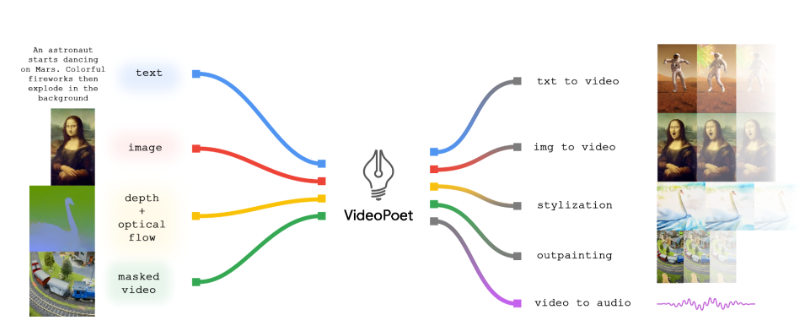
该模型通过多个分词器(MAGVIT V2用于视频和图像,SoundStream用于音频)进行训练,以学习跨视频、图像、音频和文本模态的知识。通过将模型生成的令牌转换为可视化表示,VideoPoet能够输出动画、风格化视频,甚至生成音频。模型支持文本输入,以指导文本到视频、图像到视频等任务的生成。
为了展示VideoPoet的多功能性,研究人员提供了一些生成示例。

文字生成视频
模型能够根据文本提示生成可变长度的视频,也可以将输入图像转化为动画视频。此外,模型还具备视频风格化的能力,通过输入光流和深度信息,以及一些额外的文本提示,生成独特风格的视频。最令人印象深刻的是,VideoPoet还可以生成音频,实现了从单一模型生成视频和音频的目标。

图像生成视频

视频风格化

可生成音频
研究人员指出,VideoPoet的训练方式使其具有生成较长视频的潜力,通过在上一个视频的最后1秒的基础上预测下一个1秒,可以实现视频的不断延伸。此外,模型还支持对已生成视频进行交互式编辑,用户可以改变物体的运动,实现不同的动作,从而具有高度的编辑控制。
评价结果
研究人员使用各种基准来评估 VideoPoet 在文本到视频生成方面的表现,以将结果与其他方法进行比较。为了确保中立的评估,我们在各种不同的提示下运行了所有模型,没有挑选示例,并要求人们对他们的偏好进行评分。下图以绿色突出显示了 VideoPoet 被选为以下问题的首选选项的时间百分比。
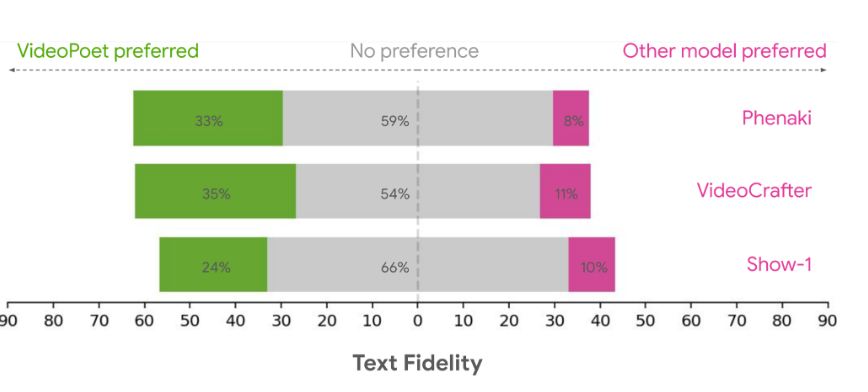
文本保真度
基于上述情况,平均而言,人们选择 VideoPoet 中24-35% 的示例作为比竞争模型更好的跟随提示,而竞争模型的这一比例为8-11%。评分者还更喜欢 VideoPoet 中41-54% 的示例,因为它们的动作更有趣,而其他模型的这一比例为11-21%。
VideoPoet作为大型语言模型,通过集成多种视频生成任务,为零镜头视频生成提供了新的可能性,为艺术创作、影视制作等领域带来了潜在的创新机遇。
官方博客:https://blog.research.google/2023/12/videopoet-large-language-model-for-zero.html
项目网址体验:https://top.aibase.com/tool/videopoet

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!